Formatting Input/Output using IO Manipulators (Header )
1
#include<iomanip>// Needed to do formatted I/O
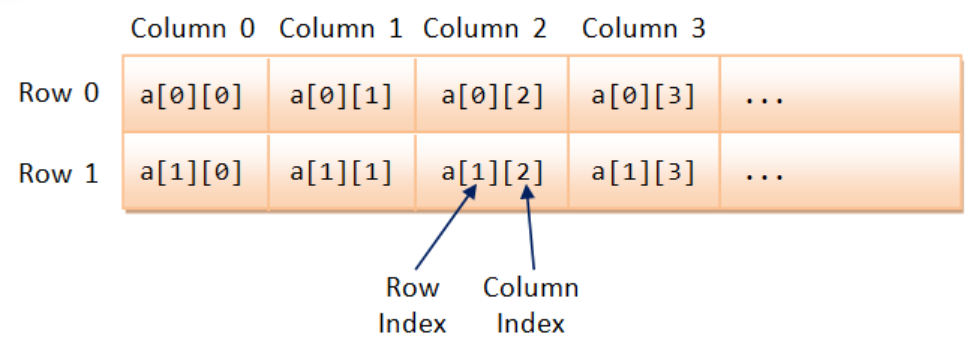
Multi-Dimensional Array
For 2D array (table), the first index is the row number, second index is the column number.
The elements are stored in a so-called row-major manner, where the column index runs out first.
Array is passed into function by reference. That is, the invoked function works on the same copy of the array as the caller.
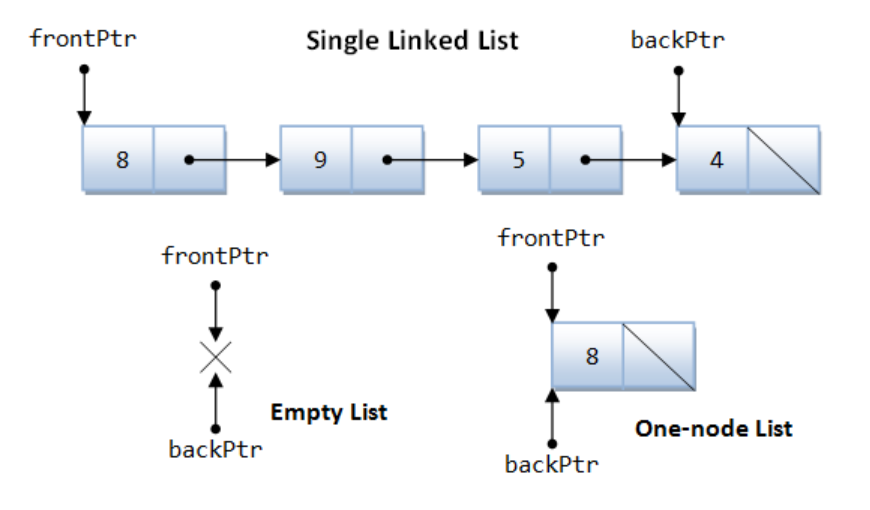
Sorting Algorithm
Bubble sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// Sort the given array of size voidbubbleSort(int a[], int size){ bool done = false; // terminate if no more swap thru a pass int temp; // use for swapping
while (!done) { done = true; // Pass thru the list, compare adjacent items and swap // them if they are in wrong order for (int i = 0; i < size - 1; ++i) { if (a[i] > a[i+1]) { temp = a[i]; a[i] = a[i+1]; a[i+1] = temp; done = false; // swap detected, one more pass } } } }
// Sort the given array of size using insertion sort voidinsertionSort(int a[], int size){ int temp; // for shifting elements for (int i = 1; i < size; ++i) { // For element at i, insert into proper position in [0, i-1] // which is already sorted. // Shift down the other elements for (int prev = 0; prev < i; ++prev) { if (a[i] < a[prev]) { // insert a[i] at prev, shift the elements down temp = a[i]; for (int shift = i; shift > prev; --shift) { a[shift] = a[shift-1]; } a[prev] = temp; break; } } } }
Selection sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Sort the given array of size using selection sort voidselectionSort(int a[], int size){ int temp; // for swapping for (int i = 0; i < size - 1; ++i) { // [0, i-1] already sort // Search for the smallest element in [i, size-1] // and swap with a[i] int minIndex = i; // assume fist element is the smallest for (int j = i + 1; j < size; ++j) { if (a[j] < a[minIndex]) minIndex = j; } if (minIndex != i) { // swap temp = a[i]; a[i] = a[minIndex]; a[minIndex] = temp; } } }
Namespace
To place an entity under a namespace, use keyword namespace as follow:
1 2 3 4 5 6 7 8 9 10 11
// create a namespace called myNamespace for the enclosed entities namespace myNameSpace { int foo; // variable intf(){ ...... }; // function classBar { ...... }; // compound type such as class and struct }
// To reference the entities, use myNameSpace::foo myNameSpace::f() myNameSpace::Bar
Enumeration (enum)
1 2 3 4 5 6 7
enumColor { RED, GREEN, BLUE } myColor; // Define an enum and declare a variable of the enum ...... myColor = RED; // Assign a value to an enum Color yourColor; yourColor = GREEN;
Ellipses (...)
Ellipses (...) can be used as the last parameter of a function to denote zero or more arguments of unknown type.
// Ellipses are accessed thru a va_list va_list lst; // Declare a va_list // Use function va_start to initialize the va_list, // with the list name and the number of parameters. va_start(lst, count); for (int i = 0; i < count; ++i) { // Use function va_arg to read each parameter from va_list, // with the type. sum += va_arg(lst, int); } // Cleanup the va_list. va_end(lst);
// Examples double (*fp)(int, int) // fp points to a function that takes two ints and returns a double (function-pointer) double *dp; // dp points to a double (double-pointer) double *fun(int, int)// fun is a function that takes two ints and returns a double-pointer doublef(int, int); // f is a function that takes two ints and returns a double fp = f; // Assign function f to fp function-pointer
/* Test Function Pointers (TestFunctionPointer.cpp) */ #include<iostream> usingnamespace std;
intarithmetic(int, int, int (*)(int, int)); // Take 3 arguments, 2 int's and a function pointer // int (*)(int, int), which takes two int's and return an int intadd(int, int); intsub(int, int);
intadd(int n1, int n2){ return n1 + n2; } intsub(int n1, int n2){ return n1 - n2; }
intarithmetic(int n1, int n2, int (*operation) (int, int)){ return (*operation)(n1, n2); }
A const member function, identified by a const keyword at the end of the member function's header, cannot modifies any data member of this object. For example,
1 2 3 4 5
doublegetRadius()const{ // const member function radius = 0; // error: assignment of data-member 'Circle::radius' in read-only structure return radius; }
Constructor's Member Initializer List
1
Circle(double r = 1.0, string c = "red") : radius(r), color(c) { }
Object data member shall be constructed via the member initializer list, not in the body.
The default copy constructor performs shadow copy. It does not copy the dynamically allocated data members created via new or new[] operator.
1 2 3 4 5 6 7 8 9 10 11 12
classMyClass { private: T1 member1; T2 member2; public: // The default copy constructor which constructs an object via memberwise copy MyClass(const MyClass & rhs) { member1 = rhs.member1; member2 = rhs.member2; } ...... }
1 2 3
// Default copy constructor of Author class provided by C++ Author::Author(const Author& other) : name(other.name), email(other.email), gender(other.gender) { } // memberwise copy
Copy Assignment Operator
The default copy assignment operator performs shadow copy. It does not copy the dynamically allocated data members created via new or new[] operator.
The copy constructor, instead of copy assignment operator, is used in declaration:
1 2
Circle c8 = c6; // Invoke the copy constructor, NOT copy assignment operator // Same as Circle c8(c6)
The copy assignment operator has the following signature:
1 2 3 4 5 6 7 8 9 10 11 12 13
classMyClass { private: T1 member1; T2 member2; public: // The default copy assignment operator which assigns an object via memberwise copy MyClass & operator=(const MyClass & rhs) { member1 = rhs.member1; member2 = rhs.member2; return *this; } ...... }
You could overload the assignment operator to override the default.
Why do we use const classname &?
The pass-by-reference prevents the large copy cost by pass-by-value, while keeping the values of the members in rhs unchanged.
The default copy constructor and assignment operator are both shadow copy.
If you use new (or new[]) to dynamically allocate memory in the constructor to object data member pointers, you should define a copy constructor and assignment operator that deep copies one object into another.
/* Test Driver for the Time class (TestTime.cpp) */ #include<iostream> #include<stdexcept>// Needed for exception handling #include"Time.h" usingnamespace std;
intmain(){ // Time t2(25, 0, 0); // program terminates abruptly // t2.print(); // The rest of program will not be run
// Graceful handling of exception try { Time t1(25, 0, 0); // Skip the remaining statements in try-clause an jump to catch-clause if an exception is thrown t1.print(); // Continue to the next statement after try-catch, if there is no exception } catch (invalid_argument& ex) { // need <stdexcept> cout << "Exception: " << ex.what() << endl; // Continue to the next statement after try-catch } cout << "Next statement after try-catch" << endl; }
// A static function that returns true if the given year is a leap year boolDate::isLeapYear(int year){ return ((year % 4 == 0 && year % 100 != 0) || (year % 400 == 0)); }
// A static function that returns true if the given y, m, d constitutes a valid date boolDate::isValidDate(int y, int m, int d){ if (y >= YEAR_MIN && y <= YEAR_MAX && m >= 1 && m <= 12) { int lastDayOfMonth = DAYS_IN_MONTHS[m-1]; if (m == 2 && isLeapYear(y)) { lastDayOfMonth = 29; } return (d >= 1 && d <= lastDayOfMonth); } else { returnfalse; } }
// A static function that returns the day of the week (0:Sun, 6:Sat) for the given date // Wiki "Determination of the day of the week" for the algorithm intDate::getDayOfWeek(int y, int m, int d){ int centuryTable[] = {4, 2, 0, 6, 4, 2, 0, 6}; // 17xx, 18xx, ... int MonthTable[] = {0, 3, 3, 6, 1, 4, 6, 2, 5, 0, 3, 5}; int MonthLeapYearTable[] = {6, 2, 3, 6, 1, 4, 6, 2, 5, 0, 3, 5};
int century = y / 100; int twoDigitYear = y % 100; int centuryTableIndex = (century - 17) % 8; // Date before 17xx are not valid, but needed to prevent negative index if (centuryTableIndex < 0) { centuryTableIndex += 8; } int sum = centuryTable[centuryTableIndex] + twoDigitYear + twoDigitYear / 4; if (isLeapYear(y)) { sum += MonthLeapYearTable[m-1]; } else { sum += MonthTable[m-1]; } sum += d; return sum % 7; }
A private member is accessible within the class by member functions and by friends of that class.
A public member is accessible by all.
A protected member can be accessed by itself and its friend, as well as its subclasses and their friends.
Inheritance Access Specifier:
public-inheritance(most common): public members in the superclass becomes public members in the derived class; protected members in the base class become protected member in the derived class.
protected-inheritance: public and protected members in the base class become protected members in the derived class.
private-inheritance: public and protected members in the base class become private member in the derived class.
When the subclass construct its instance, it must first construct a superclass object, which it inherited.
Polymorphism
One interface, multiple implementations. Use virtual functions.
Polymorphism works on object pointers and references using so-called dynamic binding at run-time.
Does not work on regular objects, which uses static binding during the compile-time:
1 2 3 4
// Using object with explicit constructor Point p3 = MovablePoint(31, 32, 33, 34); // upcast p3.print(); // Point @ (31,32) - Run superclass version!! cout << endl;
Virtual Functions: To implement polymorphism, we need to use the keyword virtual for functions that are meant to be polymorphic.
It is recommended that functions to be overridden in the subclass be declared virtual in the superclass.
Constructor can't be virtual, because it is not inherited. Subclass defines its own constructor, which invokes the superclass constructor to initialize the inherited data members.
Destructor should be declared virtual, if a class is to be used as a superclass, so that the appropriate object destructor is invoked to free the dynamically allocated memory in the subclass, if any.
If you override function in the subclass, the overridden function shall have the same parameter list as the superclass' version.
Pure Virtual Function
1
virtualdoublegetArea()= 0; // Pure virtual function, to be implemented by subclass
The =0 simply make the class abstract. As the result, you cannot create instances.
const object cannot invoke non-const member function
const data member can only be initialized by the constructor using member initializer list
friend function and friend class
friend function
Friend functions are declared inside the class and are implemented outside the class.
Friend functions are not the members of the class, but their arguments of the class can access all class members.
Friend functions will not be inherited by the subclass. Friends can't be virtual, as friends are not class member.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
classPoint { // A friend function defined outside this class, but its argument of // this class can access all class members (including private members). friendvoidset(Point & point, int x, int y); // prototype private: int x, y; public: Point(int x = 0, int y = 0) : x(x), y(y) { } voidprint()const{ cout << "(" << x << "," << y << ")" << endl; } };
// Friend function is defined outside the class voidset(Point & point, int x, int y){ point.x = x; // can access private data x and y point.y = y; }
friend class
To declare all member functions of a class (says Class1) friend functions of another class (says Class2), declared "friend class Class1;" in Class2.
Operator Overloading
User-defined Operator Overloading
operator function:
1
return-type operatorΔ(parameter-list)
Example:
1 2 3 4 5
// Member function overloading '+' operator const Point Point::operator+(const Point & rhs) const { returnPoint(x + rhs.x, y + rhs.y); // Return by value as local variable cannot be returned by reference }
Usage:
p1 + p2 = p1.operator+(p2)
1 2 3 4 5 6 7
// Invoke via usual dot syntax, same as p1+p2 Point p4 = p1.operator+(p2); p4.print(); // (5,7)
The overloaded >> and << can also be used for file input/output, as the file IO stream ifstream/ofstream (in fstream header) is a subclass of istream/ostream.
classCounter { private: int count; public: Counter(int c = 0) : count(c) { } // A single-argument Constructor which takes an int // It can be used to implicitly convert an int to a Counter object intgetCount()const{ return count; } // Getter voidsetCount(int c){ count = c; } // Setter };
intmain(){ Counter c1; // Declare an instance and invoke default constructor cout << c1.getCount() << endl; // 0
c1 = 9; // Implicit conversion // Invoke single-argument constructor Counter(9) to construct a temporary object. // Then copy into c1 via memberwise assignment. cout << c1.getCount() << endl; // 9 }
To disable implicit conversion, use keyword "explicit". Nonetheless, you can still perform explicit conversion via type cast operator.
Although implicit conversion is disabled using keyword "explicit", we can still use explicit conversion via type casting.
1
c1 = (Counter)9; // Explicit conversion via type casting
classCounter { private: int count; public: explicitCounter(int c = 0) : count(c) { } // Single-argument Constructor // Use keyword "explicit" to disable implicit automatic conversion in assignment intgetCount()const{ return count; } // Getter voidsetCount(int c){ count = c; } // Setter };
intmain(){ Counter c1; // Declare an instance and invoke default constructor cout << c1.getCount() << endl; // 0
// Counter c2 = 9; // error: conversion from 'int' to non-scalar type 'Counter' requested
c1 = (Counter)9; // Explicit conversion via type casting operator cout << c1.getCount() << endl; // 9 }
Dynamic Memory Allocation in Object
If you dynamically allocate memory in the constructor, you need to provide your own destructor, copy constructor and assignment operator to manage the dynamically allocated memory. The defaults provided by the C++ compiler do not work for dynamic memory.
template <typename T> voidmySwap(T &a, T &b); // Template
template <> voidmySwap<int>(int &a, int &b); // Explicit Specialization for type int
template <typename T> voidmySwap(T &a, T &b){ cout << "Template" << endl; T temp; temp = a; a = b; b = temp; }
template <> voidmySwap<int>(int &a, int &b) { cout << "Specialization" << endl; int temp; temp = a; a = b; b = temp; }
If there is any non-template definition that matches the function call. The non-template version will take precedence over explicit specialization, then template.
/* * The MyComplex template class header (MyComplex.h) * All template codes are kept in the header, to be included in program * (Follow, modified and simplified from GNU GCC complex template class.) */ #ifndef MY_COMPLEX_H #define MY_COMPLEX_H
// Overloading + operator for c + double friendconst MyComplex<T> operator+ (const MyComplex<T> & lhs, T value) { MyComplex<T> result(lhs); result += value; // uses overload += return result; }
// Overloading + operator for double + c friendconst MyComplex<T> operator+ (T value, const MyComplex<T> & rhs) { return rhs + value; // swap and use above function } };
// Overload prefix increment operator ++c template <typename T> MyComplex<T> & MyComplex<T>::operator++ () { ++real; // increment real part only return *this; }
// Overload postfix increment operator c++ template <typename T> const MyComplex<T> MyComplex<T>::operator++ (int dummy) { MyComplex<T> saved(*this); ++real; // increment real part only return saved; }
/* Definition of friend functions */
// Overload stream insertion operator out << c (friend) template <typename T> std::ostream & operator<< (std::ostream & out, const MyComplex<T> & c) { out << '(' << c.real << ',' << c.imag << ')'; return out; }
// Overload stream extraction operator in >> c (friend) template <typename T> std::istream & operator>> (std::istream & in, MyComplex<T> & c) { T inReal, inImag; char inChar; bool validInput = false; // Input shall be in the format "(real,imag)" in >> inChar; if (inChar == '(') { in >> inReal >> inChar; if (inChar == ',') { in >> inImag >> inChar; if (inChar == ')') { c = MyComplex<T>(inReal, inImag); validInput = true; } } } if (!validInput) in.setstate(std::ios_base::failbit); return in; }
#endif
Why do we need a <> when we declare operator function <</>> inside the class? When do we need a forward declaration of a friend function?
When the compiler sees a declaration with <>, it knows this is a specialization version of a template function. The compiler will then look for the corresponding forward declaration of the template function. This is why we also need a forward declaration of the operator function <</>>: this is a template function.
The declaration without <> simply tells the compiler this is an ordinary non-template function, which does not need a forward declaration.
// Situation2: not using <> friendvoidprintComplex(const MyComplex<T>& c); };
/* Definition of friend functions */
// Overload stream insertion operator out << c (friend) template <typename T> std::ostream & operator<< (std::ostream & out, const MyComplex<T> & c) { out << '(' << c.real << ',' << c.imag << ')'; return out; }
What if a member function of a template class is defined outside the class?
When a member function of a template class is defined outside the class, we need to use keyword template <typename T> on the function implementation.
For example:
1 2 3 4 5 6 7 8
// Declared inside the template class MyComplex // Defined outside the class // Overload prefix increment operator ++c template <typename T> MyComplex<T> & MyComplex<T>::operator++ () { ++real; // increment real part only return *this; }
Characters and Strings
Strings: The C-String and the string class
C-String Literals
1 2 3
char * str1 = "hello"; // warning: deprecated conversion from string constant to 'char*' char * str2 = const_cast<char *>("hello"); // remove the "const"
Those two statements are dangerous. String literal "hello" is stored in read-only memory. Now you assign a non-const pointer to point to this area. If you try to modify this string literal, it will crash your program.
Stream extraction operator does not discard the trailing whitespace(blank, tab, newline), and leave it in the input buffer.
1 2 3 4 5 6 7
constint SIZE = 5; char str[SIZE]; // max strlen is SIZE - 1
cout << "Enter a word: "; // Extract SIZE-1 characters at most cin >> setw(SIZE) >> str; // need <iomanip> header cout << str << endl;
You may need to flush the input buffer:
1 2 3 4 5
// Ignore to the end-of-file cin.ignore(numeric_limits<streamsize>::max()); // need header <limits>
// Ignore to the end-of-line cin.ignore(numeric_limits<streamsize>::max(), '\n');
istream::getline()
The delimiter, if found, is extracted and discarded from input stream.
If n-1 character is read and the next character is not delimit, then the failbit (of the istream) is set. You can check the failbit via bool function cin.fail(). You need to clear the error bits before issuing another getline() call.
1 2 3 4 5 6 7 8 9 10 11 12
constint SIZE = 5; char str[SIZE]; // max strlen is SIZE - 1
cout << "Enter a line: "; cin.getline(str, SIZE); // Read a line (including whitespaces) until newline, discard newline cout << "\"" << str << "\" length=" << strlen(str) << endl; cout << "Number of characters extracted: " << cin.gcount() << endl;
if (cin.fail()) { cout << "failbit is set!" << endl; cin.clear(); // Clear all error bits. Otherwise, subsequent getline() fails }
istream::get()
get(str, n, delim) is similar to getline(str, n, delim), except that the delim character is not extracted and remains in the input stream.
C++ Standard Libraries and Standard Template Library (STL)
Sequence Containers, Associative Containers and Adapters
STL provides the following types of containers:
Sequence Containers: linear data structures of elements
vector: dynamically resizable array.
deque: double-ended queue.
list: double-linked list.
Associative Containers: nonlinear data structures storing key-value pairs
set: No duplicate element. Support fast lookup.
multiset: Duplicate element allowed. Support fast lookup.
map: One-to-one mapping (associative array) with no duplicate. Support fast key lookup.
multimap: One-to-many mapping, with duplicates allowed. Support fast key lookup.
Container Adapter Classes:
Stack: Last-in-first-out (LIFO) queue, adapted from deque (default), or vector, or list. Support operations back, push_back, pop_back.
queue: First-in-first-out (FIFO) queue, adapted from deque (default), or list. Support operations front, back, push_back, pop_front.
priority_queue: highest priority element at front of the queue. adapted from vector (default) or deque. Support operations front, push_back, pop_front.
First-class Containers, Adapters and Near Containers
The containers can also be classified as:
First-class Containers: all sequence containers and associative containers are collectively known as first-class container.
Adapters: constrained first-class containers such as stack and queue.
Near Containers: Do not support all the first-class container operations. For example, the built-in array (pointer-like), bitsets (for maintaining a set of flags), valarray (support array computation), string (stores only character type).
STL Pre-defined Iterators (in Header )
Example: istream_iterator and ostream_iterator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
intmain(){ // Construct ostream_iterators to write int and string to cout ostream_iterator<int> iterOut(cout); ostream_iterator<string> iterOutStr(cout);
*iterOutStr = "Enter two integers: ";
// Construct an istream_iterator<int> to read int from cin istream_iterator<int> iterIn(cin); int number1 = *iterIn; // dereference to get the value ++iterIn; // next int in cin int number2 = *iterIn;
*iterOutStr = "You have entered "; *iterOut = number1; *iterOutStr = " and "; *iterOut = number2; }
// Construct an ostream_iterator called out ostream_iterator<int, char> out(cout, " "); // Copy to ostream, via ostream_iterator - replacing the print() copy(v.begin(), v.end(), out); cout << endl;
// Copy to ostream in reverse order copy(v.rbegin(), v.rend(), out); cout << endl;
// Use an anonymous ostream_iterator copy(v.begin(), v.end(), ostream_iterator<int, char>(cout, " ")); cout << endl; return0; }
Example: insert_iterator
A front_insert_iterator inserts from the front; a back_insert_iterator inserts at the end; an insert_iterator inserts before a given location.
// Construct a back_insert_iterator to insert at the end back_insert_iterator<vector<int> > back (v); int a2[3] = {91, 92, 93}; copy(a2, a2+3, back); copy(v.begin(), v.end(), out); cout << endl;
// Use an anonymous insert_iterator to insert at the front int a3[3] = {81, 82, 83}; copy(a3, a3+3, insert_iterator<vector<int> >(v, v.begin())); copy(v.begin(), v.end(), out); cout << endl; return0; }
Algorithm
Example 1: sort(), reverse(), random_shuffle() and find() on Iterators [first,last)
// Invoke the given function (print, square) // for each element in the range for_each(v.begin(), v.end, print); for_each(v.begin() + 1, v.begin() + 3, square); for_each(v.begin(), v.end, print); return0; }
voidsquare(int & n){ n *= n; }
voidprint(int & n){ cout << n << " "; }
Function Object (Functors)
transform() algorithm
transform() algorithm has two versions, supporting unary and binary operations, respectively.
1 2 3 4 5 6
// Unary Operation template <classInputIterator, classOutputIterator, classUnaryOperation> OutputIterator transform(InputIterator first, InputIterator last, OutputIterator result, UnaryOperation op) // Perform unary operation on each element in [first,last) and // store the output in range beginning at result
transform(v.begin(), v.end(), out, ::sqrt); // in <cmath> return0; }
1 2 3 4 5 6 7 8
// Binary Operation template <classInputIterator1, classInputIterator2, classOutputIterator, classBinaryOperation> OutputIterator transform(InputIterator1 first1, InputIterator1 last1, InputIterator2 first2, OutputIterator result, BinaryOperation op) // Perform binary operation on each element in [first1,last1) as first argument, // and the respective [frist2,...) as second argument. // Store the output in range beginning at result
transform(v1.begin(), v1.end(), v2.begin(), out, plus<int>()); // Send result to output stream cout << endl;
transform(v1.begin(), v1.end(), v2.begin(), v1.begin(), minus<int>()); // Store result back to v1 copy(v1.begin(), v1.end(), out); cout << endl; return0; }
Stream IO and File IO
Stream IO
the Standard Stream Objects
The <iostream> header declares these standard stream objects:
cin (of istream class, basic_istream<char> specialization), wcin (of wistream class, basic_istream<wchar_t> specialization): corresponding to the standard input stream, defaulted to keyword.
cout (of ostream class), wcout (of wostream class): corresponding to the standard output stream, defaulted to the display console.
cerr (of ostream class), wcerr (of wostream class): corresponding to the standard error stream, defaulted to the display console.
clog (of ostream class), wclog (of wostream class): corresponding to the standard log stream, defaulted to the display console.
The ostream class
Formatting Output via the Overloaded Stream Insertion << Operator
1
ostream & operator<< (type) // type of int, double etc
cin: output buffer is flushed when input is pending, e.g.,
1 2 3
cout << "Enter a number: "; int number; cin << number; // flush output buffer so as to show the prompting message
The istream class
Formatting Input via the Overloaded Stream Extraction >> Operator
1
istream & operator<< (type &) // type of int, double etc.
Flushing the Input Buffer - ignore()
You can use the ignore() to discard characters in the input buffer:
1 2 3 4 5 6
istream & ignore(int n = 1, int delim = EOF); // Read and discard up to n characters or delim, whichever comes first
// Examples cin.ignore(numeric_limits<streamsize>::max()); // Ignore to the end-of-file cin.ignore(numeric_limits<streamsize>::max(), '\n'); // Ignore to the end-of-line
Unformatted Input/Output Functions
put(), get() and getline()
The ostream's member function put() can be used to put out a char. put() returns the invoking ostream reference, and thus, can be cascaded. For example,
1 2 3 4 5 6
// ostream class ostream & put(char c); // put char c to ostream // Examples cout.put('A'); cout.put('A').put('p').put('p').put('\n'); cout.put(65);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// istream class // Single character input intget(); // Get a char and return as int. It returns EOF at end-of-file istream & get(char & c); // Get a char, store in c and return the invoking istream reference
// C-string input istream & get(char * cstr, streamsize n, char delim = '\n'); // Get n-1 chars or until delimiter and store in C-string array cstr. // Append null char to terminate C-string // Keep the delim char in the input stream. istream & getline(char * cstr, streamsize n, char delim = '\n'); // Same as get(), but extract and discard delim char from the // input stream.
1 2 3 4 5
// Examples int inChar; while ((inChar = cin.get()) != EOF) { // Read till End-of-file cout.put(inchar); }
read(), write() and gcount()
1 2 3 4 5 6 7 8 9 10 11
// istream class istream & read(char * buf, streamsize n); // Read n characters from istream and keep in char array buf. // Unlike get()/getline(), it does not append null char at the end of input. // It is used for binary input, instead of C-string. streamsize gcount()const; // Return the number of character extracted by the last unformatted input operation // get(), getline(), ignore() or read().
// ostream class ostream & write(constchar * buf, streamsize n)
peek() and putback()
1 2 3 4 5
charpeek(); //returns the next character in the input buffer without extracting it.
istream & putback(char c); // insert the character back to the input buffer.
File Input/Output (Header )
File Output
Steps:
Construct an ostream object.
Connect it to a file (i.e., file open) and set the mode of file operation (e.g, truncate, append).
Perform output operation via insertion >> operator or write(), put() functions.
Disconnect (close the file which flushes the output buffer) and free the ostream object.
// OR combine declaration and open() ifstream fin(filename, mode);
Most of the <fstream> functions (such as constructors, open()) supports filename in C-string only. You may need to extract the C-string from string object via the c_str() member function.
The get(char &) function returns a null pointer (converted to false) when it reaches end-of-file.
// Read from file ifstream fin(filename.c_str()); // default mode ios::in char ch; while (fin.get(ch)) { // till end-of-file cout << ch; }
Binary file, read() and write()
We need to use read() and write() member functions for binary file (file mode of ios::binary), which read/write raw bytes without interpreting the bytes.
// Read from buffer int i; double d; string s; sin >> i >> d >> s; cout << i << "," << d << "," << s << endl;
Miscellaneous, Tips and Traps
Exception Handling
throw, try and catch
Suppose that we have a class called PositiveInteger, which maintains a data member value containing a positive integer.
PositiveInteger.cpp
1 2 3 4 5 6 7 8 9
// Setter with input validation voidPositiveInteger::setValue(int v){ if (v > 0) { value = v; } else { throwinvalid_argument("value shall be more than 0."); // need <stdexcept> } }
TestPositiveInteger.cpp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// Graceful handling of exception with try-catch try { cout << "begin try 1..." << endl; PositiveInteger i3(-8); // Exception thrown. // Skip the remaining statements in try and jump to catch. cout << i3.getValue() << endl; cout << "end try 1..." << endl; // Continue to the next statement after try-catch, if there is no exception } catch (invalid_argument & ex) { // need <stdexcept> cout << "Exception: " << ex.what() << endl; // Continue to the next statement after try-catch } cout << "after try-catch 1..." << endl;
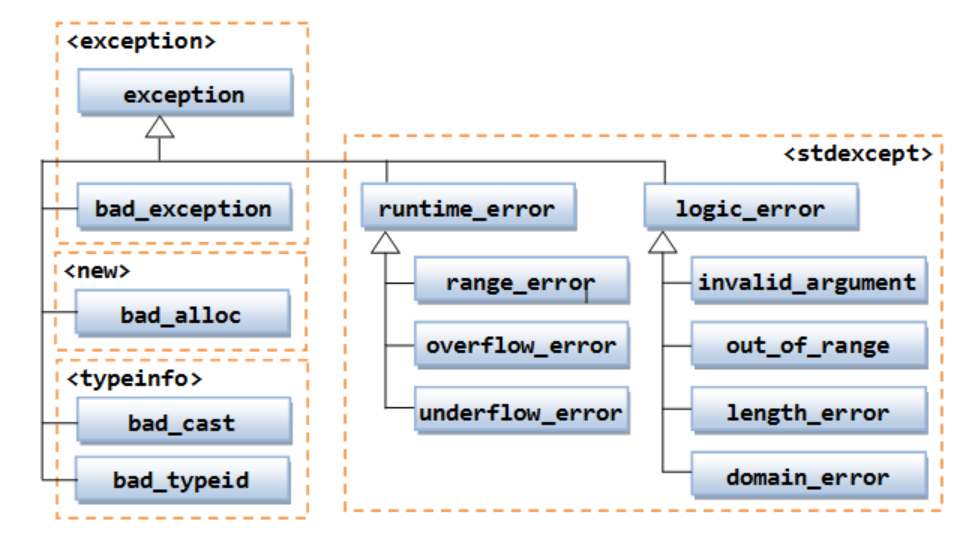
Class exception and its subclasses
Creating Your Own exception subclass
You can create your own exception by subclassing exception or its subclasses (such as logic_error or runtime_error). For example,
MyException.h:
1 2 3 4 5 6 7 8 9 10 11 12 13
/* Header for the MyException class (MyException.h) */ #ifndef MY_EXCEPTION_H #define MY_EXCEPTION_H
The duration determines when the variable is created and destroyed;
The Scope determines which part of the program can access the variable;
The linkage determines whether the variable is available in other source files.
Automatic Local Variables ("auto" Specifier)
Local variables have default type auto.
Static Variables ("static" Specifier)
Static variables has three types of linkage:
external: global static variables visible in other source files - defined outside all functions without keyword static.
internal: global static file-scope variables visible in the file that it is defined - defined outside all functions with keyword static.
no linkage: local static variable visible within a function or block for which it is defined - defined inside a function with keyword static.
static class members
A static class member (data or function) belongs to the class, instead of instances. It can be referenced directly from the class, without creating instances, via *Classname*::*staticMemberName*. A static data member retains its value throughout the program execution.
Summary of static Keyword
A static variable defined inside a block has block-scope, but having duration for the entire program. It retains its memory and value across multiple invocations.
A static global variable defined outside all functions has file-scope with internal linkage (i.e., visible only to the file in which it is defined, but not other source files). It has duration for the entire program, and retains its memory and value throughout the program execution. On the other hand, a global variable without the static keyword has file-scope with external linkage. It can be referenced by other file via the extern keyword.
A static class member belongs to the class, instead of the instances. There is one copy shared by all the instances. It has class scope. To reference it outside the class, use the scope resolution operator *classname*::*static_membername*.
External Variables ("extern" Specifier)
The extern specifies linkage to another source file. It tells the compiler that the identifier is defined in another (external) source file.
1 2 3 4
// File1.cpp externint globalVar; // Declare that this variable is defined in another file (external variable). // Cannot assign an value. // Need to link to the other file.
1 2 3 4 5
// File2.cpp int globalVar = 88; // Definition here // or externint globalVar = 88; // The "extern" specifier is optional. // The initialization indicates definition
2.5 CV-Qualifiers (const and volatile) and mutable
The "const" qualifier indicates that the content of the storage location shall not be changed after initialized.
The "volatile" qualifier indicates that the content of the storage location could be altered outside your program, e.g., by an external hardware. This qualifier is needed to tell compiler not to optimize this particular location (e.g., not to store in register, not to re-order the statement, or collapse multiple statements).
The mutable specifier can be used in struct or class to indicate that a particular data member is modifiable even though the instance is declared const.
"const" Global Variables
By default, a global variable (defined outside all functions) has external linkage. However, const global variable has internal linkage (as if static specifier is used). As the result, you can place all const global variables in a header file, and include the header in all the source files. To set a const global variable to external linkage, include "extern" specifier.
Type Casting Operators
C++ introduces 4 new type casting operators: const_cast<new-type>(value), static_cast<new-type>(value), dynamic_cast<new-type>(value), reinterpret_cast<new-type>(value) to regulate type casting.
C++ supports C's explicit type casting operations (new-type)value (C-style cast), or new-type(value) (Function-style cast), called regular cast.
Although the old styles is still acceptable in C++, new styles are preferable.
static_cast
static_cast is used for force implicit conversion. It throws a type-cast error if the conversion fails.
Can be used to convert values of various fundamental types, e.g., from double to int, from float to long.
dynamic_cast
dynamic_cast can be used to verify the type of an object at runtime, before performing the type conversion. It is primarily used to perform "safe downcasting".
classCircle : public Shape { voiddraw()override{} voidradius(){} // Circle specific method };
voidprocessShape(Shape* shape){ if (Circle* circle = dynamic_cast<Circle*>(shape)) { circle->radius(); } }
const_cast
The const_cast can be used to drop the const label, so as to alter its contents (i.e., cast away the const-ness or volatile-ness). This is useful if you have a variable which is constant most of the time, but need to be changed in some circumstances. You can declare the variable as const, and use const_cast to alter its value. The syntax is:
1
const_cast<Type>(expression)
const_cast cannot change the type of an object.
reinterpret_cast
Used for low-level casts that yield implementation-dependent result, e.g., casting a pointer to an int.
// Search the array for the given key // If found, return array index [0, size-1]; otherwise, return size intlinearSearch(constint a[], int size, int key){ for (int i = 0; i < size; ++i) { if (a[i] == key) return i; } return size; }
Binary Search
A binary search (or half-interval search) is applicable only to a sorted array.
// Search the array for the given key // If found, return array index; otherwise, return -1 intbinarySearch(constint a[], int size, int key){ // Call recursive helper function returnbinarySearch(a, 0, size-1, key); }
// Recursive helper function for binarySearch intbinarySearch(constint a[], int iLeft, int iRight, int key){ // Test for empty list if (iLeft > iRight) return-1;
// Compare with middle element int mid = (iRight + iLeft) / 2; // truncate if (key == a[mid]) { return mid; } elseif (key < a[mid]) { // Recursively search the lower half binarySearch(a, iLeft, mid - 1, key); } else { // Recursively search the upper half binarySearch(a, mid + 1, iRight, key); } }
// Sort the given array of size using insertion sort voidinsertionSort(int a[], int size){ int temp; // for shifting elements for (int i = 1; i < size; ++i) { // For element at i, insert into proper position in [0, i-1] // which is already sorted. // Shift down the other elements for (int prev = 0; prev < i; ++prev) { if (a[i] < a[prev]) { // insert a[i] at prev, shift the elements down temp = a[i]; for (int shift = i; shift > prev; --shift) { a[shift] = a[shift-1]; } a[prev] = temp; break; } } } }
Insertion sort is not efficient, with complexity of O(n2).
Selection sort
Pass thru the list. Select the smallest element and swap with the head of the list.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// Sort the given array of size using selection sort voidselectionSort(int a[], int size){ int temp; // for swapping for (int i = 0; i < size - 1; ++i) { // [0, i-1] already sort // Search for the smallest element in [i, size-1] // and swap with a[i] int minIndex = i; // assume fist element is the smallest for (int j = i + 1; j < size; ++j) { if (a[j] < a[minIndex]) minIndex = j; } if (minIndex != i) { // swap temp = a[i]; a[i] = a[minIndex]; a[minIndex] = temp; } } }
Selection sort is not efficient, with complexity of O(n2).
Bubble sort
Pass thru the list, compare two adjacent items and swap them if they are in the wrong order. Repeat the pass until no swaps are needed.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// Sort the given array of size voidbubbleSort(int a[], int size){ bool done = false; // terminate if no more swap thru a pass int temp; // use for swapping
while (!done) { done = true; // Pass thru the list, compare adjacent items and swap // them if they are in wrong order for (int i = 0; i < size - 1; ++i) { if (a[i] > a[i+1]) { temp = a[i]; a[i] = a[i+1]; a[i+1] = temp; done = false; // swap detected, one more pass } } } }
Bubble sort is not efficient, with complexity of O(n2).
Merge Sort
Recursive Top-Down Merge Sort
Recursively divide the list into 2 sublists.
When the sublists contain 1 element (a list of 1 element is sorted), merge two sublists in the right order. Unwind the merging recursively.
// Function to merge two sorted subarrays into a single sorted array // arr[left..mid] and arr[mid+1..right] are the subarrays to be merged voidmerge(std::vector<int>& arr, int left, int mid, int right){ // Calculate sizes of the two subarrays to be merged int n1 = mid - left + 1; // Size of left subarray int n2 = right - mid; // Size of right subarray
// Create temporary arrays to store the two halves // This extra space is necessary to perform the merge std::vector<int> L(n1); std::vector<int> R(n2);
// Copy data to temporary arrays L[] and R[] // This allows us to modify the original array while merging for(int i = 0; i < n1; i++) L[i] = arr[left + i]; for(int j = 0; j < n2; j++) R[j] = arr[mid + 1 + j];
// Initialize indices for merging int i = 0; // Initial index of left subarray int j = 0; // Initial index of right subarray int k = left; // Initial index of merged array
// Merge the temporary arrays back into arr[left..right] // Compare elements from both subarrays and place the smaller one first while(i < n1 && j < n2) { if(L[i] <= R[j]) { arr[k] = L[i]; i++; } else { arr[k] = R[j]; j++; } k++; }
// Copy remaining elements of L[], if any // If there are any elements left in the left subarray while(i < n1) { arr[k] = L[i]; i++; k++; }
// Copy remaining elements of R[], if any // If there are any elements left in the right subarray while(j < n2) { arr[k] = R[j]; j++; k++; } }
// Recursive function to sort an array using merge sort // left is the left index and right is the right index of the subarray to be sorted voidmergeSortRecursive(std::vector<int>& arr, int left, int right){ // Base case: if left >= right, subarray has 0 or 1 element (already sorted) if(left < right) { // Find the middle point to divide array into two halves // Using (left + right)/2 might cause integer overflow int mid = left + (right - left) / 2;
// Sort first and second halves recursively mergeSortRecursive(arr, left, mid); // Sort left half mergeSortRecursive(arr, mid + 1, right); // Sort right half
// The merge function remains similar to the recursive version // It combines two sorted subarrays into a single sorted array // arr[left..mid] and arr[mid+1..right] are the subarrays to be merged voidmerge(std::vector<int>& arr, int left, int mid, int right){ int n1 = mid - left + 1; int n2 = right - mid;
// Iterative merge sort implementation using a bottom-up approach voidmergeSortIterative(std::vector<int>& arr){ int n = arr.size();
// Start merging subarrays of size 1, then 2, 4, 8, and so on // The 'width' variable represents the size of subarrays being merged for(int width = 1; width < n; width = width * 2) { // For each pair of subarrays of size 'width' // left marks the start of the first subarray for(int left = 0; left < n; left = left + 2 * width) { // Calculate the middle point and right boundary int mid = std::min(left + width - 1, n - 1); int right = std::min(left + 2 * width - 1, n - 1);
// Merge the two subarrays if they exist if(left < mid && mid < right) { merge(arr, left, mid, right); } } } }
The worst-case and average-case time complexity is O(n log n). The best-case is typically O(n log n). However, merge sort requires a space complexity of O(n) for carrying out the merge-sorting.
Quick Sort
The Core Idea:
Choose a 'pivot' element from the array
Partition the array around this pivot (elements smaller than pivot go to the left, larger to the right)
Recursively apply the same process to the subarrays
For example, consider the array [10, 7, 8, 9, 1, 5]:
// This function takes the last element as pivot, places the pivot // at its correct position, and places smaller elements to the left // and greater elements to the right intpartition(std::vector<int>& arr, int low, int high){ // Select the rightmost element as pivot int pivot = arr[high];
// Index of smaller element int i = low - 1;
// Compare each element with pivot for(int j = low; j < high; j++) { // If current element is smaller than pivot if(arr[j] <= pivot) { i++; // Increment index of smaller element std::swap(arr[i], arr[j]); } }
// Place pivot in its final position std::swap(arr[i + 1], arr[high]); return i + 1; }
// The main QuickSort function voidquickSort(std::vector<int>& arr, int low, int high){ if(low < high) { // Find the partition index int pi = partition(arr, low, high);
// Separately sort elements before and after partition quickSort(arr, low, pi - 1); quickSort(arr, pi + 1, high); } }
The worst-case time complexity is O(n2). The average-case and best-case is O(n log n). In-place sorting can be achieved without additional space requirement.
Bucket Sort
Bucket sort is a distribution sort, and is a cousin of radix sort.
The core idea:
Set up buckets, initially empty.
Scatter: place each element into an appropriate bucket.
Sort each non-empty bucket.
Gather: Gather elements from buckets and put back to the original array.
voidbucketSort(int a[], int size){ // find maximum to decide on the number of significant digits int max = a[0]; for (int i = 1; i < size; ++i) { if (a[i] > max) max = a[i]; }
// Decide on the max radix (1000, 100, 10, 1, etc) int radix = 1; while (max > 10) { radix *= 10; max /= 10; }
// copy the array into a vector vector<int> list(size); for (int i = 0; i < size; ++i) { list[i] = a[i]; } bucketSort(list, radix); }
// Sort the given array of size on the particular radix (1, 10, 100, etc) // Assume elements are non-negative integers // radix shall be more than 0 voidbucketSort(vector<int> & list, int radix){ if (list.size() > 1 && radix > 0) { // Sort if more than 1 elements vector<int> buckets[NUM_BUCKETS]; // 10 buckets
// Distribute elements into buckets for (int i = 0; i < list.size(); ++i) { int bucketIndex = list[i] / radix % 10; buckets[bucketIndex].push_back(list[i]); }
// Recursively sort the non-empty bucket for (int bi = 0; bi < NUM_BUCKETS; ++bi) { if (buckets[bi].size() > 0) { bucketSort(buckets[bi], radix / 10); } }
// Gather all the buckets into list and return list.resize(0); // remove all elements for (int bi = 0; bi < NUM_BUCKETS; ++bi) { for (int j = 0; j < buckets[bi].size(); ++j) { list.push_back((buckets[bi])[j]); } } } }
For example:
Consider the initial array: {28,104,25,593,22,129,4,11,129,4,111,20,9}
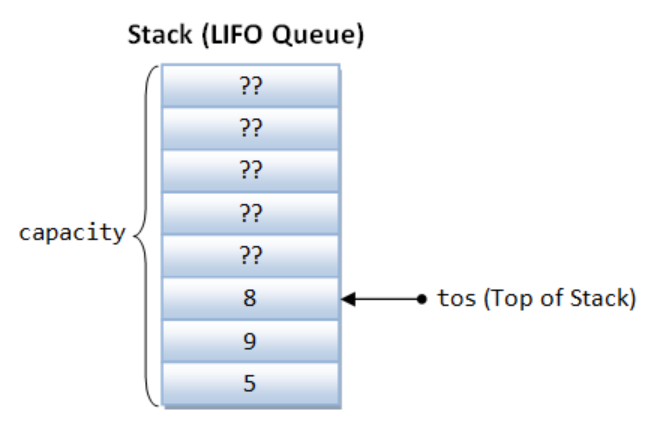
template <typename T> classStack { private: T * data; // Array int tos; // Top of stack, start at index -1 int capacity; // capacity of the array int increment; // each subsequent increment size public: explicitStack(int capacity = 10, int increment = 10); ~Stack(); // Destructor voidpush(const T & value); boolpop(T & value); boolisEmpty()const;
friend std::ostream & operator<< <>(std::ostream & os, const Stack<T> & s); // Overload the stream insertion operator to print the list };
We use an array to store the data in the stack and use tos as the index of the array to get the data.
Tree
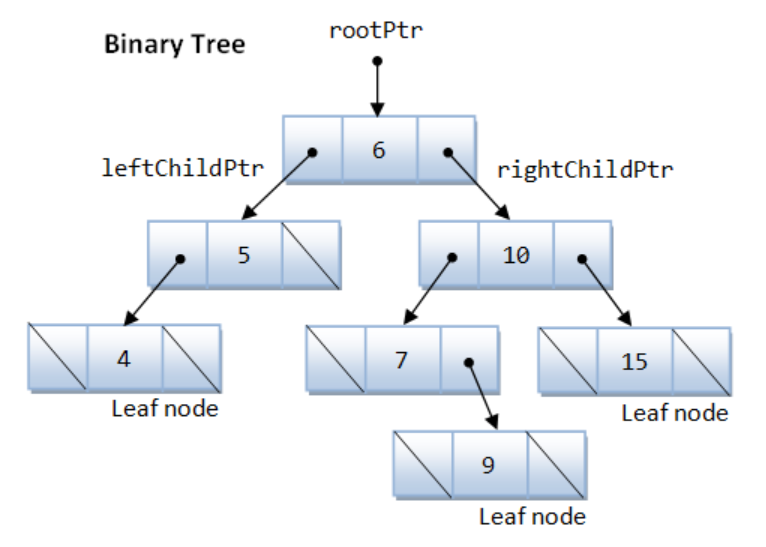
A Binary Tree:
Depth-First Search (DFS)
Start at the root and explore as far as possible along each branch before backtracking. There are 3 types of depth-first search:
Pre-order: visit the root, traverse the left subtree, then the right subtree. E.g., 6 -> 5 -> 4 -> 10 -> 7 -> 9 ->15.
In-order: traverse the left subtree, visit the root, then the right subtree. E.g., 4 -> 5 -> 6 -> 7 -> 9 ->10 -> 15.
Post-order: traverse the left subtree, the right subtree, then visit the root. E.g, 4 -> 5 -> 9 -> 7 -> 15 -> 10 -> 6.
Breadth-First Search (BFS)
Begin at the root, visit all its child nodes. Then for each of the child nodes visited, visit their child nodes in turn. E.g., 6 -> 5 -> 10 -> 4 -> 7 -> 15 -> 9.