OS161 Assignment 4
Assignment4
In this assignment you will implement a few system calls that allow user programs to use files. This assignment will further train you how to navigate and understand a large and complex source base, and will teach you how to implement system calls and transfer control between the user mode and the kernel. You will implement part of the process management subsystem, which will be the subject of the next assignment.
Code reading exercises
- What are the ELF magic numbers?
The ELF (Executable and Linkable Format) magic numbers are a sequence of bytes (0x7f, 'E', 'L', 'F') at the beginning of an ELF file that identify it as an ELF file and provide some basic information about its format.
These magic numbers help operating systems and other tools quickly identify ELF files and determine their basic characteristics without having to parse the entire file structure.
- What is the difference between
UIO_USERISPACEandUIO_USERSPACE? When should one use UIO_SYSSPACE instead?
The enum uio_seg is typically used in Unix-like operating systems to specify the memory segment for I/O operations.
1 | |
UIO_USERISPACE(User process instruction space) refers to the memory segment where the user process's executable code (instructions) resides.
UIO_USERSPACE(User process data space) refers to the memory segment where the user process's data resides.
UIO_SYSSPACE is used when the memory being accessed is in kernel space rather than user space. It is typically used within kernel code or drivers when performing I/O operations on kernel-owned memory.
- Why can the struct
uiothat is used to read in a segment be allocated on the stack inload_segment()(i.e., where does the memory read actually go)?
The uio structure describes an I/O operation that will read data from the file (vnode v) into the user's address space at vaddr.
The struct uio is allocated on the stack in the load_segment() function. This is fine because the structure is just used to describe the I/O operation, not to hold the actual data being read. The actual read operation (VOP_READ) will use this information to copy the data directly into the user's address space.
The key is in this line:
1 | |
Here, vaddr is the virtual address in the user's address space where the segment should be loaded.
- In
runprogram(), why is it important to callvfs_close()before going to user mode?
Once the program is loaded, there's no need for the kernel to maintain access to the executable file. Closing the file before going to user mode ensures that the new user process doesn't have unnecessary open file handles.
- What function forces the processor to switch into user mode? Is this function machine dependent?
The function that forces the processor to switch into user mode is: mips_usermode(), which calls asm_usermode().
This function is machine dependent. Specifically, it's designed for the MIPS architecture.
- In what file are
copyinandcopyoutdefined?memmove? Why can'tcopyinandcopyoutbe implemented as simply asmemmove?
copyin and copyout are defined in ~/src/kern/vm/copyinout.c
memmove is defined in ~/src/common/libc/string/memmove.c
The copyin and copyout functions cannot be implemented as simply as memmove because they involve copying data between user space and kernel space, which introduces security and reliability concerns that memmove doesn't have to deal with.
There's a copycheck function call at the beginning of both copyin and copyout because the kernel must verify that the user-provided addresses are valid and within the user's accessible memory range.
The complexity in copyin and copyout comes from setting up safeguards (like tm_badfaultfunc and setjmp) to catch and handle potential faults, performing necessary checks, and ensuring the operation is secure and doesn't compromise the system's integrity.
In contrast, memmove operates entirely within a single memory space (either all kernel or all user space) and can assume that all addresses it's working with are valid and accessible, which allows for a much simpler implementation.
- What (briefly) is the purpose of
userptr_t?
The purpose of userptr_t is to create a distinct pointer type for user-space addresses that cannot be accidentally confused or mixed with kernel-space pointers. It serves as a safeguard in the kernel code to clearly differentiate and safely handle pointers to user-space memory.
- What is the numerical value of the exception code for a MIPS system call?
The exception code for a MIPS system call is 8.
- How many bytes is an instruction in MIPS?
By examining the syscall(struct trapframe *tf) function, we can determine that each MIPS instruction is 4 bytes. This is evident from the following code snippet:
1 | |
The line tf->tf_epc += 4; increments the program counter by 4, indicating that each instruction in MIPS occupies 4 bytes.
- Why do you "probably want to change" the implementation of
kill_curthread()?
Since this function handles fatal faults in user-level code by calling panic(), which will crash the entire system. For a single user-level fault, we don't need to crash the entire kernel or system. We can simply signal the parent and clean up the process.
- What would be required to implement a system call that took more than 4 arguments?
To implement a system call with more than 4 arguments, the following steps would be necessary:
-
Pass the first 4 arguments in registers
a0-a3. -
Fetch the remaining arguments from the user stack: For arguments beyond the 4th, we need to get them from the user stack, in detail, fetching from
sp+16to skip over the space reserved for the first 4 registerized arguments. (We need use thecopyin()function to safely retrieve these arguments from the user space into the kernel space. )
- What is the purpose of the SYSCALL macro?
The main purpose of the SYSCALL macro is to simplify the definition and handling of system calls, ensuring that each system call is properly numbered and recognized by the kernel.
-
Generate Assembly Code for System Calls: It generates the necessary assembly code to load the system call number into the appropriate register and call the generic
__syscallhandler. -
Simplify the Registration Process: By using the
SYSCALLmacro, developers don't have to manually write the assembly code for each system call. The script (gensyscalls.sh) parses this file and generates the required assembly stubs, making the system calls automatically recognizable and executable by the kernel.
- What is the MIPS instruction that actually triggers a system call?
The instruction that actually triggers a system call is:
syscall
After reading syscalls-mips.S and syscall.c, you should be prepared to answer the following question:
OS/161 supports 64-bit values;
lseek()takes and returns a 64-bit offset value. Thus, lseek() takes a 32-bit file handle (arg0), a 64-bit offset (arg1), a 32-bit whence (arg2), and needs to return a 64-bit offset value. Invoid syscall(struct trapframe *tf)where will you find each of the three arguments (in which registers) and how will you return the 64-bit offset?
- arg0 (file handle, 32-bit) is found in the
a0register. - arg1 (offset, 64-bit):
- Lower 32 bits are stored in
a2. - Upper 32 bits are stored in
a3. - If registers are insufficient, additional arguments can be fetched from the user stack, starting at
sp+16for the lower 32 bits andsp+20for the upper 32 bits.
- Lower 32 bits are stored in
- arg2 (whence, 32-bit) is found on the user stack at
sp+16.
To return the 64-bit offset value:
v0holds the lower 32 bits of the return value.v1holds the upper 32 bits of the return value.
- As you were reading the code in
runprogram.candloadelf.c, you probably noticed how the kernel manipulates the files. Which kernel function is called to open a file? Which macro is called to read the file? What about to write a file? Which data structure is used in the kernel to represent an open file?
Kernel function to open a file:
The kernel function to open a file is vfs_open(). In runprogram(), the file is opened with the call vfs_open(progname, O_RDONLY, 0, &v);, where O_RDONLY specifies read-only mode.
Macro to read a file:
The macro to read a file is VOP_READ(). In loadelf.c, it is used in load_segment() with the call VOP_READ(v, &u); to read data from the file.
Macro to write a file:
Although not explicitly used in the provided code, the macro to write a file is VOP_WRITE(), which functions similarly to VOP_READ() but for writing.
Data structure representing an open file in the kernel:
The kernel uses the struct vnode data structure to represent an open file. In runprogram.c, a vnode represents the opened program file, stored in the variable v.
- What is the purpose of VOP_INCREF and VOP_DECREF?
VOP_INCREF: Increases the reference count of a file (or vnode) to indicate that it is in use. This prevents the file from being released while it is still being accessed.
VOP_DECREF: Decreases the reference count of a file. When the count reaches zero, it indicates that the file is no longer in use, allowing the kernel to safely release its resources.
Design and implementation
The system calls you need to implement in this assignment are:
open(), read(), write(), lseek(), close(), dup2(), chdir(), and __getcwd()
How to begin:
- Take a look at
kern/test/fstest.cto learn about the functions available in the kernel for manipulating files. Another place to look for useful function is in thekern/vfsdirectory. These functions will be very helpful to you when implementing the solution to this assignment.- Carefully study
kern/arch/mips/syscall/syscall.c. Look at the existing system calls as well as the comments at the top of this file. They will tell you exactly how to pass the arguments in and out of the system calls.
Things become even more complicated in Assignment 5, where you'll need to implement
fork(), which dictates that the file objects be shared between the parent and child processes; since these can run concurrently, you will need some careful synchronization! Though you don't need to worry about this for the current assignment, designing your file-tracking system with Assignment 5 in mind might make your life easier later.
That is to say, different processes that run concurrently may share the same file handle. Besides, although in this assignment we assume each process only has one thread, it is strongly recommended that we take multi-threaded processes into account in order to make our code more robust.
Important: Before sitting down to write code, get together with your partner and write down the following for every system call:
- the arguments it takes
- the return values it might return
- the errors it must check for
- the information it needs to access and update inside the file table
- the functions and macros available in os161 that you can use for its implementation
- the potential race conditions and how they must be prevented (assume no user-level threads for this assignment).
For now, make the menu thread go away by having it block on some semaphore or run an infinite while loop after it launches the user program.
My Solution
Task: Implement
open(), read(), write(), lseek(), close(), dup2(), chdir(), and __getcwd()system calls.
Kernel structure for open files
All the system calls that we implemented here are interact with files. So we first need to implement the OS/161 kernel structure for managing open files, including the file descriptor table and file handles.
Details of OS/161 kernel structure for open files are shown below:
Kernel three-table data structure for open files:
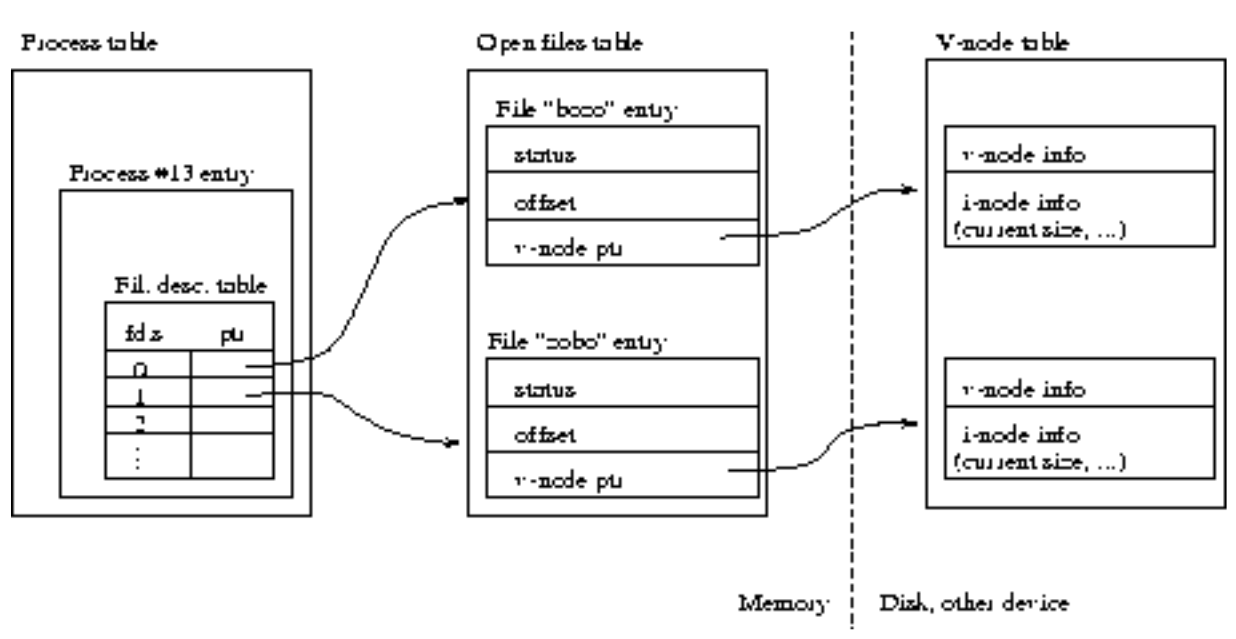
- Table1: Process table
Each process entry in the process table contains a file description table(a table of open file descriptors).
- Table2: Open file table
The file descriptors index the entries in the file description table. Each entry contains a pointer to an entry in the open files table(a table that the kernel maintains for all open files).
Each entry in this open files table contains the file status flags (read, write, append, etc.), the current file offset, and a pointer to the entry for this file in the so-called v-node table.
- Table3: V-node table
The v-node table (or part of it) is stored on the physical device. For now, you can think of its entries as the "real'' file contents on a disk, with associated informations like file location on disk, size, name, owner, etc.
What if two processes want to independently open the same physical file, i.e. with each process maintaining its own access mode (read, write or append) and file offset as well?
Here the open files table has two independent entries for the same file, each associated to one of the processes.
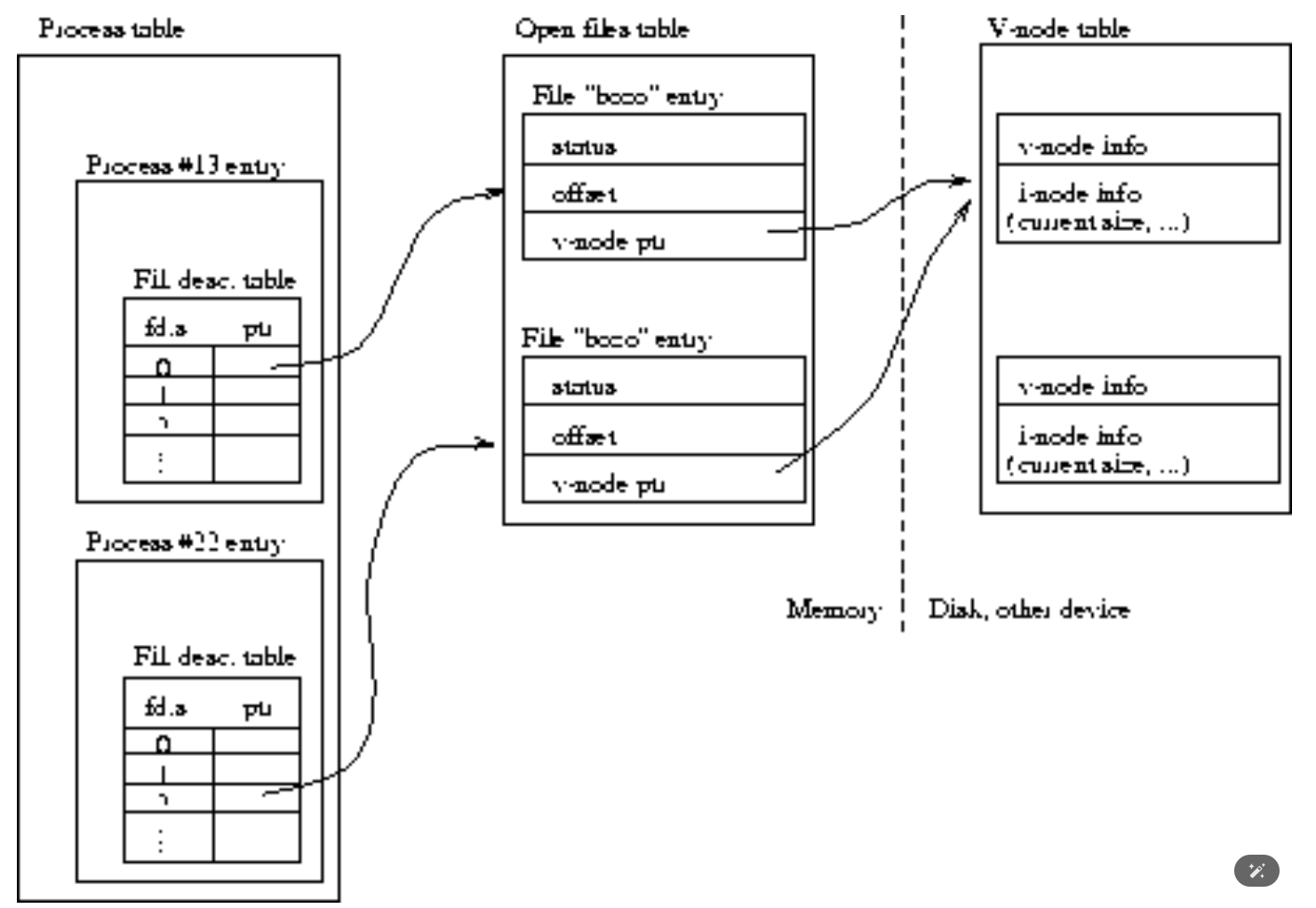
What if we need to have in one process two file descriptors opened for the same file?
Duplication of file descriptors:
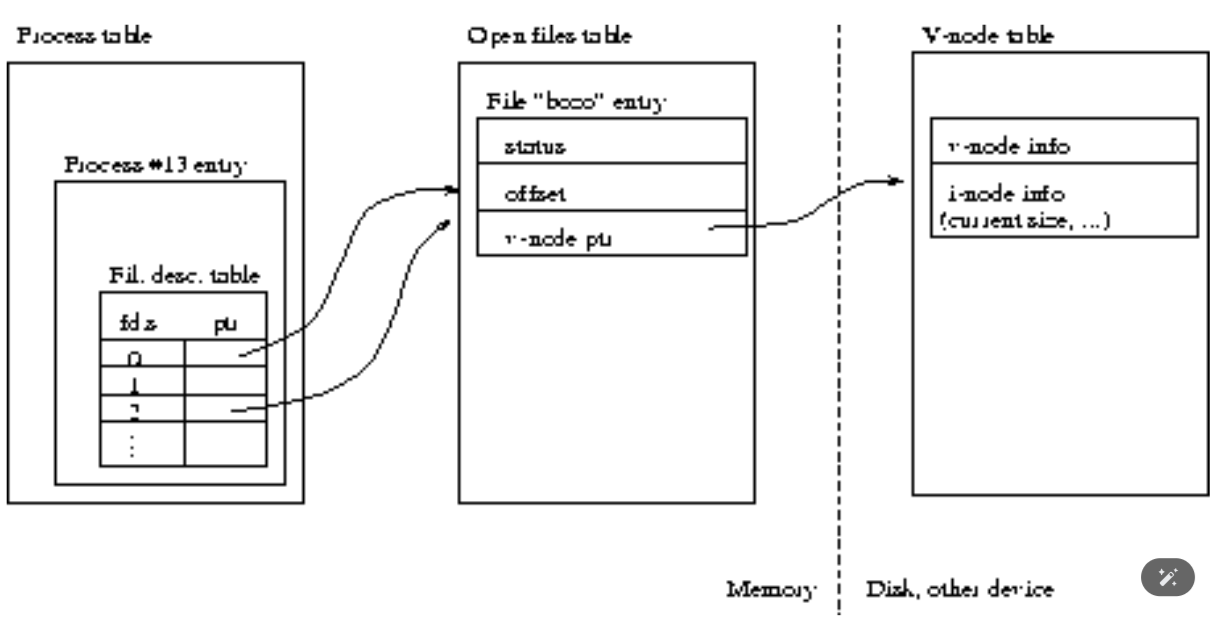
How we achieve this?
The dup() and dup2() system calls do this job.
1 | |
Why we need the duplication of file descriptors?
Example:
1 | |
By duplicating datafd to stdin, we ensure sed can read from our desired file.
What is the problem of
dup()? How we solve this?
The close-and-duplicate sequence above is not atomic. We can fix this with dup2:
1 | |
Take time to fully understand the contents above before implementing your file descriptor table and file handle structures.
1 | |
Notice that although in this lab we assume each process only has one thread, adding a lock to the file descriptor table makes our code more robust.
Besides implementing the actual file table and file handle structure, we also need to implement some functions with which the system calls can perform operations on the file system.
Think about what those functions are needed? Also within those functions, what kinds of synchronization do we need?
You can first write some functions that come to mind after you finish implementing the file table and file handle structure, and gradually add more functions while trying to implement the file-related system calls.
Here I show all the functions I need to operate on the file tables and file handles:
1 | |
1 | |
After implementing the file descriptor table and functions to operate on it, we need to add the filetable to the proc structure, create the file descriptor table during process creation and clean the file descriptor table during process destruction.
Notice that in OS/161, there are two ways to create a process:
By
forksystem callwe will implement the
proc_create_forkfunction in the next assignment. Since the child process share the same file descriptor table with the parent process, we just need to copy the entirefiletableto the new process. That is why we need afiletable_copyfunction.By
proc_create_runprogramThis function is used to create the first user process for the new program to run in. Since this is the first user process created, we need to initialize the standard I/O in its file descriptor table. Therefore, we need to call
filetable_stdio_initinproc_create_runprogram.
Notice that in either way, we first need to call the proc_create function to create a initial proc structure.
System calls (From system call API to Disk)
Have the kernel structure for managing open files at hand, now it's time to write some file-related system calls!
Things to think about before coding:
What functions can we use to help us implementing those system calls?
Focus on functions that are responsible for VOP operations(operate on vnode) and VFS layer operations(translate operations on abstract on-disk files to operations on specific filesystems).
What kind of synchronizations do we need to implement in the kernel for those system calls?
Notice that for this assignment, we assume each process has only one thread. However, different processes may share the same file handle and can run concurrently.
What kinds of errors should each system call return?
Read the OS/161 system calls man page carefully and look up the error types in errno.h.
sys_open
How to copy the
filenamestring from user space into kernel space.
Use the copyinstr function to copy the filename from user space to kernel space.
What function is used to actually open the file?
We need to use the vfs functions to interact with vnode. Once we have the vnode, we can create the file handle that points to the vnode and add the file handle to the current process's file descriptor table.
1 | |
sys_close
What functions in
filetablecan we use to close a file? How can we implement that function infiletable?
We need to use the vfs_close to decrement the refcount in vnode.
We also need to decrease the refcount of filehandle and remove filehandle from filetable.
1 | |
sys_read and sys_write
Those two system calls' implementations are very similar.
What synchronization problems can we face in the
read/writesystem calls?
Imagine two processes using the same file handle reading/writing from/to the same file concurrently. Therefore, we need to lock the file handle while reading as well as writing.
To mention it again, although in this lab we assume each process only has one thread, it is strongly recommended that we lock the file descriptor table while we are trying to get the file handle to make our code more robust.
What structures and functions should we use to actually read/write from/to a file.
We read/write from/to a vnode, so we should use VOP operation to read/write from/to a vnode.
Since vnode is the abstract representation of the file on disk, we also need some kind of I/O structure to describe the I/O operation(read/write).
That is the uio structure! Just to clarify, the uio structure is used just to describe the I/O operation, not to hold the actual data to be transferred. The VOP I/O operation use this information to transfer data directly from/to the disk.
1 | |
1 | |
sys_lseek
Check the man page to understand how to calculate the new file offset given the parameter whence.
What synchronization problems can we face in the
lseeksystem call?
Like read/write, imagine two processes using the same file handle seeking to different locations. We need to lock the file handle while seeking. Like mentioned before, it is strongly recommended that we also lock the file descriptor table while trying to get the file handle to support multi-threaded processes, making our code more robust.
How to check if the file supports seeking and how to know the size of the file?
Those all interact with vnode, so we need to use VOP operations.
When implementing sys_lseek, pay close attention to where you can find its parameters and how to pass its return value. If you are confused, review the coding reading exercises Q14.
1 | |
sys_dup2
The dup process is really simple. We just make the newfd point to the same file handle as the oldfd and increase the filehandle refcount.
What synchronization problems can we face in the
dup2system call?
dup2 operates on file descriptors. Since each process has its own file descriptor table, we won't need to worry about synchronization problems between processes. However, to make our code more robust, it is strongly recommended that we take multi-threaded processes into account.
Imagine two threads within the same process use dup2 to operate on the same file descriptor at the same time. We need to lock the file descriptor table during the dup process.
1 | |
sys___getcwd and sys_chdir
What function should we use to get the current working directory?
Getting the current working directory is like reading from a file. Changing the working directory is like writing to a file. Therefore, we still need the uio structure describe the I/O operation. The working directory of the process is associated with specific file systems. Therefore, we need to use vfs layer functions to interact with the file system.
To get the current working directory(cwd):
Take a look at uio_kinit, the uio structure is initiated with a kernel buffer. Therefore, we need to first read the cwd into a kernel buffer and then use copyout to copy the data to user buffer.
To change the current working directory(cwd):
We first need to use copyinstr to copy the pathname into a kernel buffer kpath and use kpath to do the work.
1 | |
1 | |
syscall.c
The parameters for those system calls lie mainly in the trapframe. The special case is lseek, whose last parameter lies on user stack.
1 | |
The return values of those system calls are 32 bits long, with the exception of lseek, whose return value is 64 bits long.
1 | |
To sum up, we need to carefully pass the parameters to sys_* functions from the trapframe and pass the return values of those system calls to the trapframe where the user process can get them from when going back to user mode.
conf.kern
~/src/kern/conf/conf.kern:
Whenever creating a new file, include it in conf.kern and recompile the kernel.
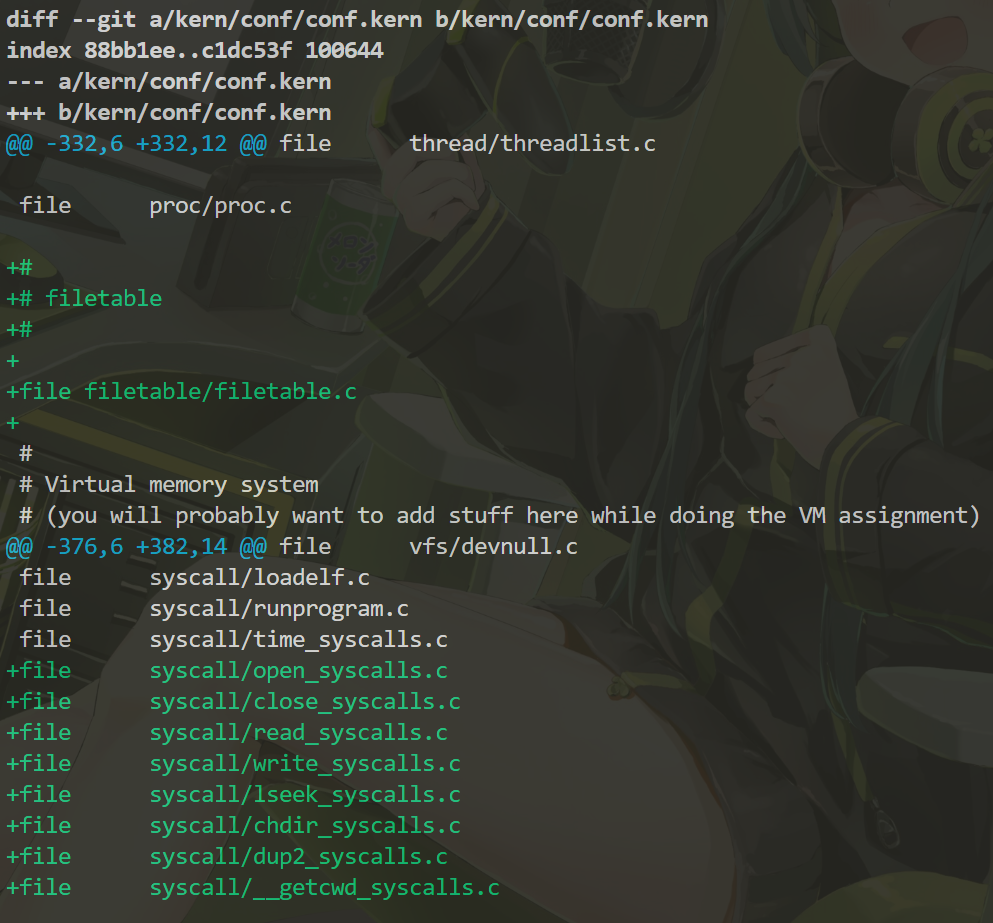
Finish!
Those are the files I have modified/created. Do not get here unless you are stuck in coding!
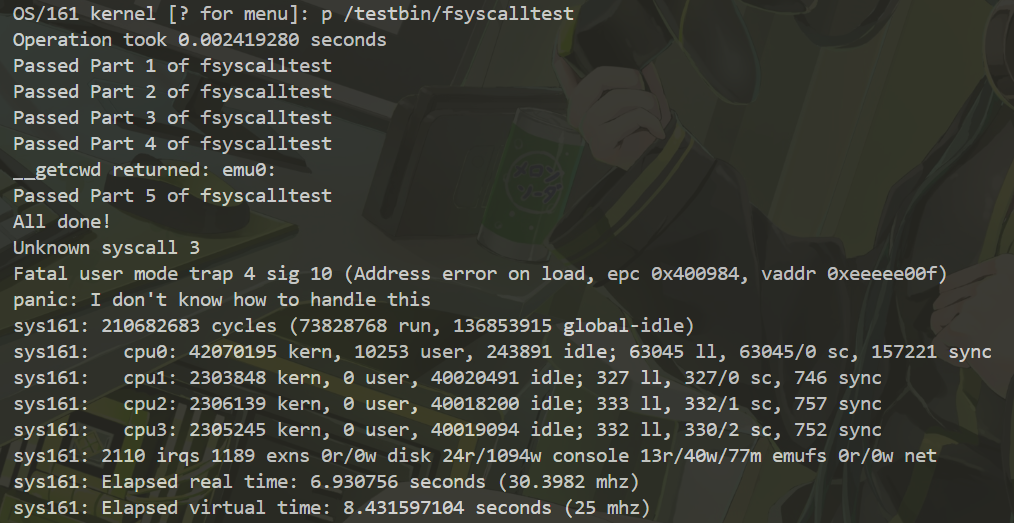
We have passed all tests in Assignment4!
1 | |
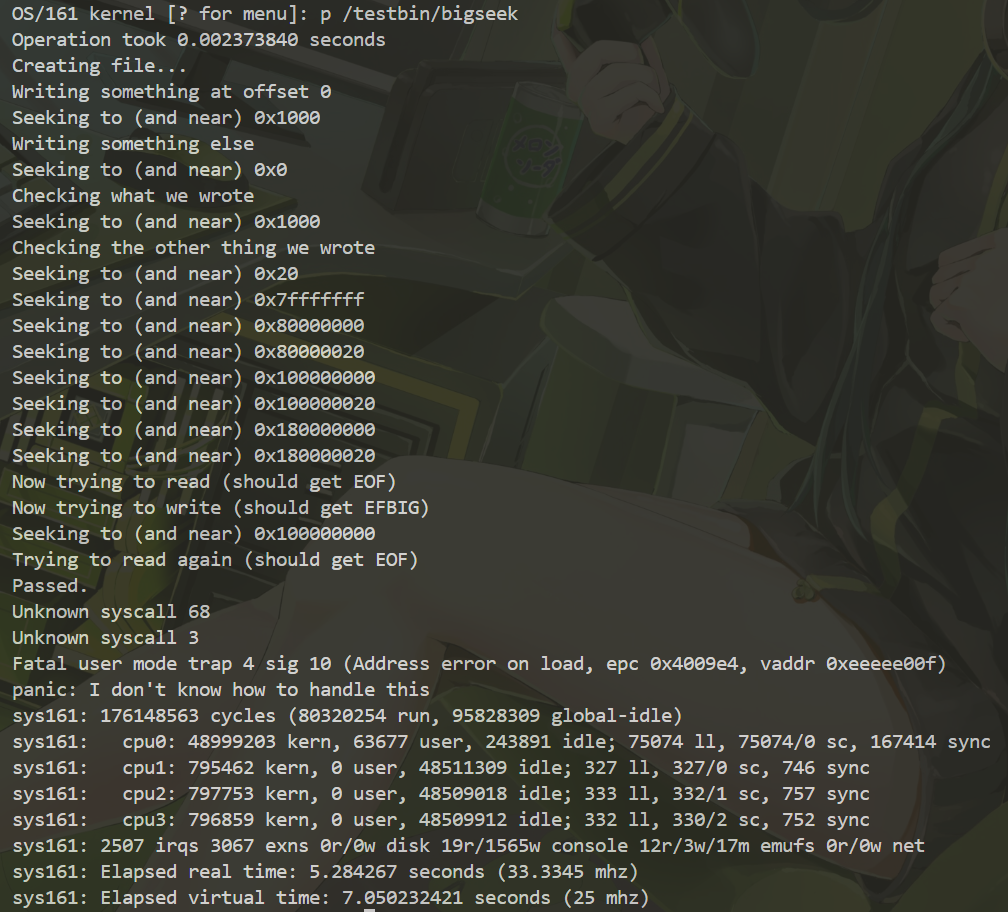
We have finished Assignment4!😊