CSAPP Chapter4
这篇笔记将记录我在ICS课上学习CSAPP第四章Processor Architecture(处理器体系结构)的过程。已完结。
Processor Architecture
参考资料:
y86 instruction set
这部分我们学习y86指令集和ISA,以便实现simulator和assembler lab。其中simulator模拟执行y86代码的硬件行为,assembler负责将y86汇编代码转化为硬件可以直接执行的二进制代码。学习y86指令集和ISA是为后续学习“程序是如何在CPU上运行的”打下基础。
y86-64处理器状态(Processor State)
- Program Registers
y86架构处理器包含15个寄存器,每个寄存器是64位的。

- Program Counter
- Condition Codes
Single-bit flags: OF: Overflow ZF: Zero SF: Negative
- Status Code
Program is running normally or some special event has occurred.
- Memory
We can use a big array in the simulator to simulate memory.
12类y86指令
每条指令都访问或改变program state的某些部分。

每条指令都可以用一个byte来表示:其中前4 bits是instruction code, 后4 bits是function code
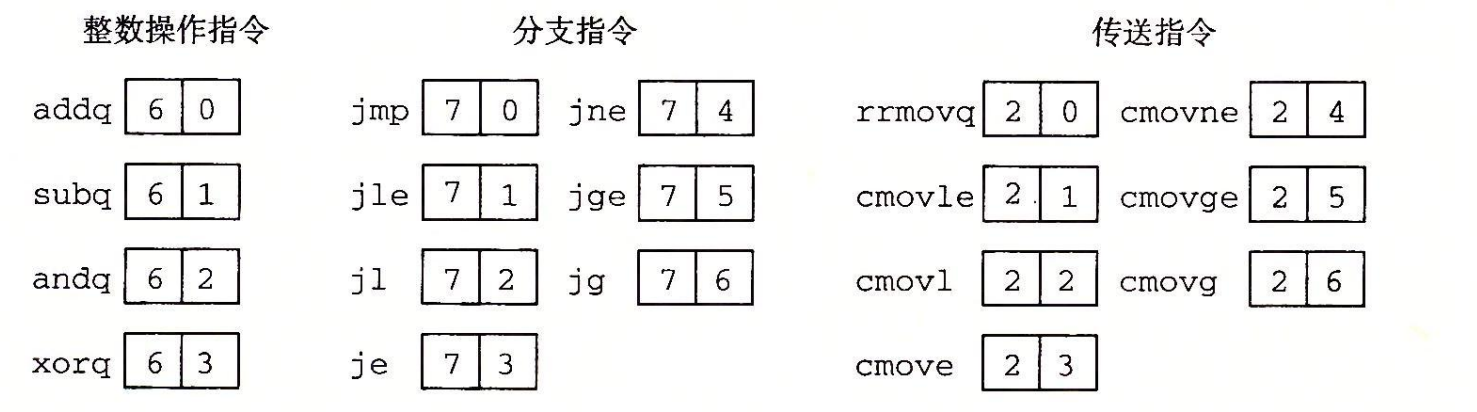
每个寄存器用一个4-bit ID表示:其中F代表没有使用寄存器

y86 program stack: 栈顶是地址最小的位置,栈向低地址扩张。
1 | |
y86-64 assembly code
一个简单的C函数:
1 | |
y86汇编代码:
"."开头的词是assembler directives(汇编器伪指令),告诉编译器调整地址。
注意代码的开头部分在main函数返回后就直接halt。因此这部分代码只能执行一个程序。

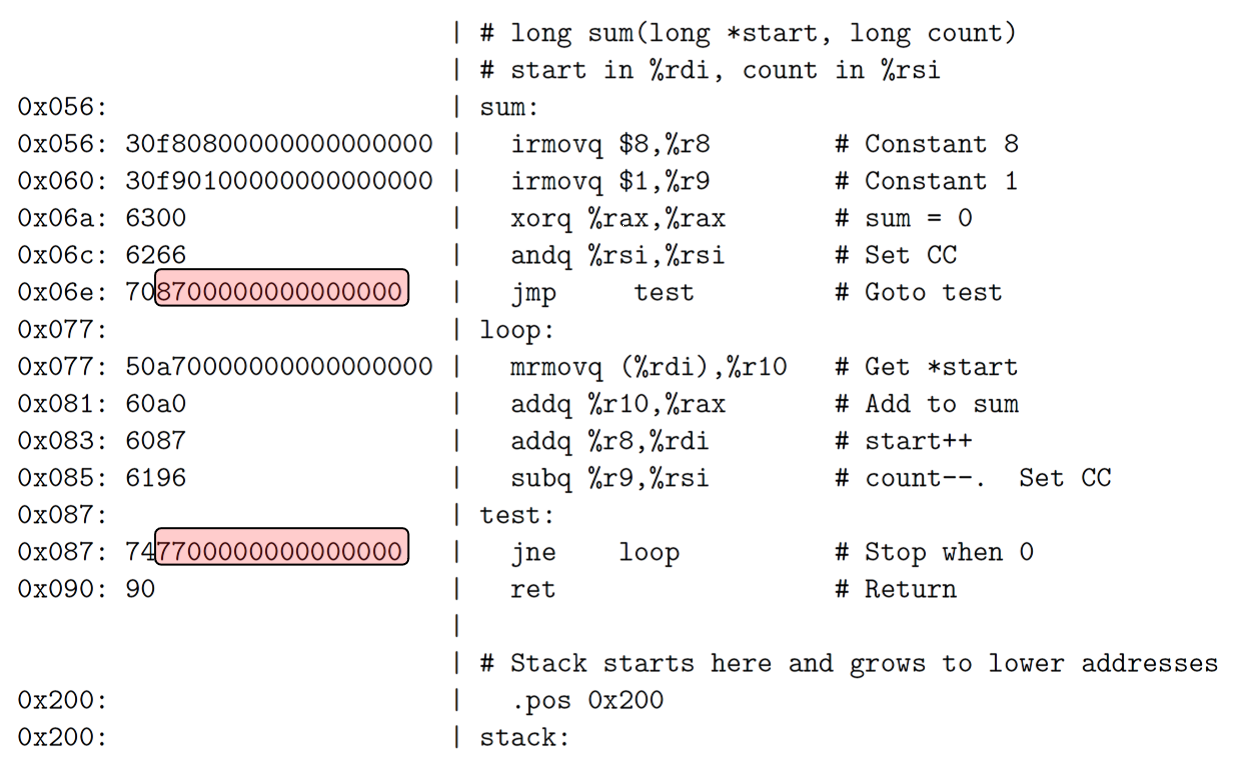
simulator在执行结束后需要检查最后的Program State是否正确,以此来判断硬件是否成功运行了y86汇编代码。
ISA(Instruction Set Architecture)
ISA(指令集架构)就是硬件呈现给上层汇编代码的接口,上层汇编代码通过ISA知晓底层硬件长什么样,可以提供哪些功能和接口,以此来调动硬件执行任务。
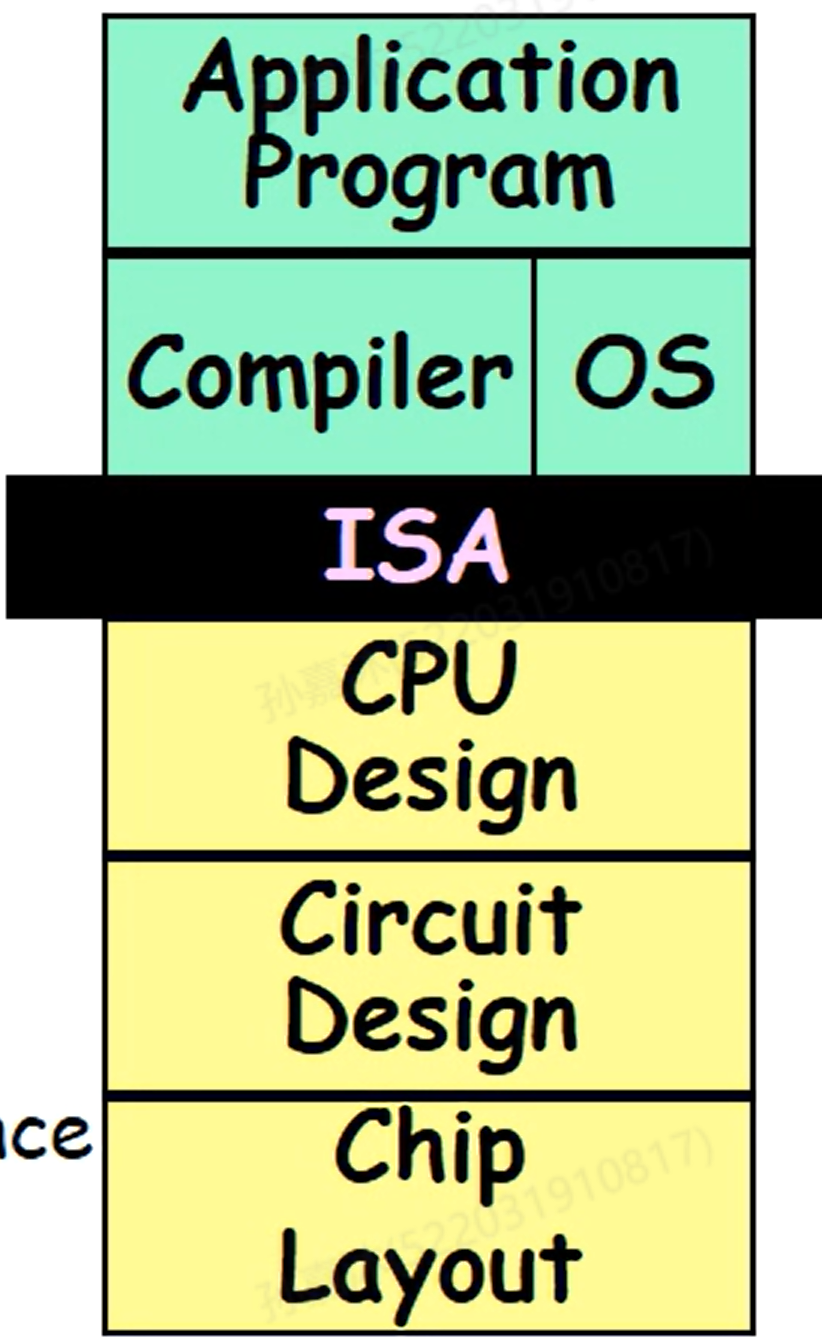
组成CPU的Building Blocks
这部分我们从组成CPU的最基本的两个building blocks入手开始学习:
- 组合逻辑电路
- Clocked Registers
组合电路
组合电路是由大量逻辑门组成的。HCL就是用来描述硬件行为,生成逻辑电路的语言。HCL表达式可以用来生成完成相应任务的逻辑电路。我们写的HCL表达式可以被现成的类似于Compiler的工具翻译成最佳的逻辑电路。
1 | |
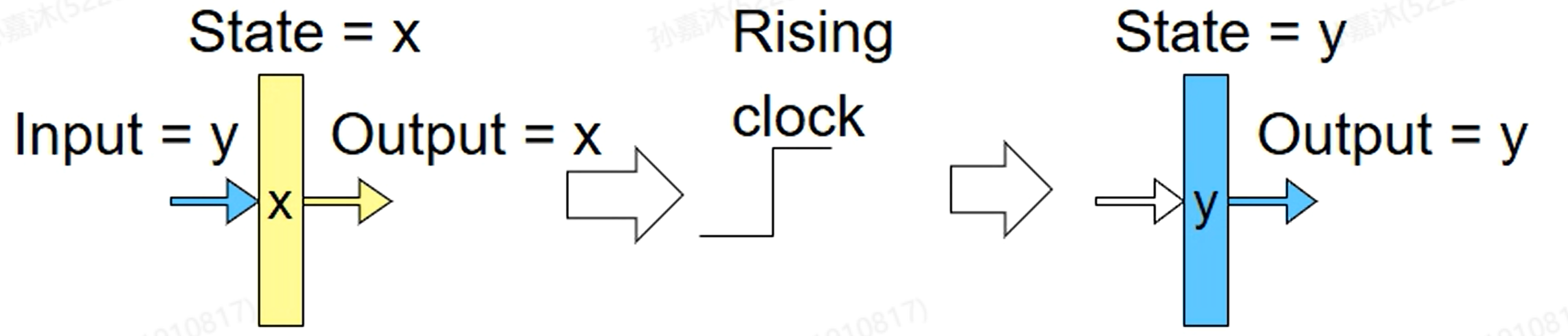
Storage (Clocked Registers)
当Clock由0->1跳变,新的Input就可以写入进去,写入之后Output读出来的就是新的值。
有了Clock Register我们就可以实现存储功能。注意Clock Register不是我们所说的CPU中的寄存器。
State Machine
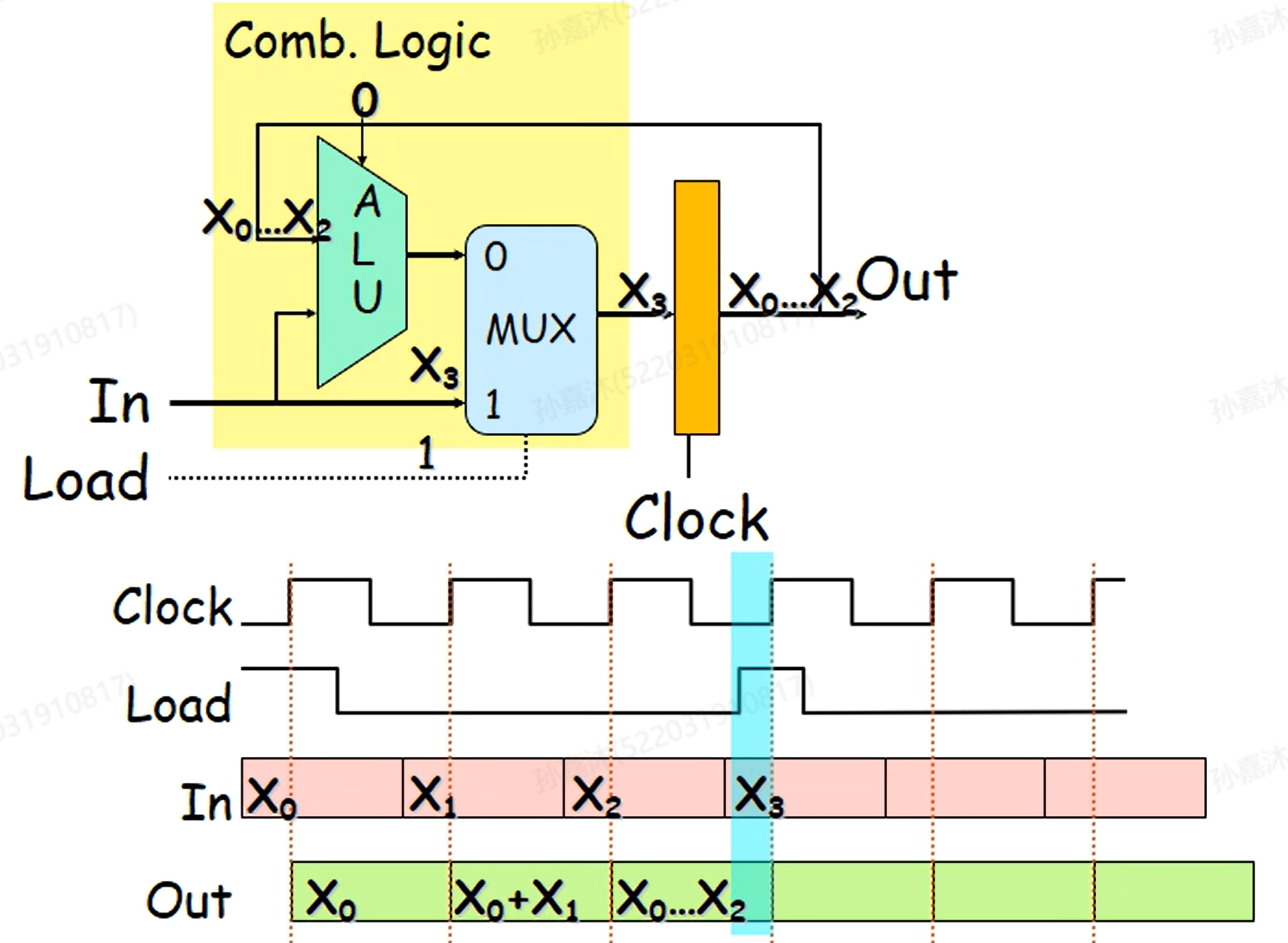
上图是一个简单的状态机例子。其实我们可以把CPU就看做一个状态机,CPU对指令的执行就是对硬件状态的修改。真实的CPU其实就是更复杂的组合逻辑电路。
Storage (Random-access memories)
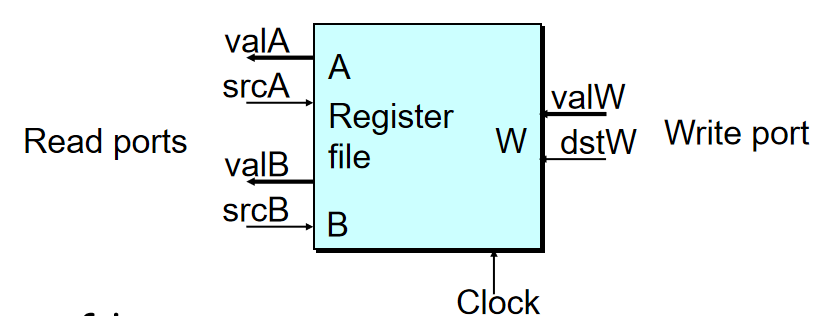
- Register File
储存Program Registers, Register Identifiers serve as address.
最多可以同时读取两个寄存器,因此有两个读取端,一个写入端。读取可以直接读出来,写入只能在Clock跳变0->1时才可以写入。其中src和dst是地址,val是寄存器的值:
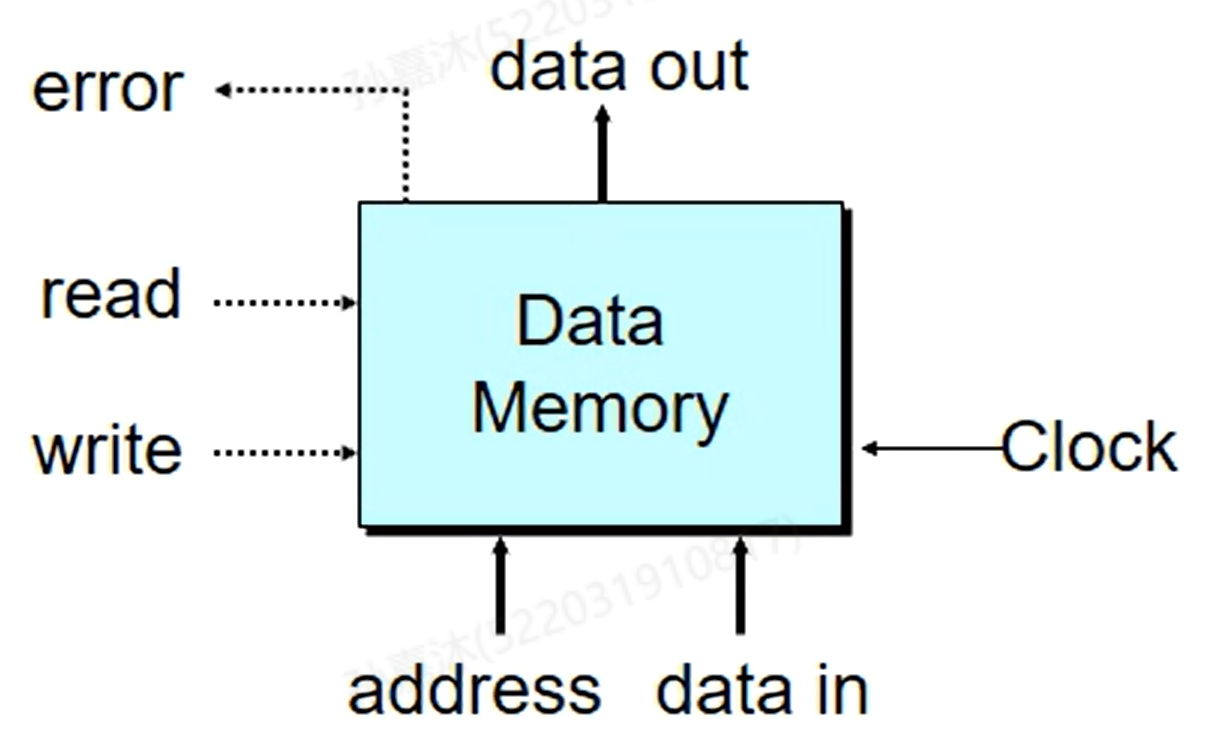
- Memory
Memory是用来存放数据和指令的,有一个error信号端口表示invalid address。
Sequential CPU Implementation
Multi-stages Design
将指令的执行分解为一系列的阶段(stage),为了能够复用硬件(电路)。
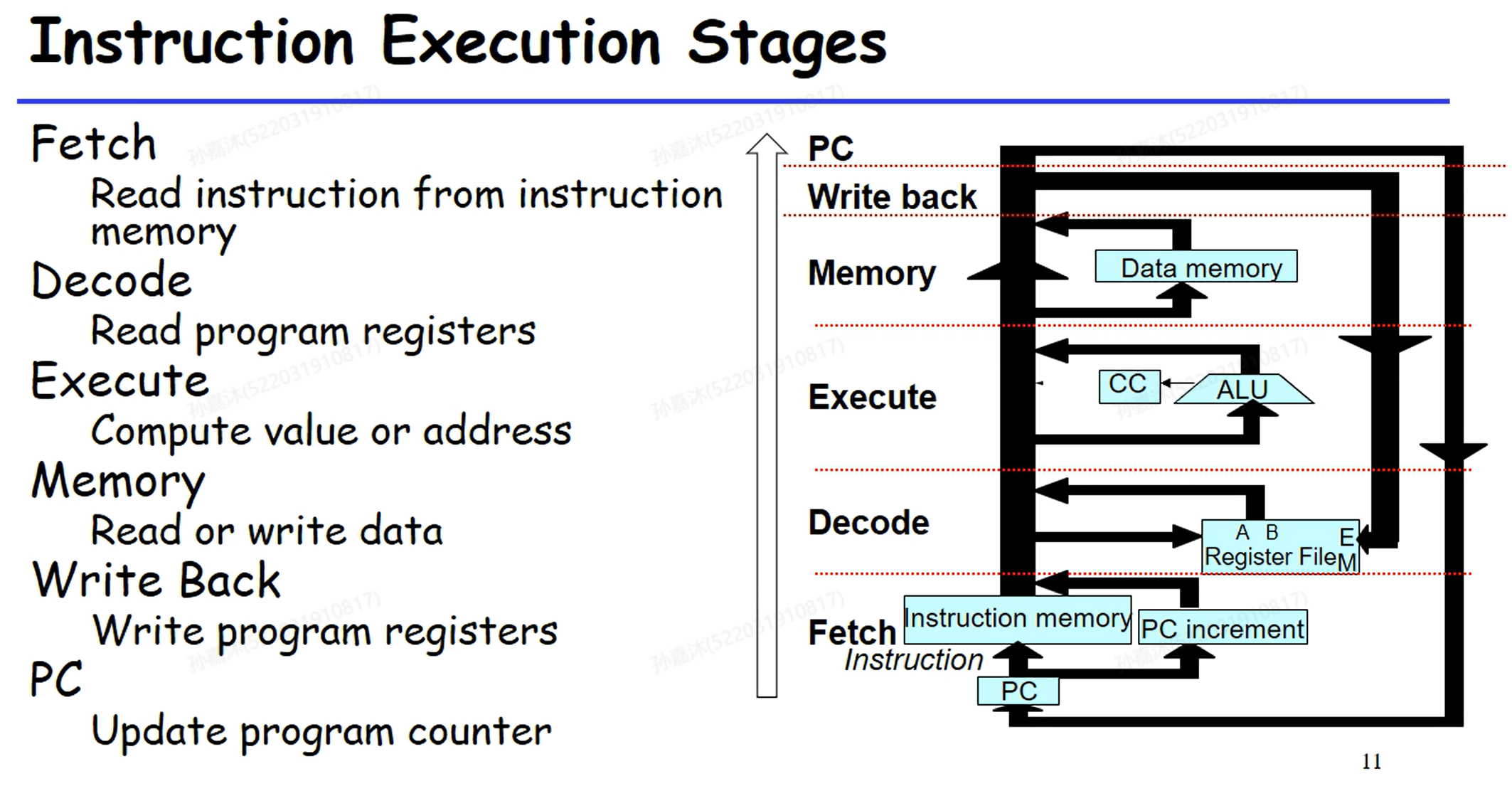
指令执行的6个阶段(stage)
- Fetch: 从内存中读取指令
- Decode: 读取寄存器
- Execute: 执行ALU操作(计算)
- Memory: 读/写内存
- Write Back: 写入寄存器
- PC: 更新PC
所有指令都要经过这6个阶段,共用相同的电路。
For example, an OPq instruction:

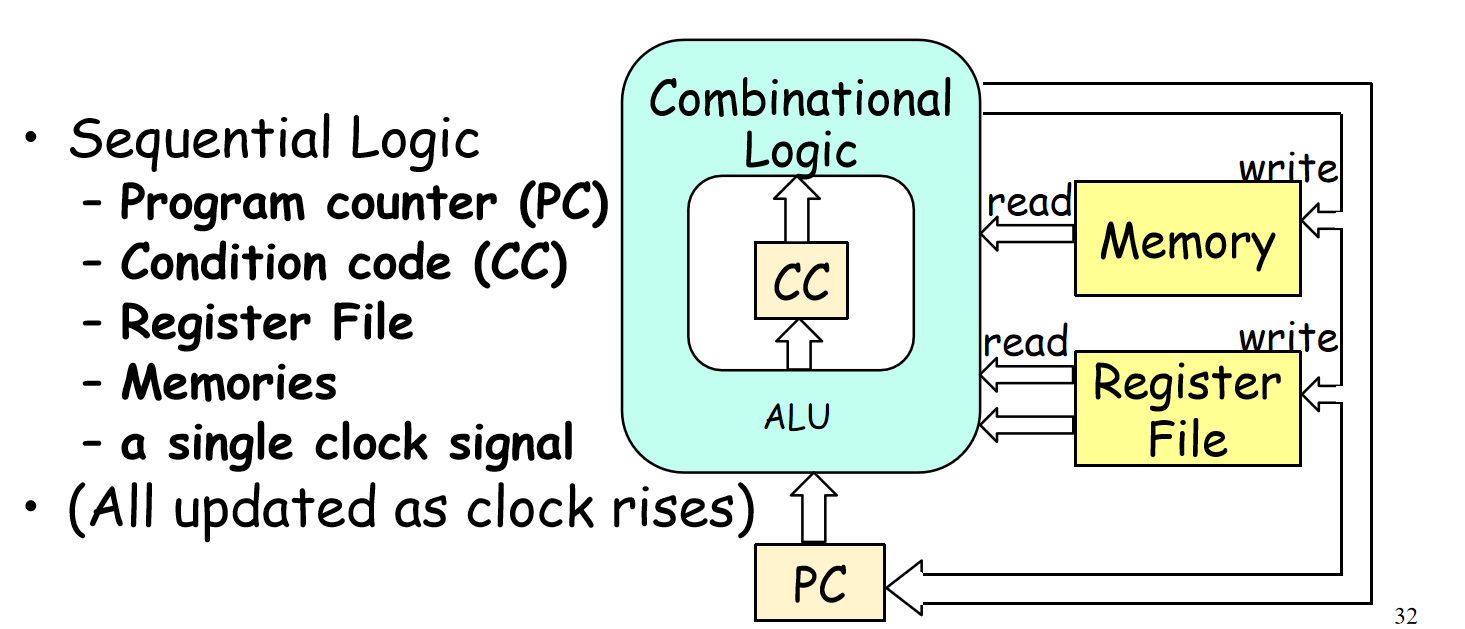
在指令执行的过程中所有的Processor state (memory, registers, CC, program status, PC)都是什么时候修改的?
你可能会想不同的processor state是在不同的阶段更新的。但其实所有的状态都存在clocked registers里面,而clock registers只有在clock从0跳变到1时才会写入新的值,整个CPU共用一个clock,clock跳一下(一个cycle)执行一条指令,因此所有的processor state其实是同时更新的!
一条指令执行(一个cycle)的大部分时间,都是让信号流满整个组合电路。等所有更新后的状态值都准备好等在clocked registers门口了,clock跳变,将所有新的状态一起写入进去。
逻辑电路实现
上面介绍了CPU将指令分解成各个阶段的设计,下面将介绍每个阶段具体的逻辑电路实现。
- Fetch Logic
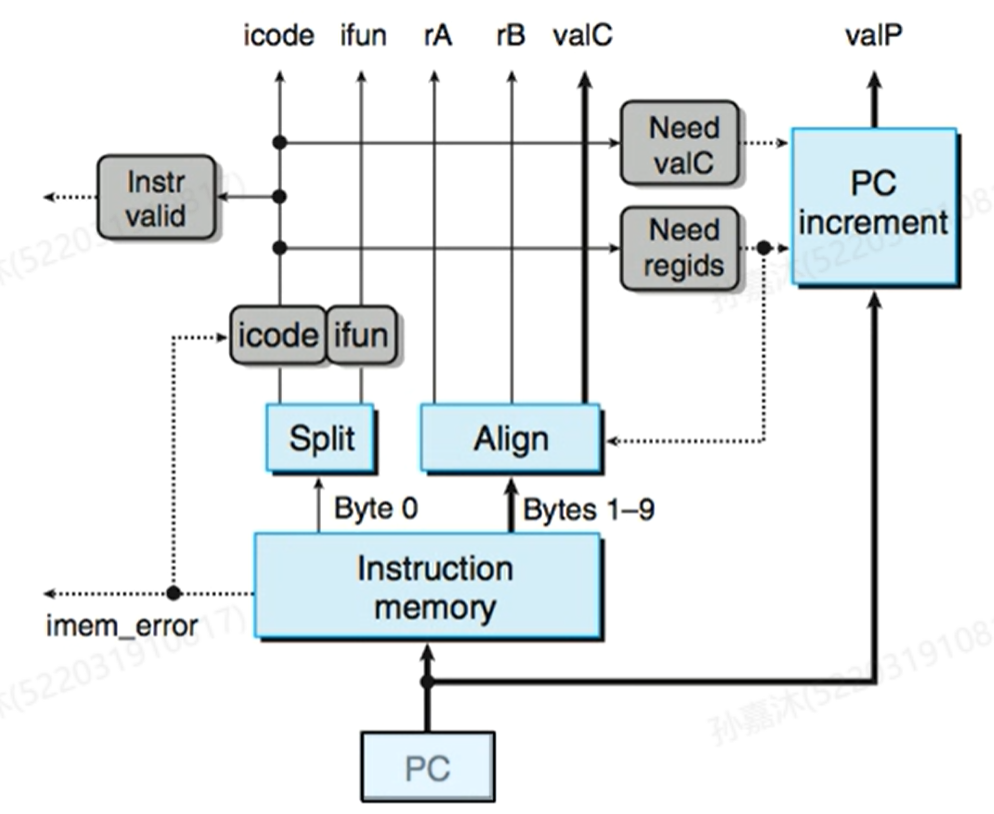
Fetch中主要Control Logic的HCL表达式:


注意如果mem出错,将icode设为nop
- Decode & Write-Back Logic
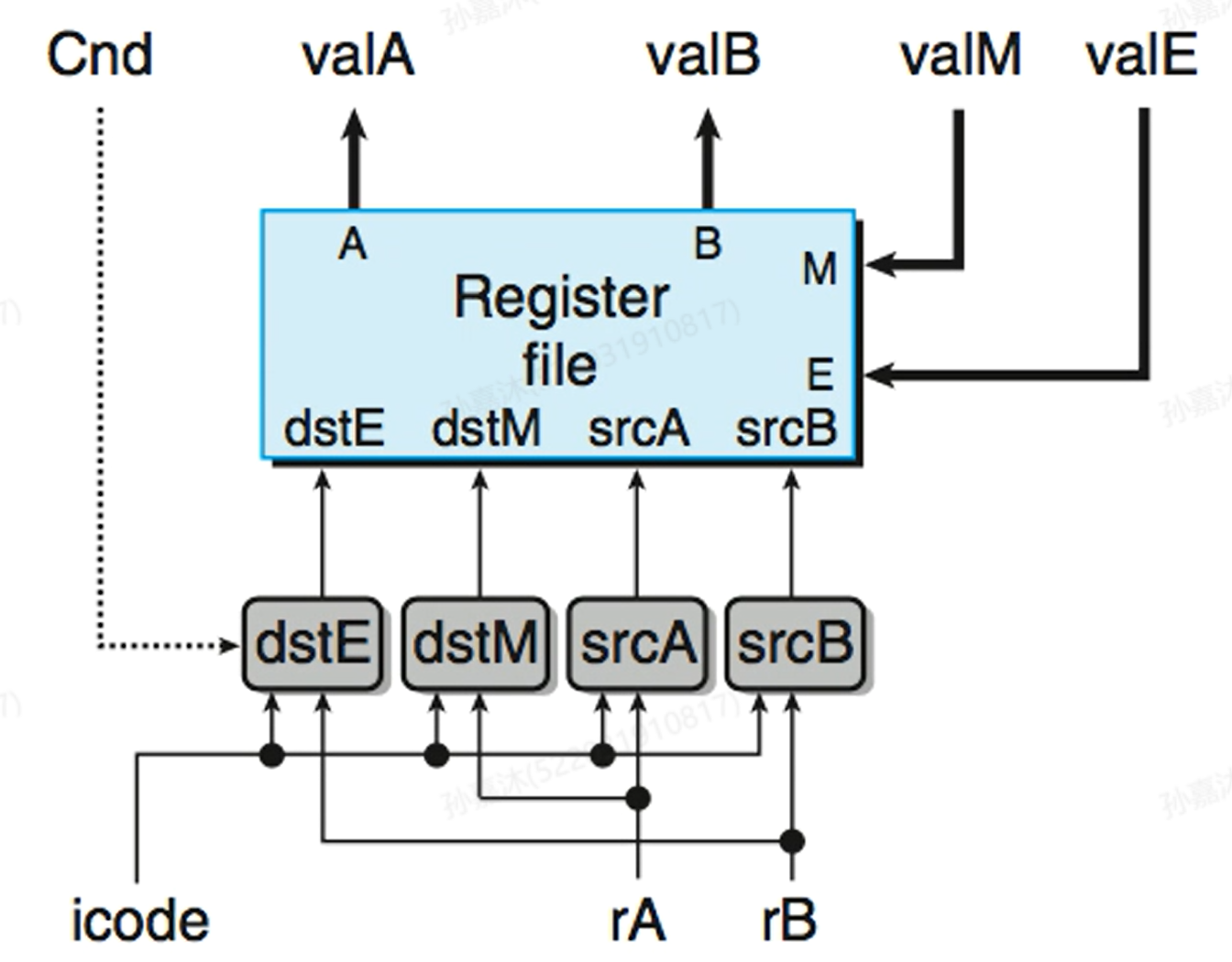
Decode中主要Control Logic的HCL表达式:

Write-Back中主要Control Logic的HCL表达式:

对cmovXX需要单独给他增加一条规则:如果Cnd为1,则dstE是rB,否则是RNONE
1 | |
- Execute Logic
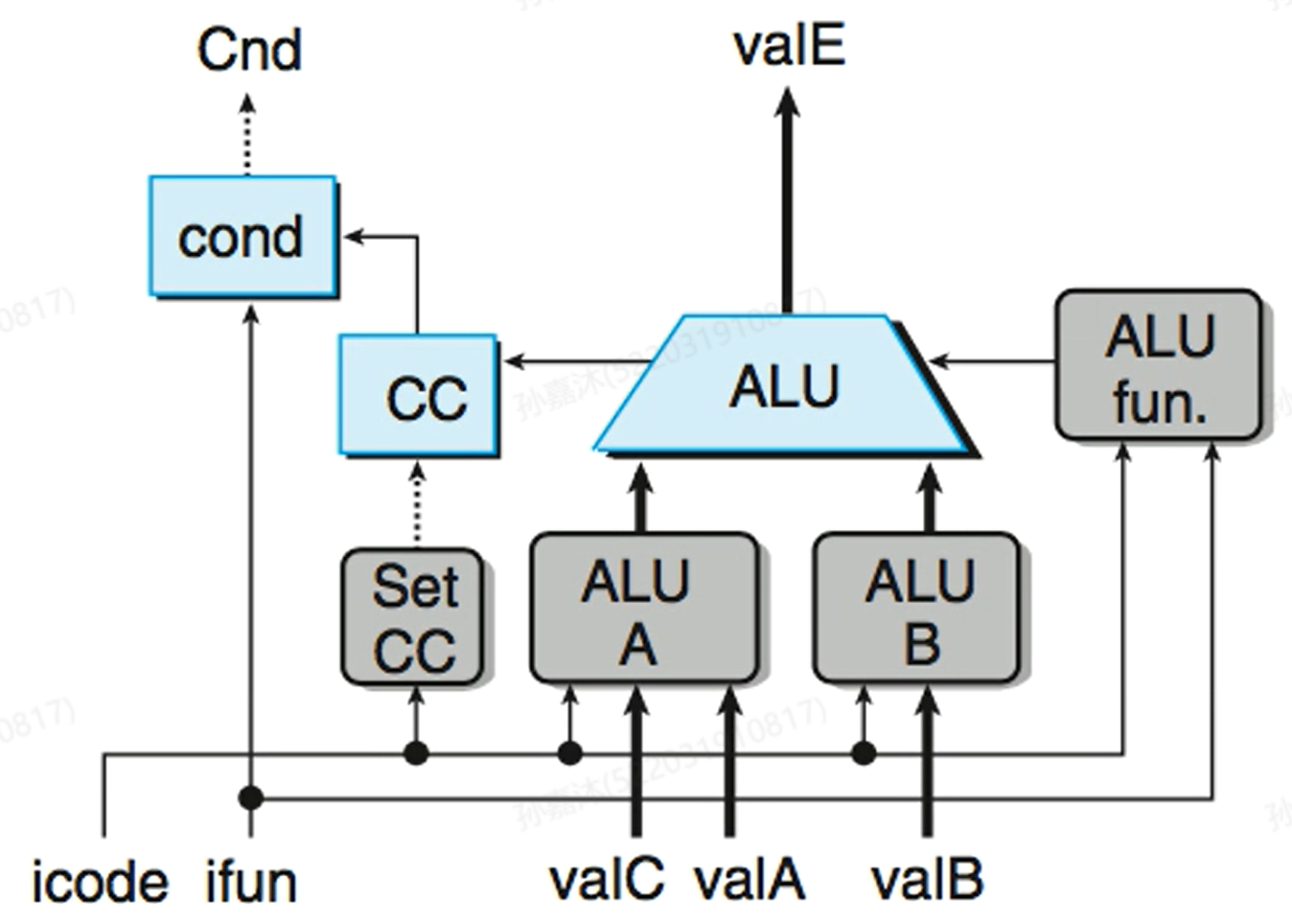
Execute中主要Control Logic的HCL表达式:


- Memory Logic
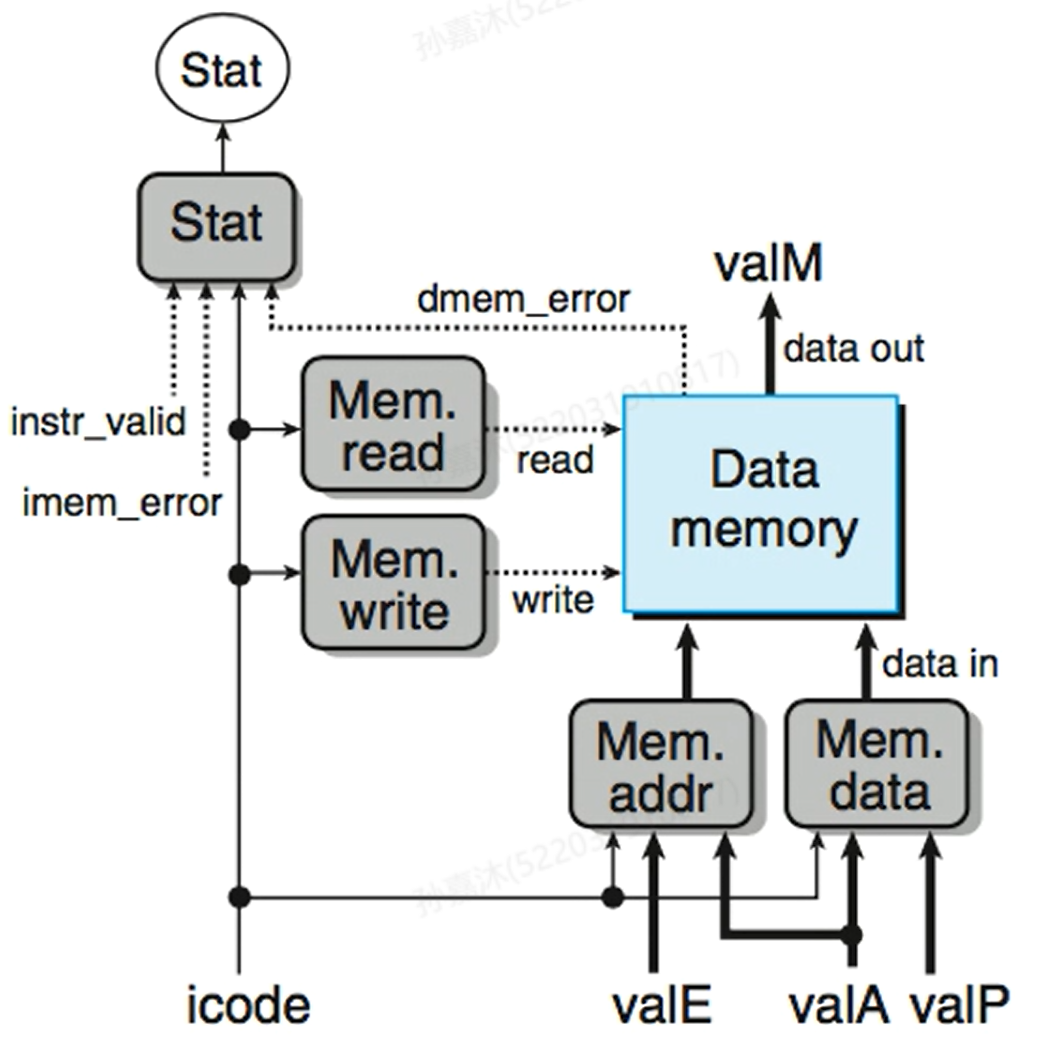
Memory中主要Control Logic的HCL表达式:

- PC Update Logic
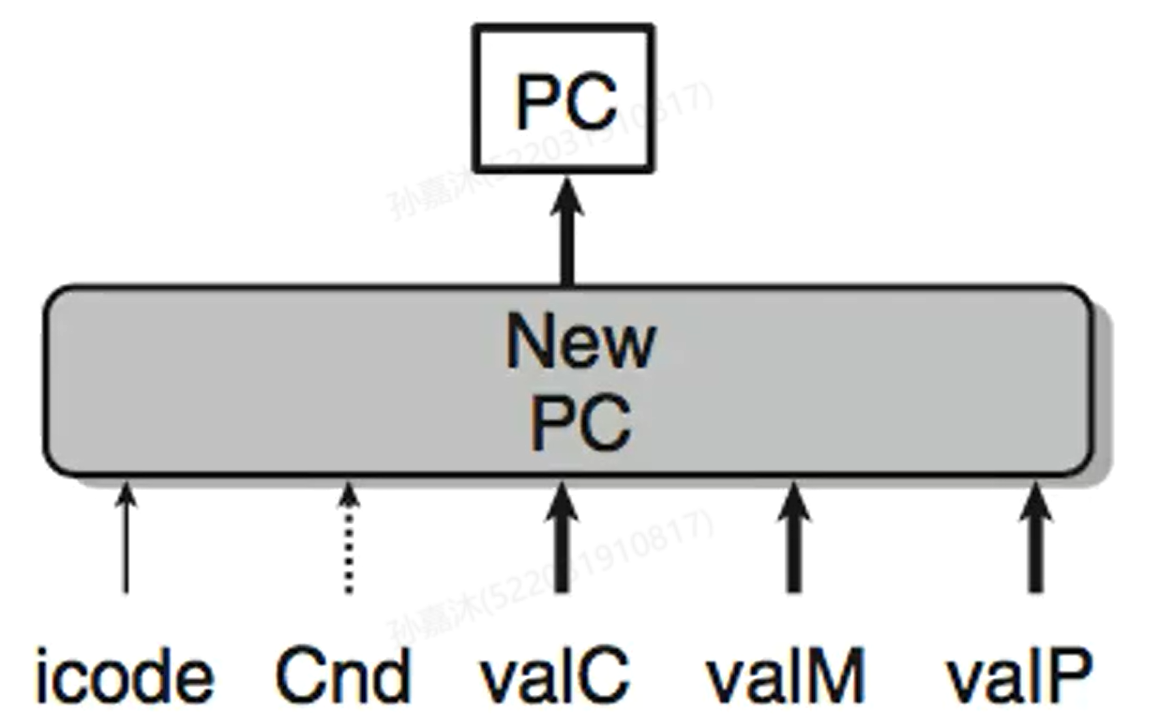
PC Update中主要Control Logic的HCL表达式:

SEQ总结
SEQ CPU执行起来是很慢的。一个cycle(clock跳变一次)只会执行一条指令。大部分时间都浪费掉了,没有发挥出CPU的潜力!
Principles of Pipeline
让多条指令同时充满整个CPU的所有stage。一次clock跳变每条指令前进一个stage。可以提升整体指令执行的吞吐量。通过Pipeline Registers存储指令执行阶段的中间值。
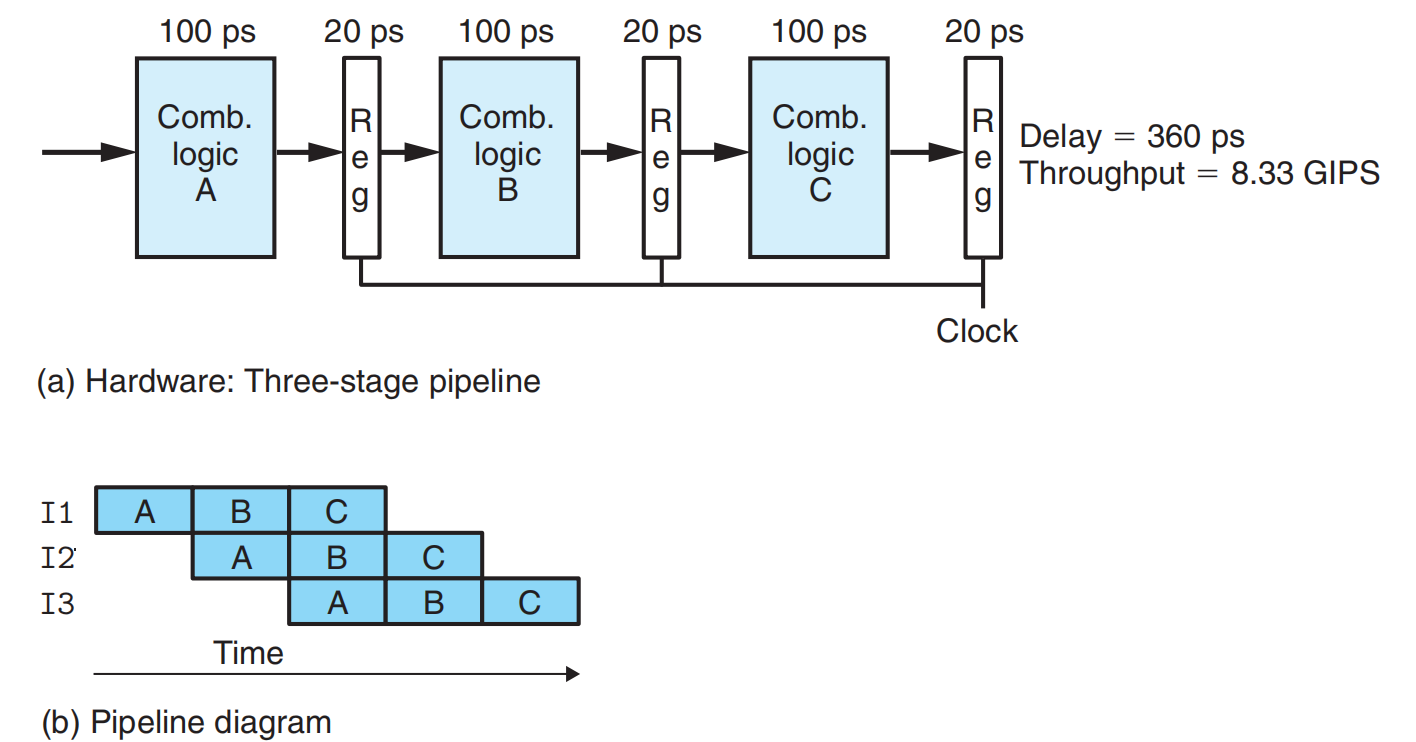
Limitations of Pipeline
- Nonuniform delays:
吞吐量会受最慢的stage的限制。在下图的例子中,一个cycle就是170ps。A阶段和C阶段会有大量的空闲时间
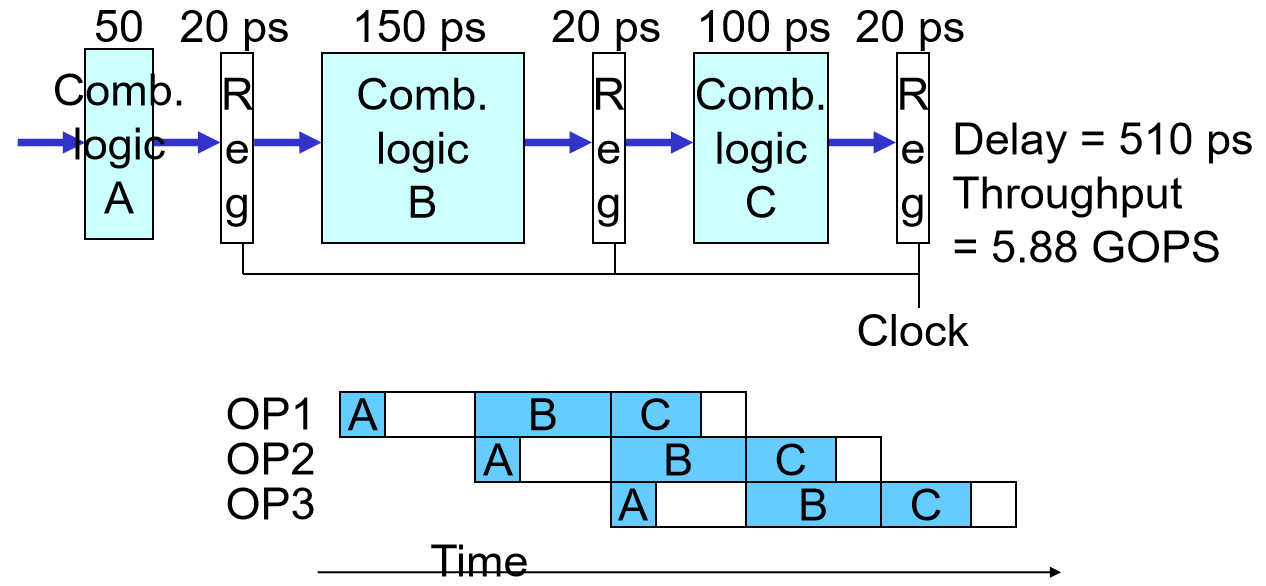
- (Pipeline) Register Overhead
如果每个阶段分得过细,那么加载pipeline register的overhead会很大。
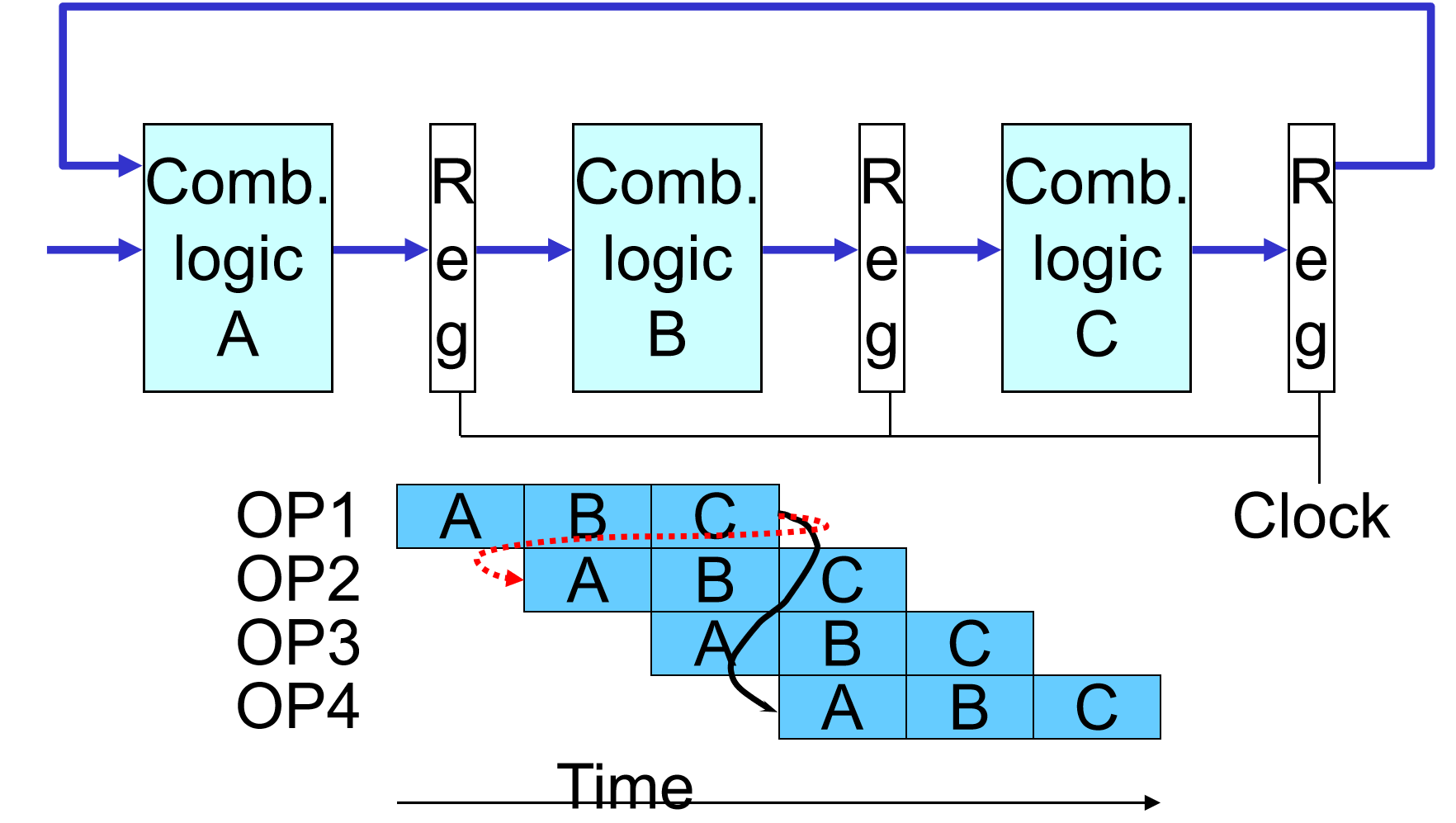
- Data Dependency
相邻的指令可能会依赖对方操作后的结果:
1 | |
Data Hazards:
这种情况就退化回了SEQ:
- Control Dependency
1 | |
The jne instruction create a control dependency — Which instruction will be executed?
SEQ+ Hardware
将PC Update阶段与Fetch阶段合并,不用实际的硬件寄存器存放PC,而是根据前一条指令的状态信息来动态计算PC:
1 | |
Fetch Logic:
- Select current PC
- Read instruction
- Compute incremented PC
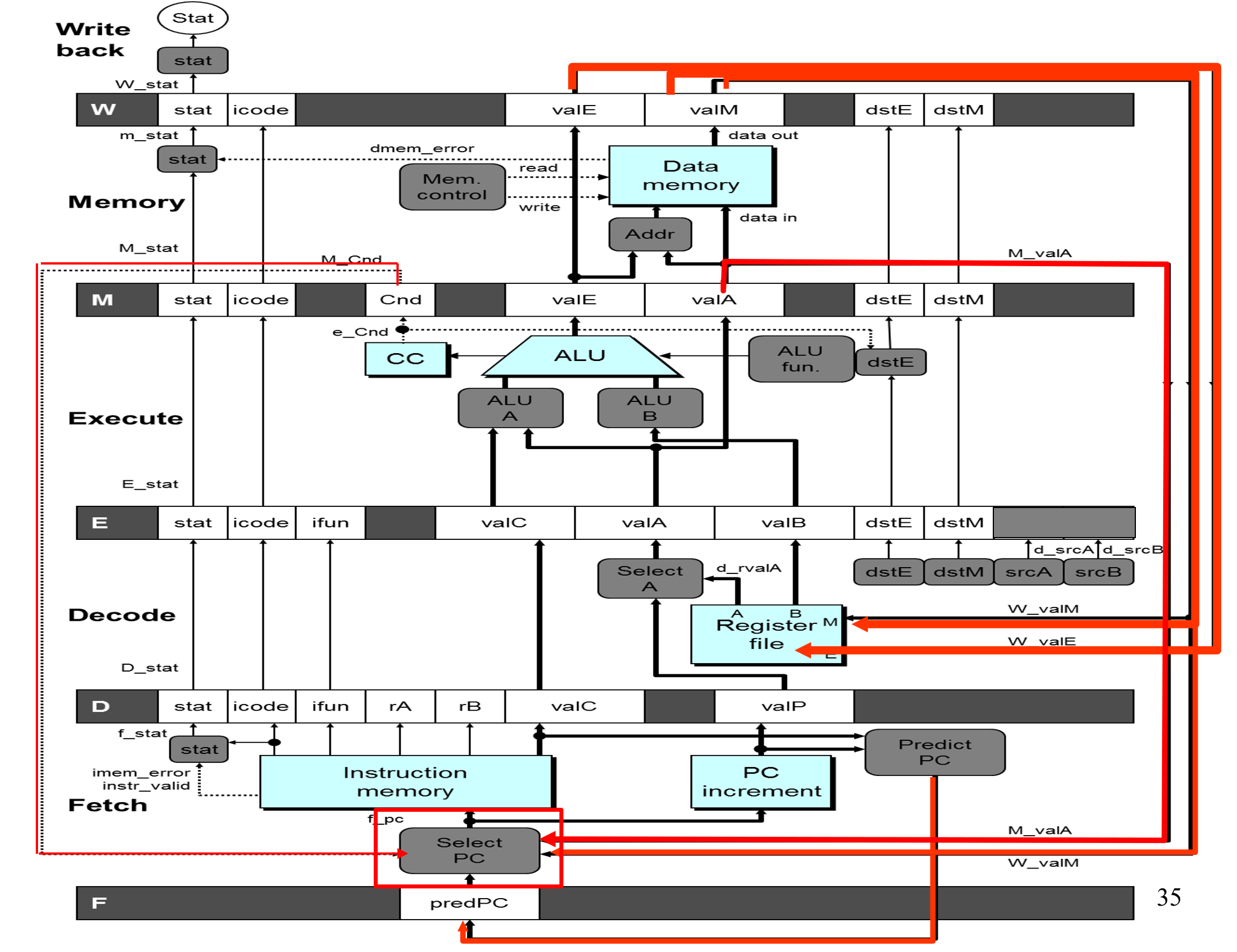
五级流水线
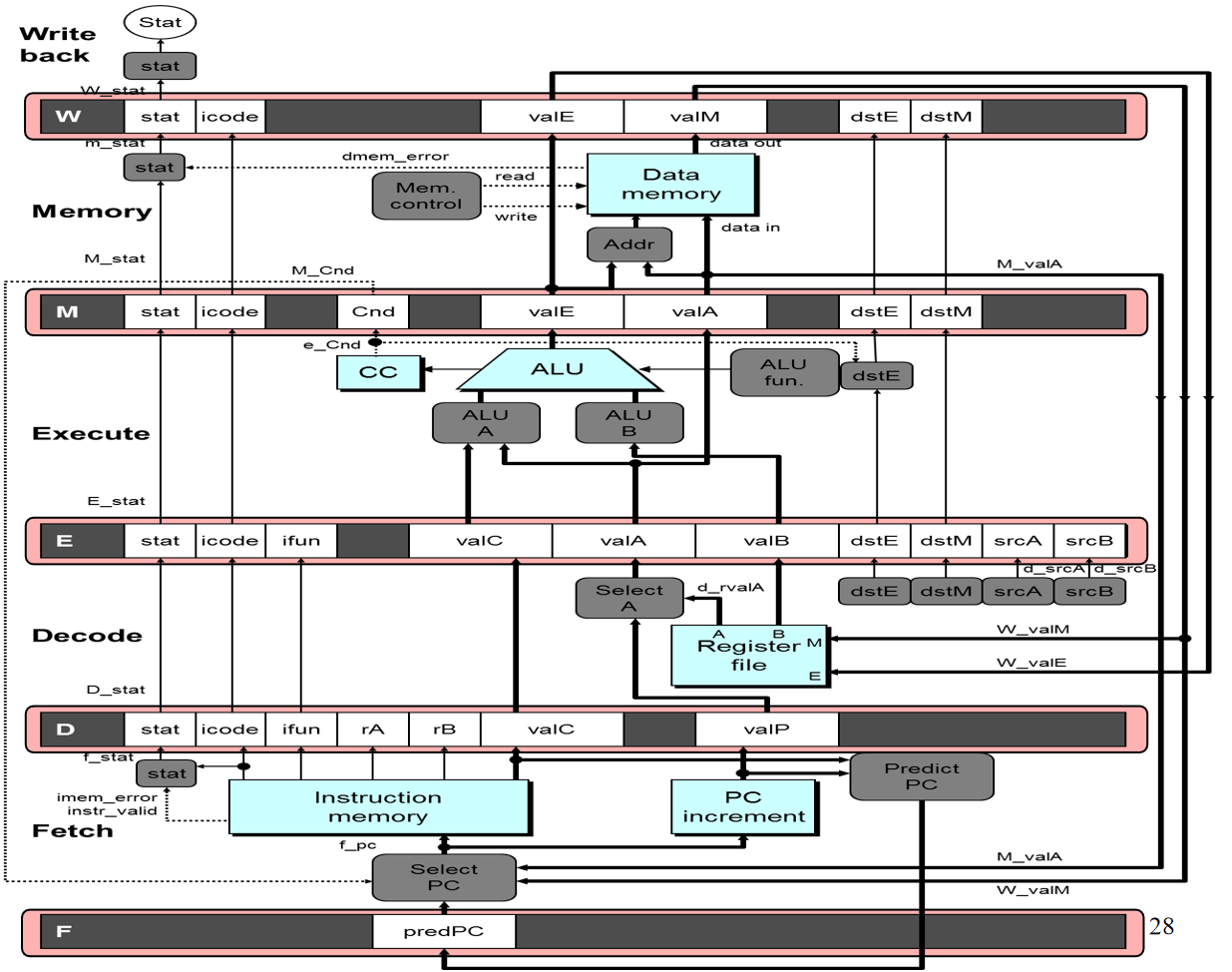
- Forward Paths
Values passed from one stage to next(不能跳过某一阶段)
- Feedback Paths
PC Updates需要根据指令的类型,可能需要其他阶段的执行结果来决定next PC
Register Updates需要等Write Back阶段结束后才能将信号拉回来
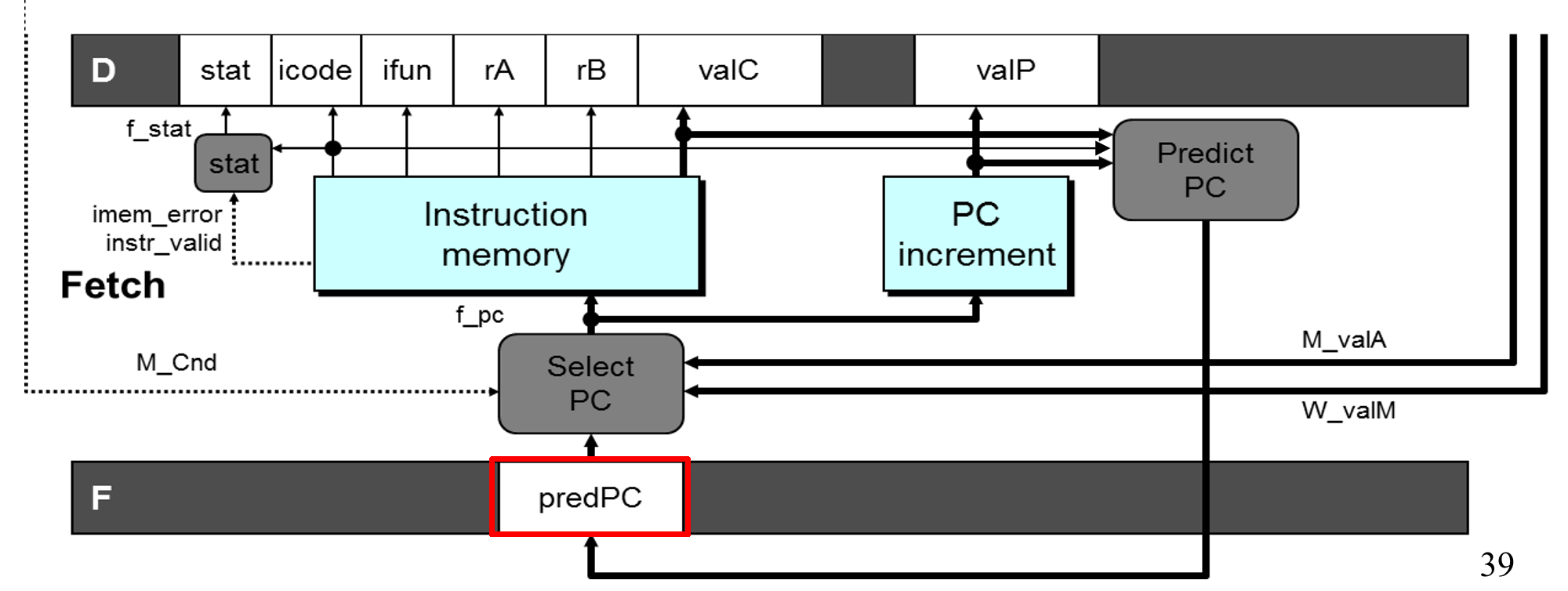
- 预测PC
当前指令执行完fetch阶段后就会开始fetch新的指令,没办法可靠地决定新的指令的PC,因此需要先猜测一个PC值,如果猜错了后面再恢复。
What is our prediction strategy?
- Instructions that don't transfer control, always
next PC = valP - Call and Unconditional Jumps, always
next PC = valC - Conditional jumps, predict
next PC = valC, only correct if branch is taken(一般正确率在60%) - Return Instruction, don't try to predict
1 | |
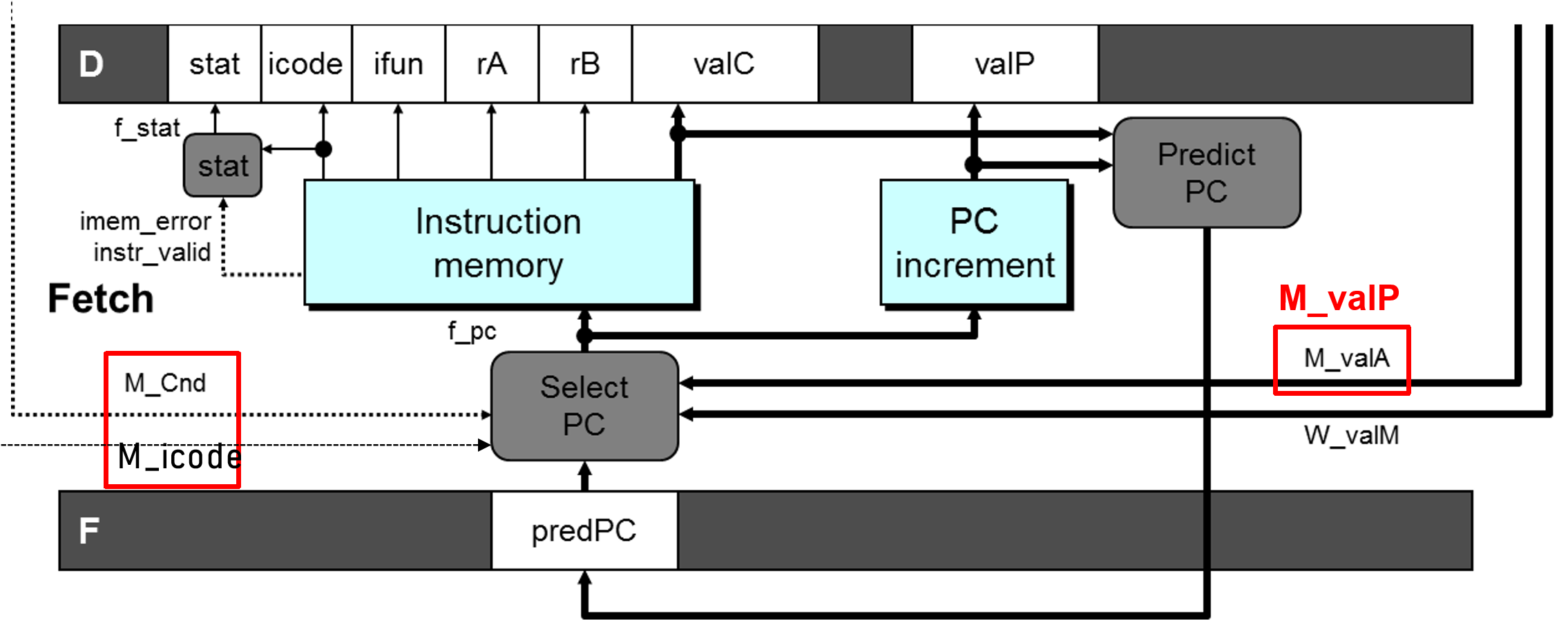
Recover from PC misprediction:
1 | |
Hazard
Pipeline比起SEQ会带来Hazard的问题:
- Data Hazard: 前一条指令修改某个寄存器,还没来得及将结果写入Register FIile, 后一条指令就需要读这个寄存器。这种情况在代码中非常普遍
- Control Hazard: jXX指令要根据前一条指令的ALU运算结果设置的CC才能确定下一条指令的PC
Data Hazard
- Naive Solution 1:
nop
最Naive的解决方案是在两条相互依赖的指令之间插nop指令(编译器可以分析你的代码,然后帮你做到这一点)。
- Naive Solution 2: Stalling
在cpu内部解决,将指令停在decode阶段,(每个cycle)都往上(execution阶段)插入bubble。
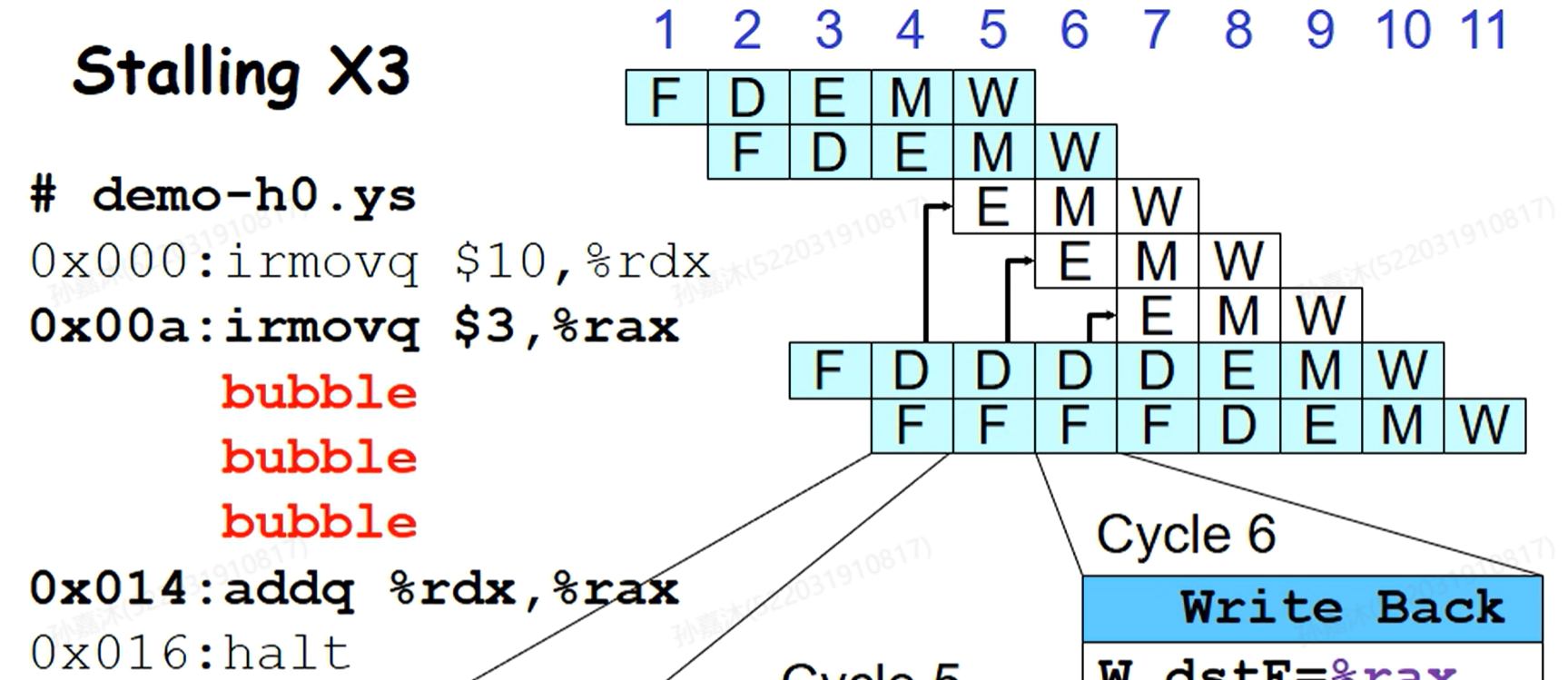
但是这两种解决方案Pipeline的效果就变差了,因为相互依赖的指令在实际代码中非常普遍。
有没有什么办法可以减少nop/bubble的插入?
- Data Forwarding
我们其实可以把我们要的数据提前拉过来,而不一定要等上一条指令最后Write Back阶段结束后再从寄存器读出来。这种实现技术就叫Data Forwarding
可以在decode阶段,加一个选择器。如果出现data dependency情况,就从later stage拉回来的信号取值,否则就正常从Register File中取值。
什么时候可以从later stage里将信号拉回来取决于指令的类型,如果是从寄存器/立即数写入寄存器(irmovq, rrmovq),那么可以在execute阶段结束将e_valE拉回来,如果是要从memory中写入寄存器(mrmovq),那要在memory阶段结束将m_valM拉回来。
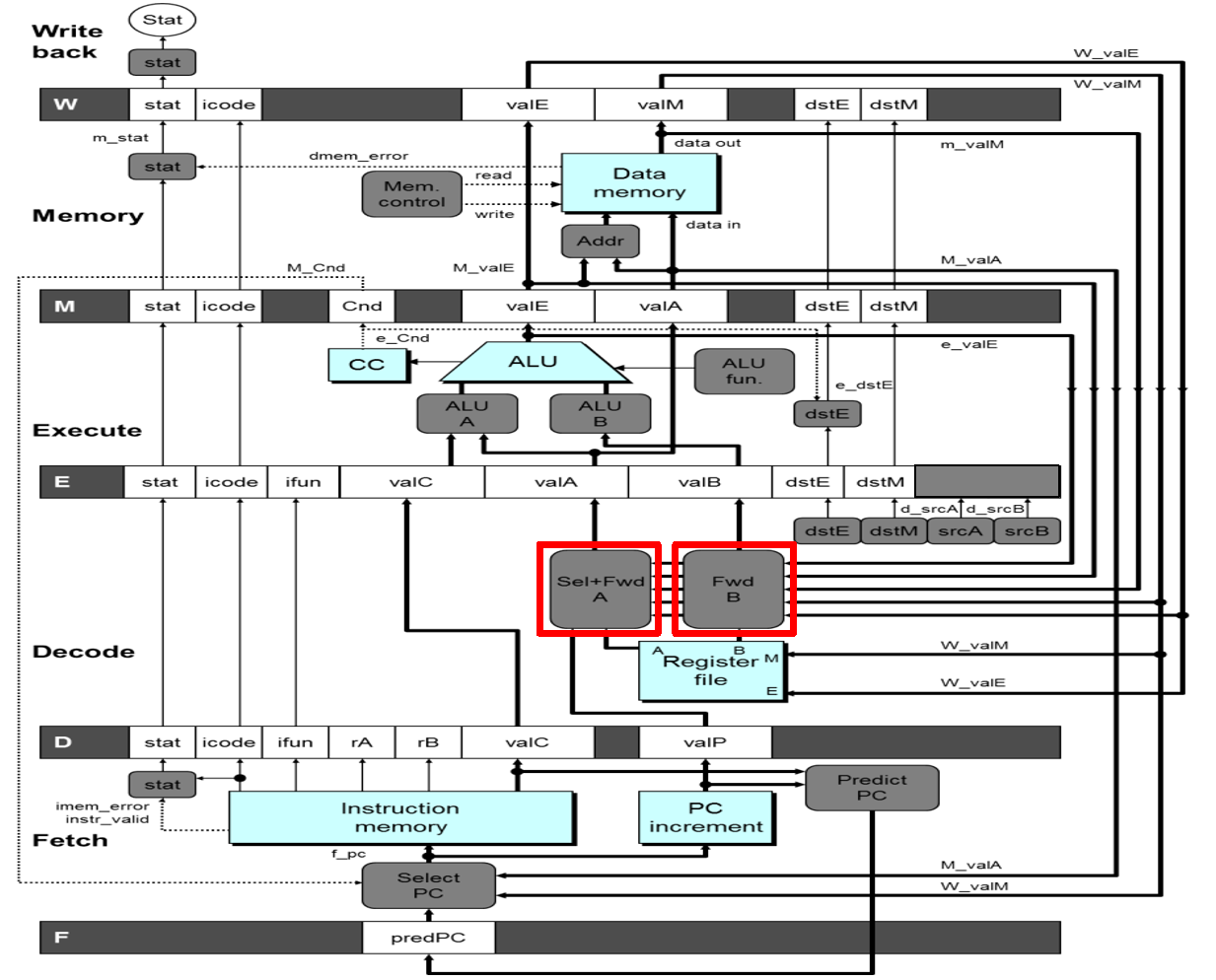
Control Hazard
前面一条指令会改变执行流。因此我们需要猜测后一条指令的地址(PC Prediction)。
ret
对于ret指令,我们无法猜测后一条指令的地址,因此需要采取前面提到的Stalling技术,在fetch阶段将指令截停:
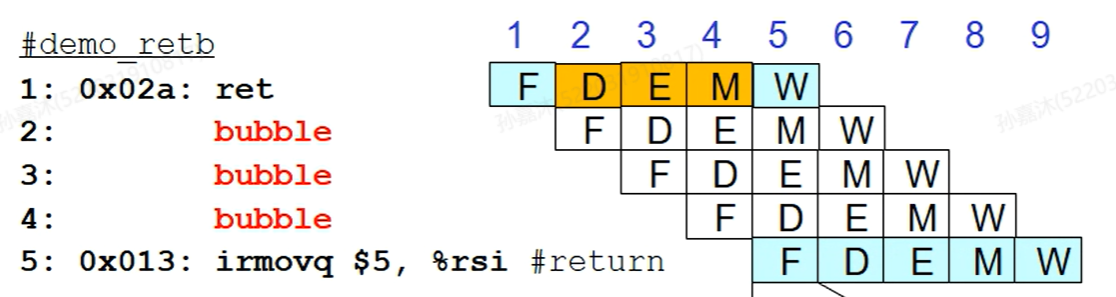
一个return就要插入三个bubble,所以其实return对于pipeline的overhead是比较大的。
jXX
对于jump指令,我们猜测他会跳转:next PC = valC。那如果猜错了怎么办呢?
最Naive的方式就是在跳转处插入两个nop,这样无论猜没猜错都不需要擦除任何指令。但是这样跟不猜PC没区别了。
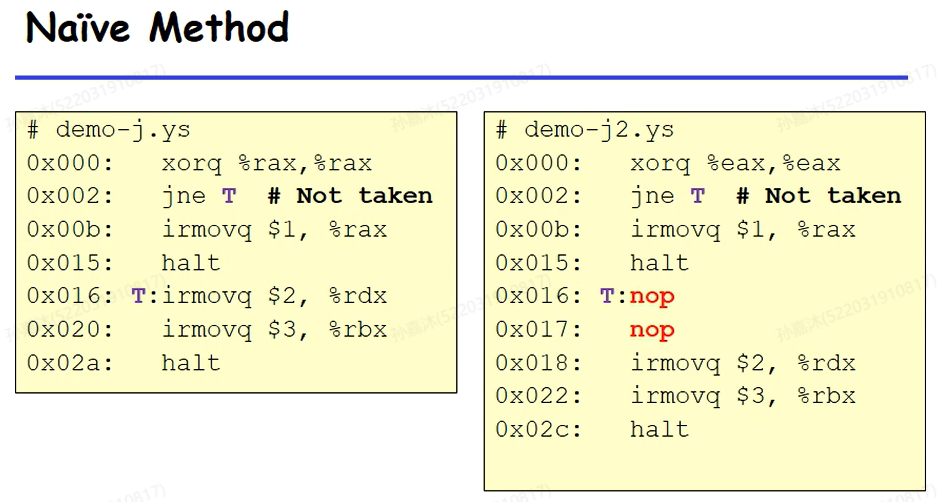
因此我们的解决方案是让跳转后的指令先执行,如果发现猜错了,就将执行的指令的icode改为nop(变成bubble)。通常情况下,跳转后执行的两条指令在decode和execute阶段不会修改状态(只有在execute阶段末尾才会修改CC)。因此我们可以做到在指令修改CC前及时将其擦除掉,不会产生程序员可见的状态修改。
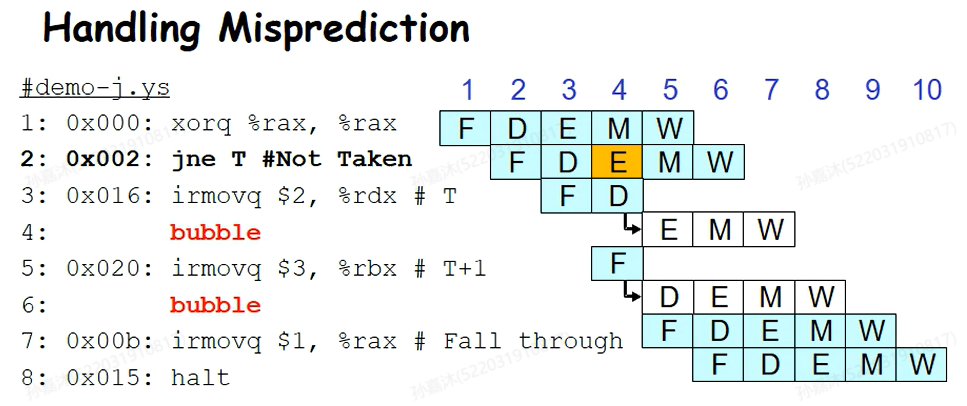
但是如果跳转后执行的指令本身是错误的指令呢?这两条指令本身就不该执行,但由于我们猜错了PC,这两条错误的指令执行的时候就会修改Program Status。

我们需要专门的mechanism来处理执行流中遇到的错误,以能够避免上述情况。
Exception Handling
y86中的异常类型:
- Invalid address
- Invalid instruction
- Halt
正常执行流中遇到了异常,就需要exception handling。对y86来说,exception handling需要做到的是:program在遇到异常后停在正确的状态下,异常的指令停在当前位置,异常指令前的指令正常执行完,异常指令后的指令不执行。
exception handling遇到的困难是:指令可能在流水线的不同阶段检测到异常。

如何让异常前的指令正常执行完呢?我们的解决方案是:在指令遇到异常的阶段,先将status写入pipeline register,然后将指令变为nop,当作无事发生继续执行,如果指令到Write Back了status依然是异常,那么此时再处理。注意对于因为分支预测错误执行的指令来说,应当在发现预测错误后擦除状态(将status改回成OK)。

如何保证异常指令后面的指令不会产生效果(修改状态)?当一条指令来到Memory阶段status是异常,说明该指令一定是异常指令(后续Write Back的时候会处理),此时Memory及时关闭肯定来得及,但CC呢?只要在Memory阶段发现错误时立即关闭CC,就可以保证在后一条指令执行完execute前CC就被关闭了,所以也来得及!
Pipe CPU Implementation
PIPE Stage Implementations
- Fetch
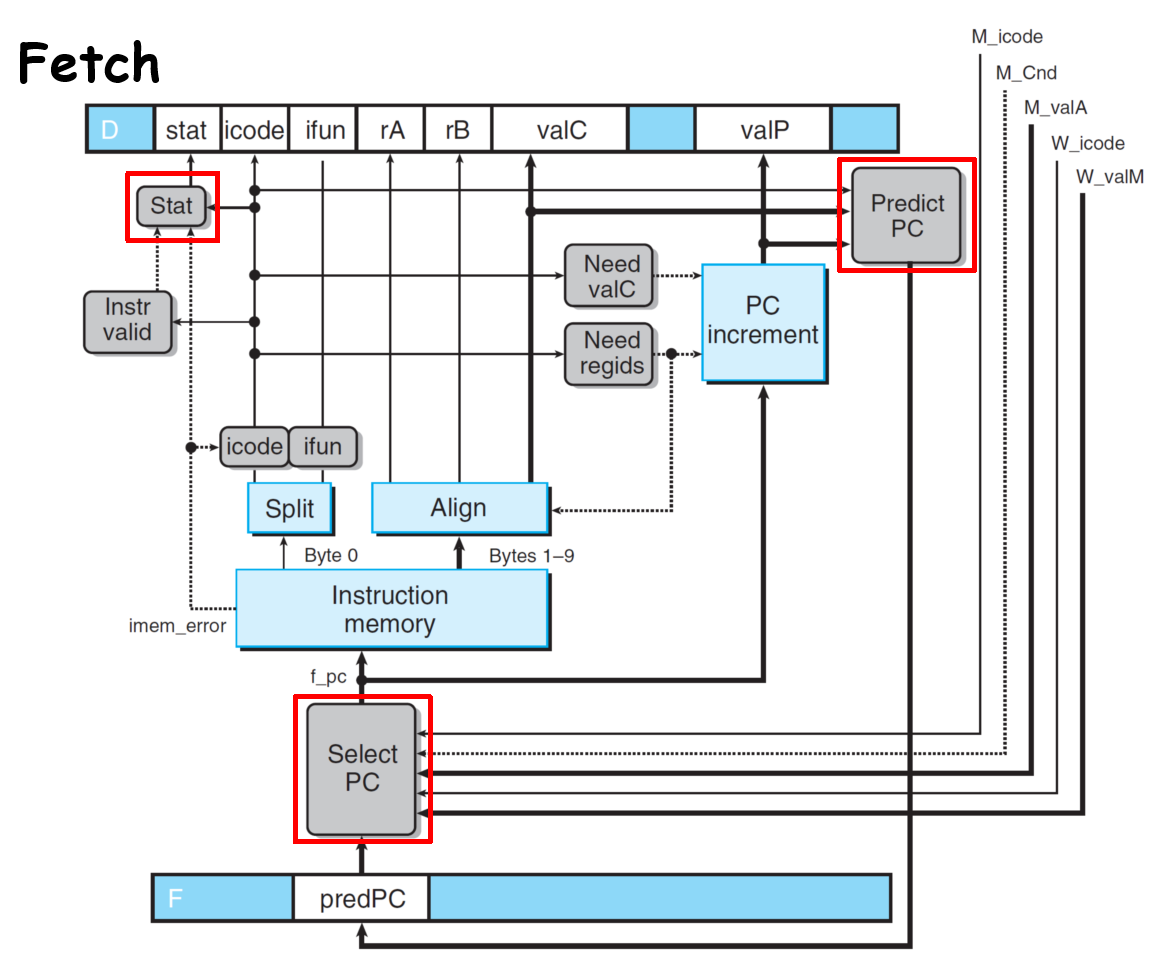
对于设置status来说:
先取指令的地址,如果地址错误设置为SADR;再检查指令的icode,如果icode无效设置为SINS;再看icode是否为halt,如果是则设置为SHLT;如果都没发生,就设置为SAOK。
1 | |
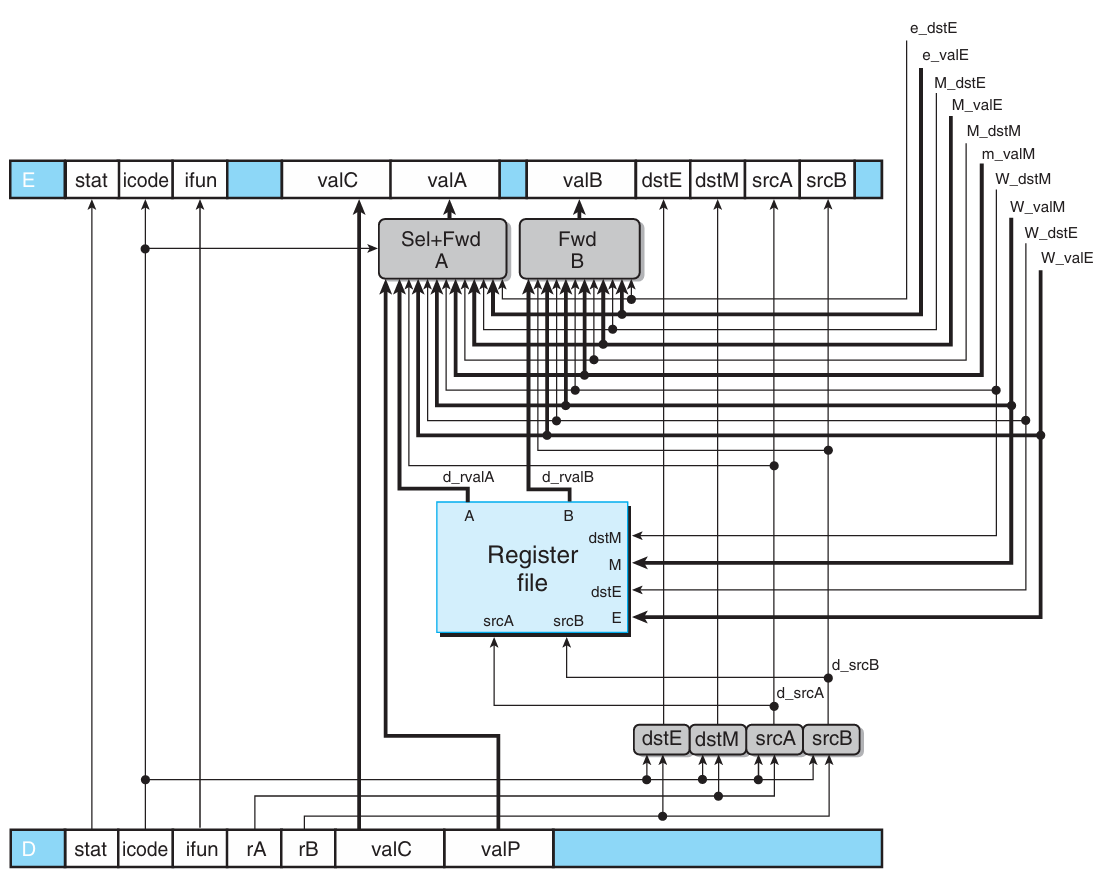
- Decode and Write-Back
Forwarding Logic: The Order Matters!
对于Write Back阶段,需要将bubble的status设置为OK:
1 | |
- Execute
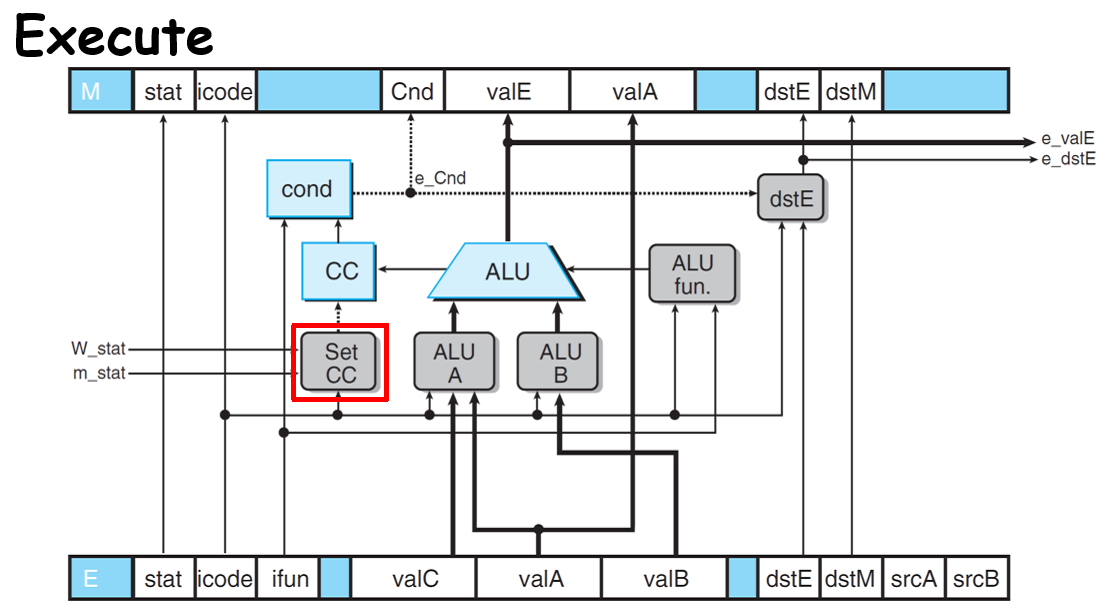
需要检查能否修改CC:
1 | |
- Memory
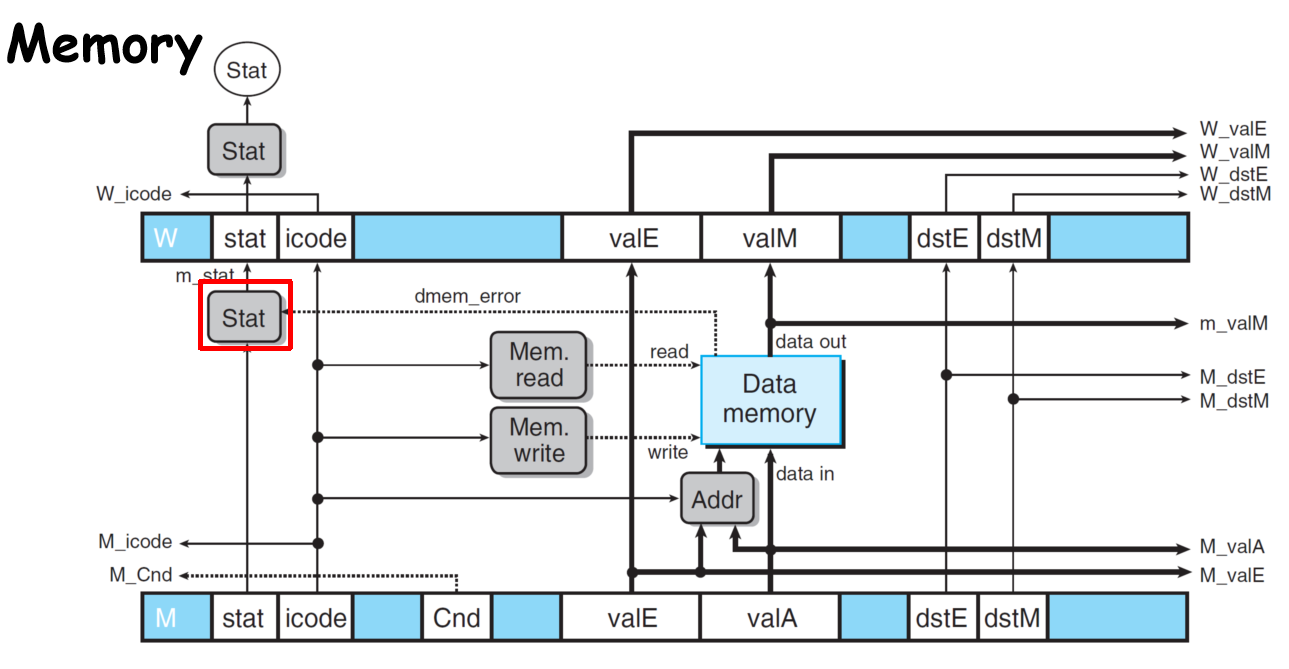
如果访问地址出错,需要设置status:
1 | |
Pipeline Control Logic
Pipeline中有一些情况仅靠data forwarding和branch prediction无法解决。
- Load/Use Hazard
Load指从memory写到register,Use指用到这个register。光用Forwarding来不及。
前一条指令要写的寄存器是后一条指令要读的寄存器:

需要在Fetch和Decode阶段插stall,在execute阶段插一个bubble。
- Mispredicted Branch

jump指令去到了Memory,需要将decode和execute阶段的两条指令一起擦成bubble。
- Return
不预测PC,需要在Fetch阶段插入stall,在decode阶段连续插入三次bubble。
- Exception
发现异常后在Write Back阶段插入stall,将错误指令停在Write Back阶段。在Memory阶段插入bubble。
Performance Analysis
Performance Metrics
- Clock Rate
- CPI (cycles per instruction)
理想情况下CPI = 1,但是流水线有时需要插入bubble,有时需要stall。
$ CPI = C/I = (I+B)/I = 1.0 + B/I $
B/I就是流水线设计的overhead。
Modern Processor
前面的流水线设计一个cycle最多执行一条指令。但是如果指令之间没有依赖关系,其实可以并行执行。Modern Processor有更多的硬件资源和指令分析能力,能够支持指令的并行执行。
-
Superscalar:每个clock cycle并行执行多条操作。
-
Out-of-order execution(乱序执行)
现代处理器主要由以下两部分组成:
- Instruction Control Unit (ICU)
- Execution Unit (EU)
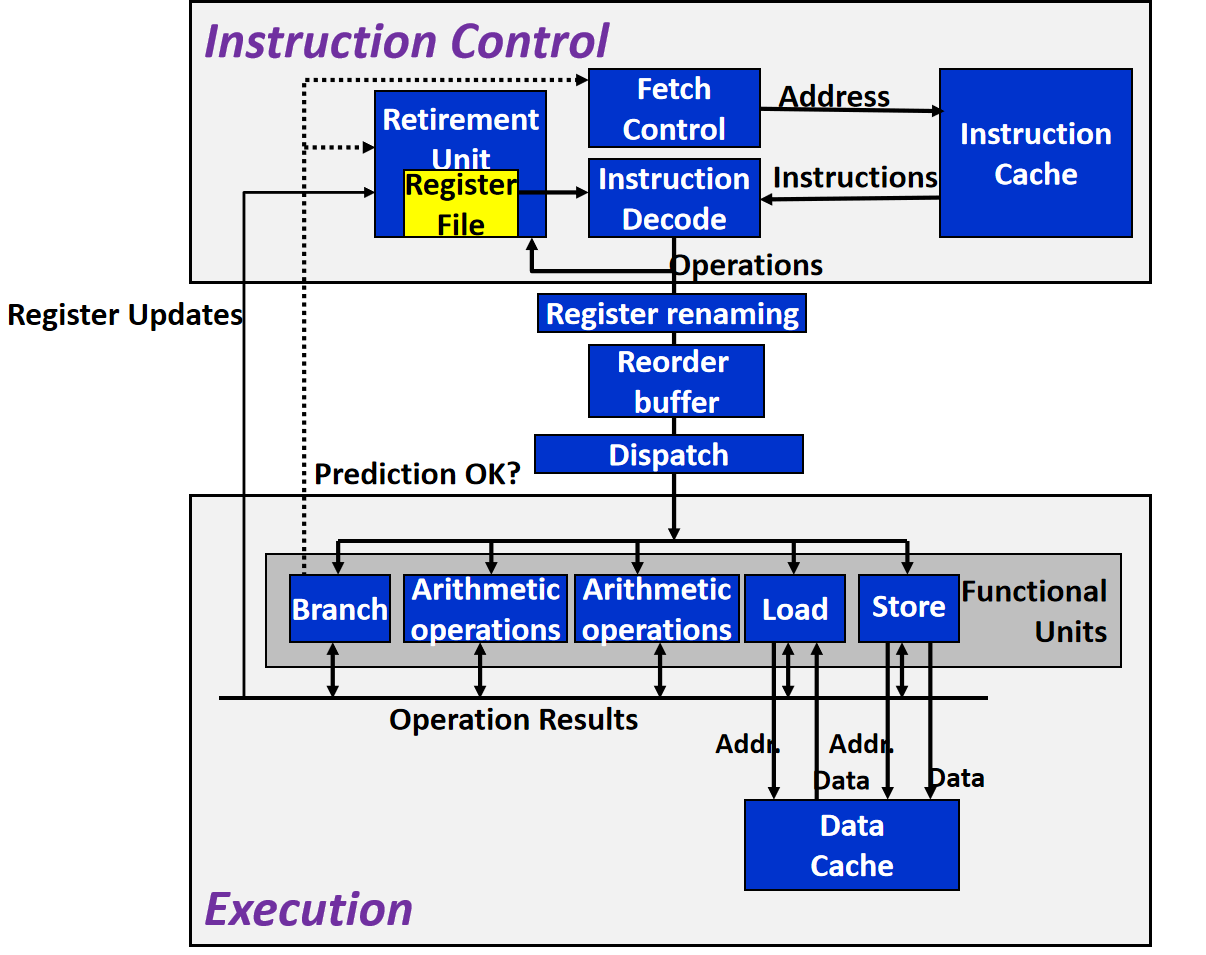
ICU中的Fetch Control负责从Instruction Cache中读取指令。
ICU中的Instruction Decode负责将上层指令分解为primitive operations(微指令)
比如:

EU是Multi-functional Units,指令可以并行。每个functional unit可能是pipelined的。
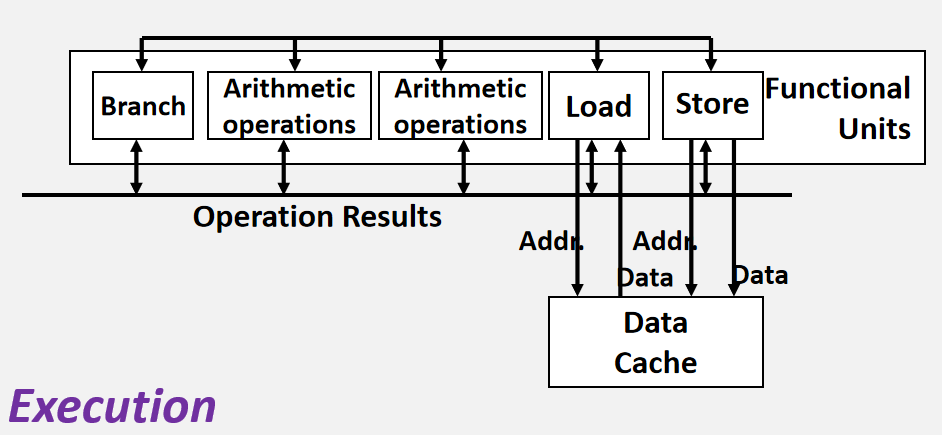
每个functional unit执行完产生的结果会放到总线上,在所有function units间共享,这就是现代处理器的data forwarding技术。
Reorder buffer根据上层register renaming操作的结果,判断指令的依赖关系,将重新排序的指令交给Dispatch,Dispatch负责将不同的指令交给不同的functional unit执行。