Scheduling
In this part, we will talk about the topics of Job Scheduling in OS. We will cover different scheduling algorithm and real-life schedulers. Prepare for the journey of Scheduling!
Scheduling
Learning Materials
Videos:
Lecture Slides:
Readings:
[OSTEP] The multi-level feedback queue
[OSTEP] Lottery scheduling and Linux CFS
Architecture Overview
Basic Processor:
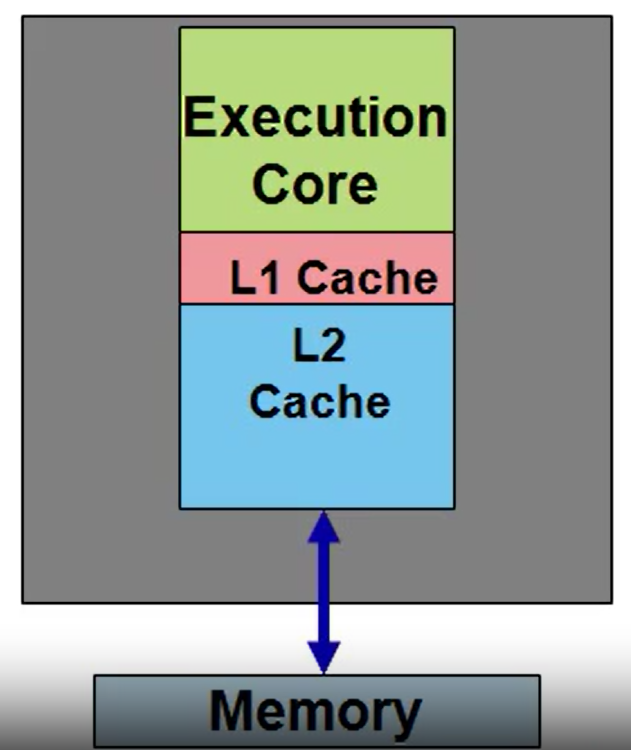
Multicore:
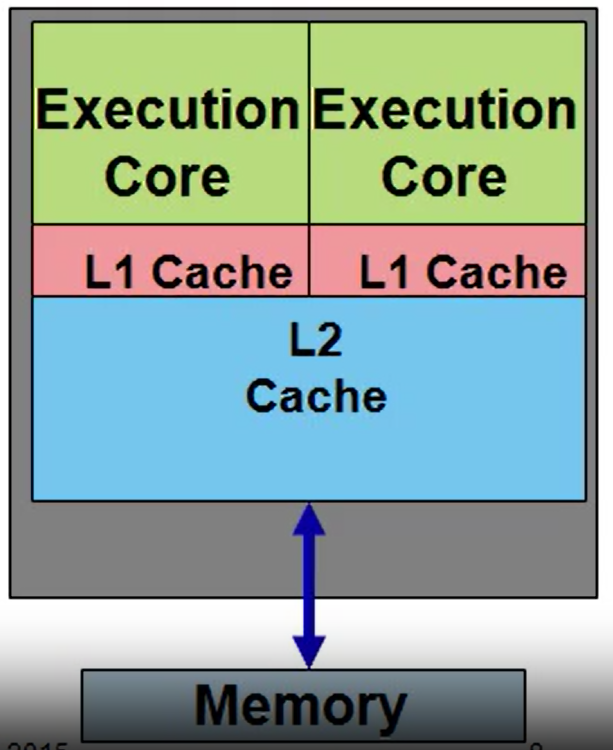
Modern Multiprocessor:
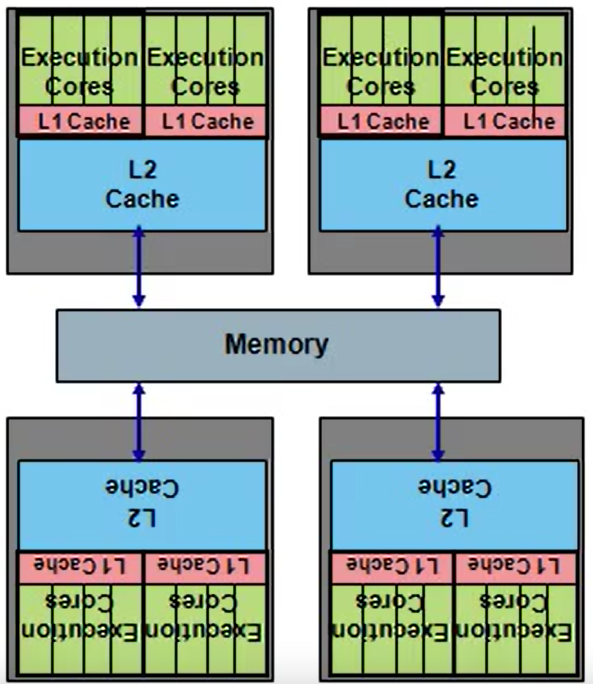
sys/161:
Not multithreaded: Each core/processor has only one thread
Do not distinguish cores from processors; N-way single-core multiprocessors
Scheduling: Introduction
How to build an optimal scheduler if we only consider
turnaroundtime?
-
FIFO(First in First out)
-
SJF(Shortest Job First)
-
STCF(Shortest Time-to-Completion First)
Optimal, if we know job lengths and our only metric is turnaround time.
How can we build a scheduler that is sensitive to response time?
- RR(Round Robin)
A tradeoff between turnaround time and response time
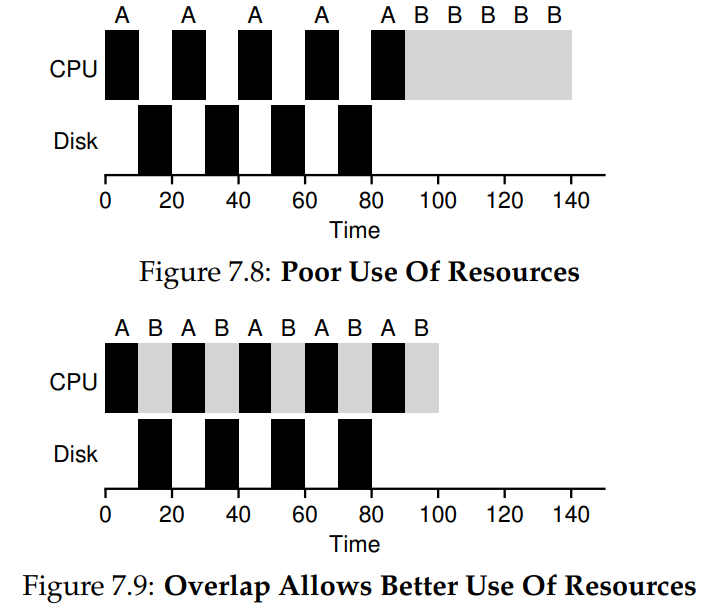
How to take I/O into account?
The answer is Overlap!: Treat each CPU burst as a job.
How to determine the
timeslice?
timeslice should be short, maximizing multitasking, but shouldn't be too short, otherwise context switch time would be long
context switch:
- save the register of the old thread
- find the new thread from the
runqueue - restore the new thread's register
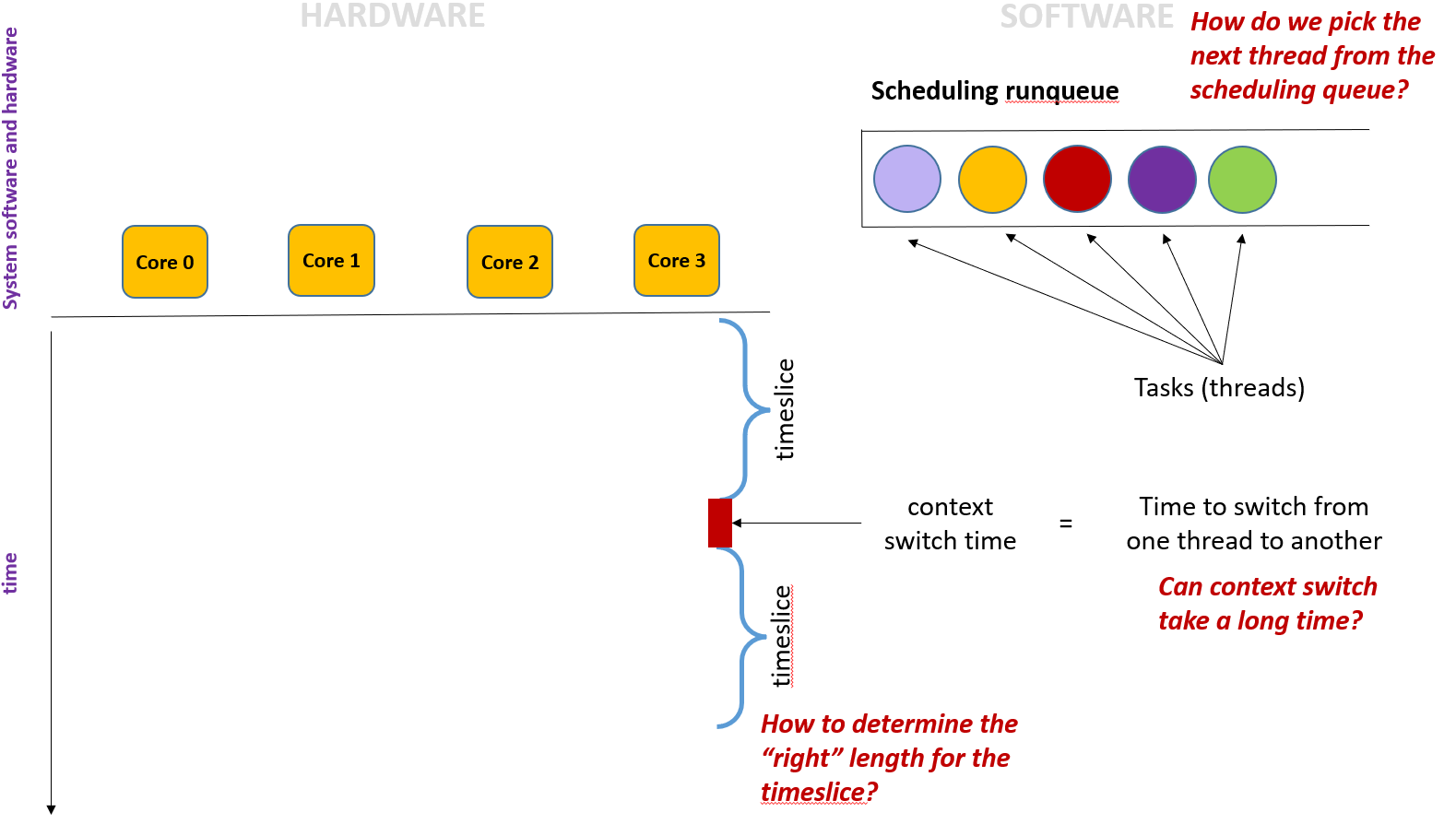
How do we pick the next thread from the
runqueue?
Scheduling Algorithm:
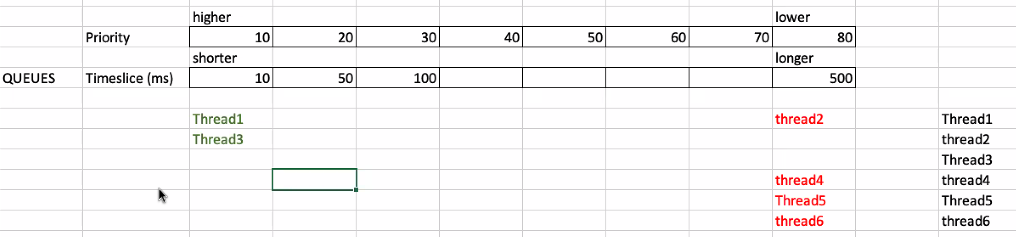
Multiple queues with different priority and timeslice
Short timeslice thread has higher priority.
If a lower priority thread hasn't run for a long time, it will be moved to upper priority.
The multi-level feedback queue
MLFQ observes the execution of a job and prioritizes it accordingly.
- Rule 1: If Priority(A) > Priority(B), A runs (B doesn’t).
- Rule 2: If Priority(A) = Priority(B), A & B run in Round-Robin fashion using the time slice (quantum length) of the given queue.
- Rule 3: When a job enters the system, it is placed at the highest priority (the topmost queue).
- Rule 4: Once a job uses up its time allotment at a given level (regardless of how many times it has given up the CPU), its priority is reduced (i.e., it moves down one queue).
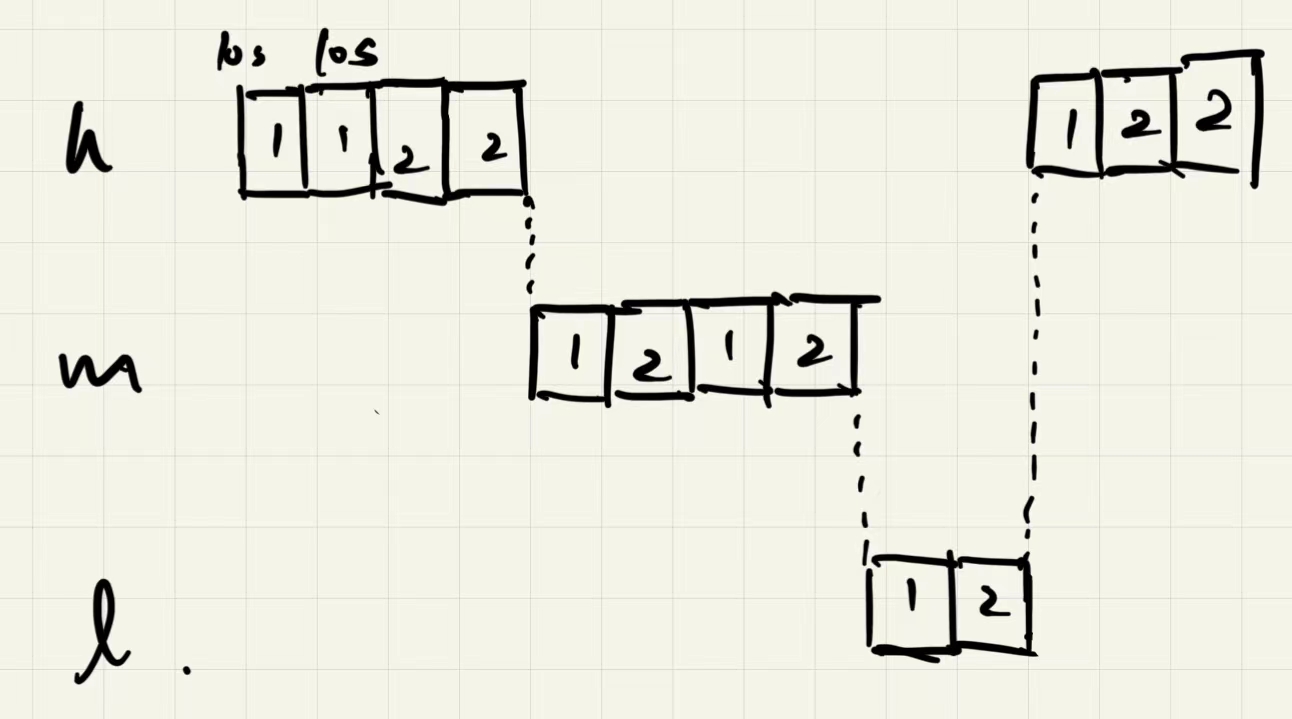
- Rule 5: After some time period S, move all the jobs in the system to the topmost queue.
MLFQ Problem:
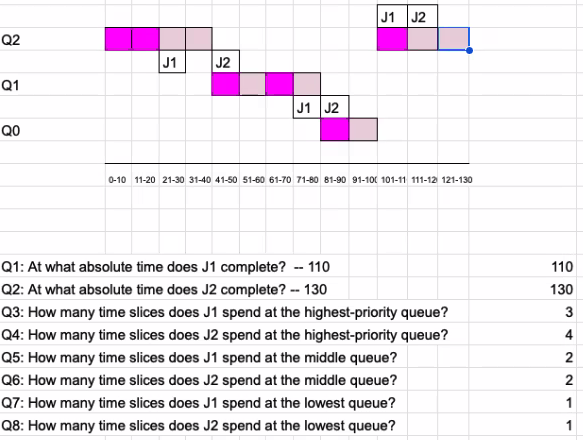
Simulate the Multi-Level Feedback Queue Algorithm discussed in the book. Assume the final version of the algorithm presented in the book, but no tuning. You have the following parameters and constraints:
- Time starts at 0ms.
- There are three queues: highest-priority, middle-priority and low-priority.
Timesliceequals to 10ms.- Allotment equals to 20ms.
- S equals to 100ms.
- All jobs use up their entire timeslice every time they are scheduled.
- Job J1 arrives at 0ms.
- Job J2 arrives at 20ms.
- J1 requires 60ms of CPU time to complete.
- J2 requires 70ms of CPU time to complete.
bright color: J1; light color: J2
Scheduling: Proportional Share
Guarantee that each job obtains a certain percentage of CPU time.
Use tickets to represent a process's share of the CPU
Lottery Scheduling Decision Code
1 | |
Stride Scheduling
Deterministic fair-share scheduler
Stride is inverse in proportion to the number of tickets it has, computed by dividing some large number by the number of tickets each process has been assigned.
Every time a process runs, we will increment a counter for it (called its pass value) by its stride to track its global progress. At any given time, the scheduler picks the process to run that has the lowest pass value so far.
1 | |
Lottery scheduling makes more sense than stride scheduling when incorporating new processes.
Linux Completely Fair Scheduler (CFS)
As each process runs, it accumulates vruntime at the same rate in proportion with real time.
When a scheduling decision occurs, CFS will pick the process with the lowest vruntime to run next.
CFS uses sched_latency to determine how long one process should run before considering a switch, determining its time slice but in a dynamic fashion.
CFS will never set the time slice to less than min_granularity.
- Weighting (Niceness)
CFS gives each process a nice value indicating its priority.
CFS maps the nice value of each process to a weight:
1 | |
Then calculate each process's time slice:
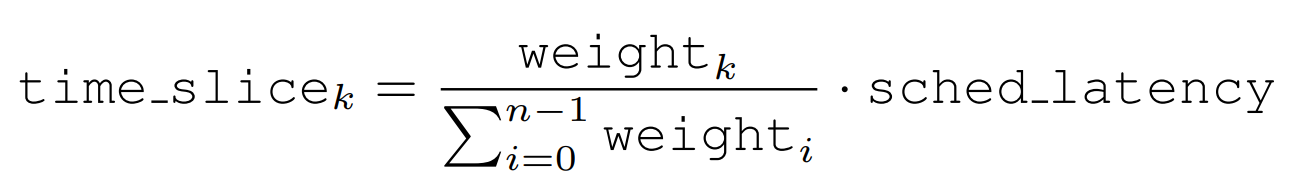
Change the way CFS calculates vruntime:
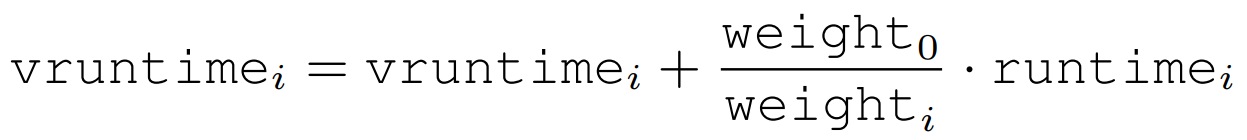
That is to say, a process has higher priority will dominate CPU for a longer time but its vruntime increases slower.
- CFS Red Black Tree
CFS uses a red black tree to keep the runnable processes by their vruntime.
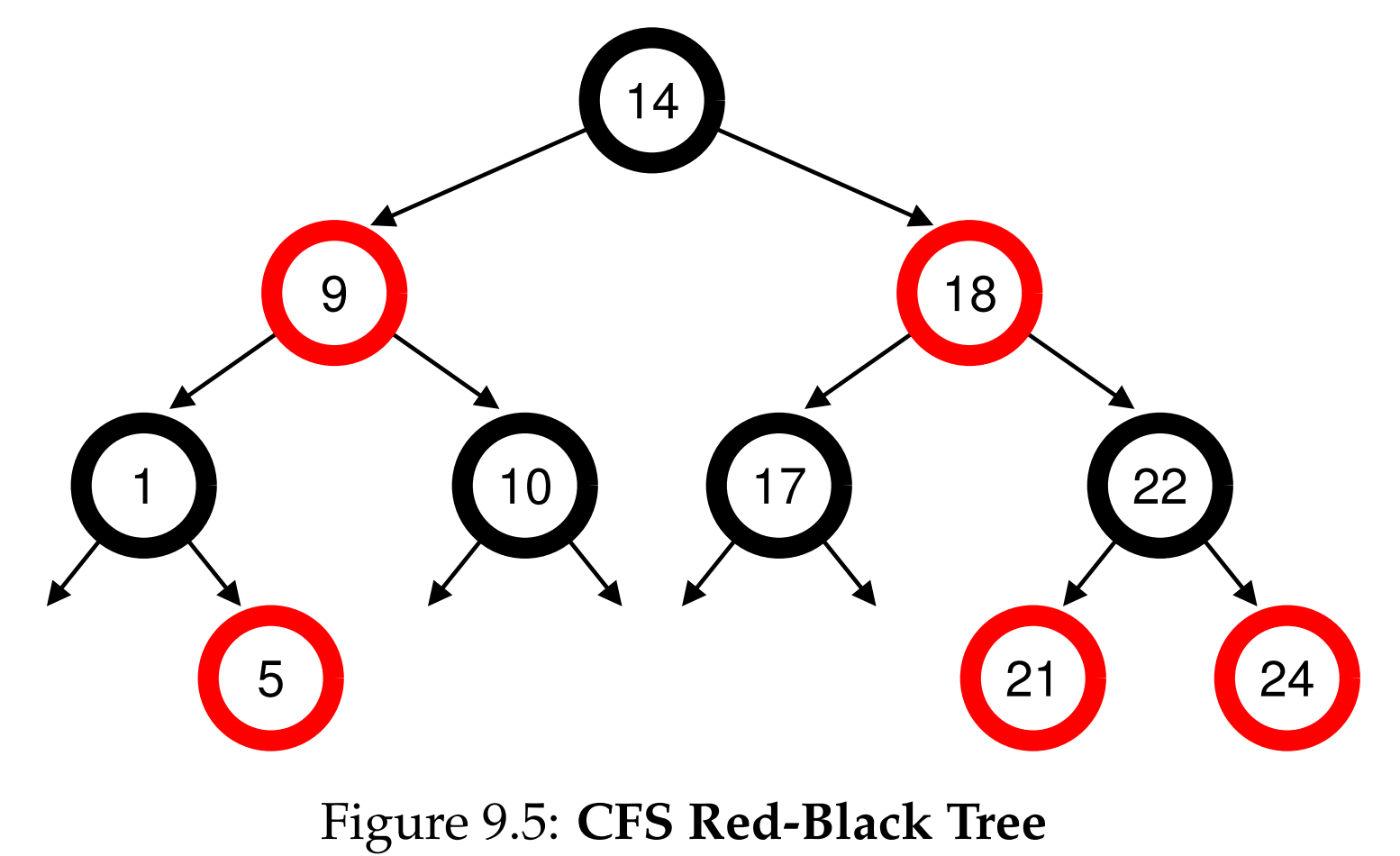
CFS handles sleeping processes by setting the vruntime of a job to the minimum value found in the tree when it wakes up.
Problems of fair-share schedulers
-
Do not particularly mesh well with I/O.
-
leave open the hard problem of ticket or priority assignment (How to assign tickets? How to set nice values?)
Multiprocessor scheduling
How should the OS schedule jobs on multiple CPUs?
Cache Affinity
A process, when run on a particular CPU, builds up a fair bit of state in the caches (and TLBs) of the CPU. Therefore, a multiprocessor scheduler should consider keeping a process on the same CPU if at all possible.
Single-Queue Scheduling
It does not scale well (due to synchronization overheads), and it does not readily preserve cache affinity.
Multi-Queue Scheduling
How to deal with load imbalance?
work stealing: A (source) queue that is low on jobs will occasionally peek at another (target) queue, to see how full it is. If the target queue is (notably) more full than the source queue, the source will “steal” one or more jobs from the target to help balance load.
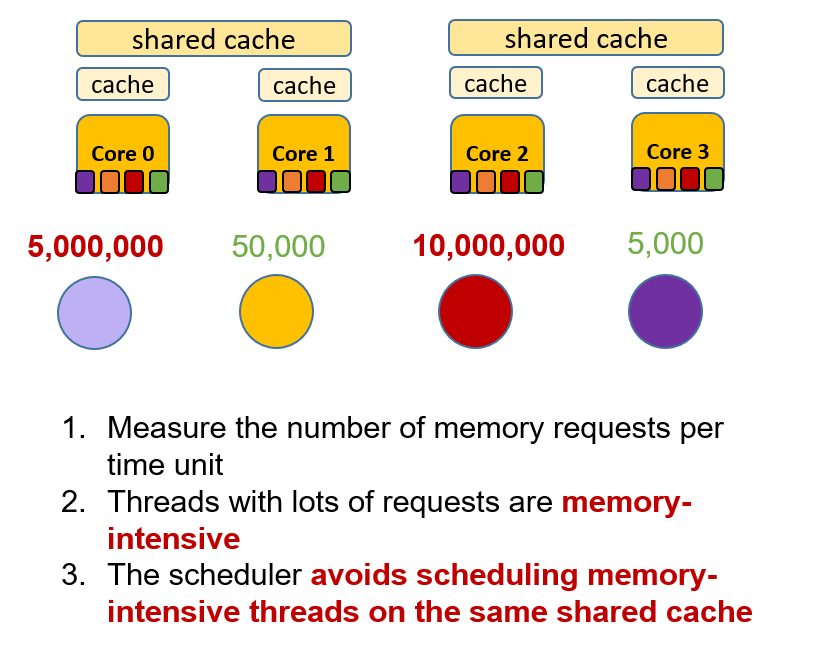
Advanced Scheduling
Avoid scheduling memory-intensive threads on the same shared cache to prevent cache contention.
Why did performance suck on a NUMA system?
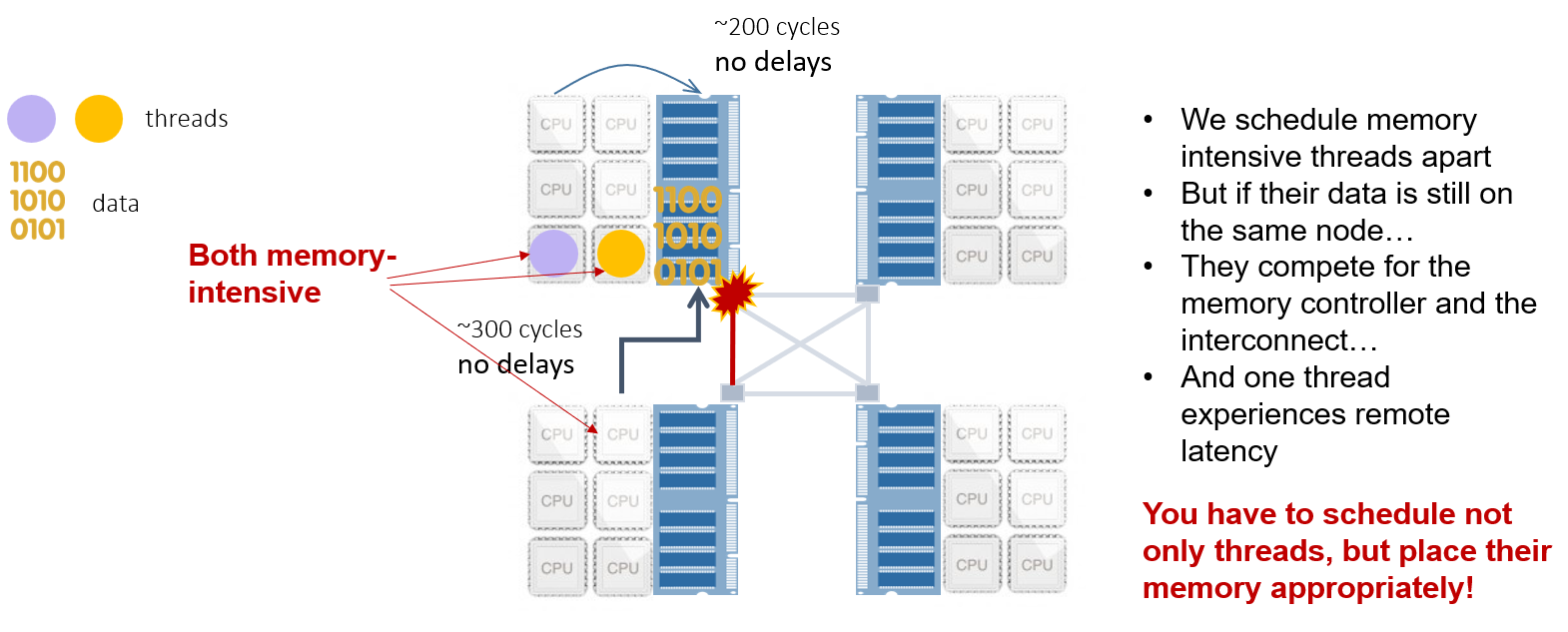
We didn't take account where the data lives in memory, resulting in remote latency.
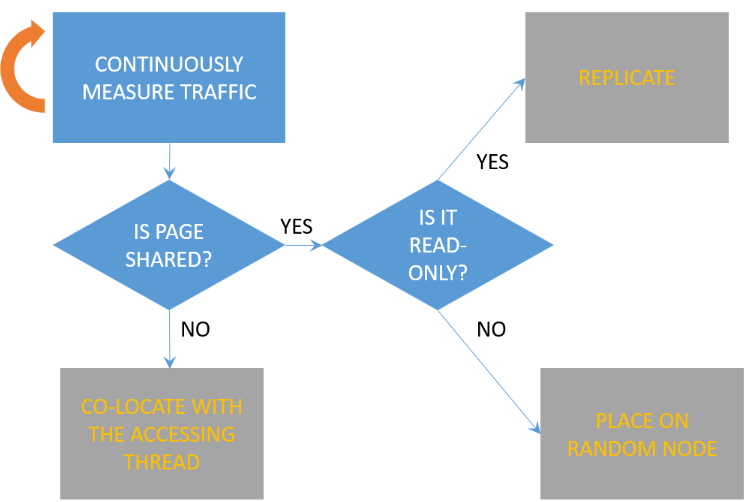
Our algorithm:
Continuously measure traffic(memory requests) of the thread.
Why placing on random node?
Balance the nodes and memory controllers.
Linux’s Completely Fair Scheduling (CFS)
Bugs in the Linux Scheduler: Cores may stay idle for seconds while ready threads are waiting in runqueues.
- On a single-CPU system, CFS is very simple
The scheduler defines a fixed time interval(sched_latency) during which each thread in the system must run at least once. The interval is divided among threads proportionally to their weights. The resulting interval (after division) is what we call the timeslice.
Threads are organized in a runqueue, implemented as a red-black tree.
- On multi-core systems, CFS becomes quite complex
Periodically run a load-balancing algorithm that will keep the queues roughly balanced.
The scheduler also invokes “emergency” load balancing when a core becomes idle.
- The (Hierarchical) load balancing algorithm
CFS balances runqueues based on a metric called load, which is the combination of the thread’s weight and its average CPU utilization. If a thread does not use much of a CPU, its load will be decreased accordingly.
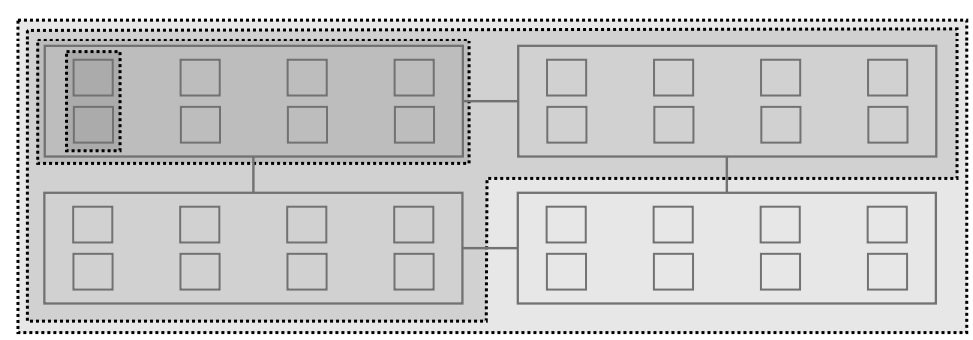
Function running on each cpu cur_cpu:
1 | |
- Special case
When a thread wakes up, after sleeping or waiting for a resource (e.g., locks, I/O), the scheduler tries to place it on the idlest core.
When the thread is awoken by another thread (waker thread). In that case the scheduler will favor cores sharing a cache with the waker thread to improve cache reuse.