File Systems
File Systems
Learning Materials
Videos:
Lecture Slides:
Readings:
[OSTEP] File system implementation
[OSTEP] Crash consistency: fsck and journaling
Hard Disk Drives
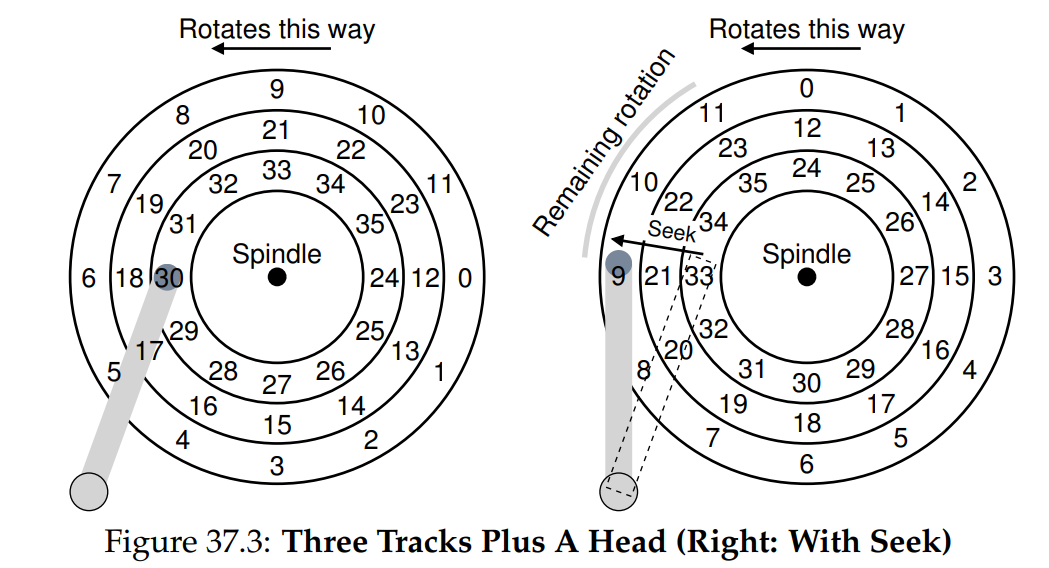
Disk Basics
A complete I/O:
First a seek, then waiting for the rotational delay, and finally the transfer(read/write).
Disk Scheduling
- SSTF: Shortest Seek Time First
How can we implement SSTF-like scheduling but avoid starvation?
- Elevator (a.k.a. SCAN or C-SCAN)
How can we implement an algorithm that more closely approximates SJF by taking both seek and rotation into account?
- SPTF: Shortest Positioning Time First
Linux I/O Schedulers(*)
Goals of I/O schedulers
- Minimize disk seeks
- Ensure optimum disk performance
- Provide fairness among I/O requests
Balancing these goals or trading them against one another is the essence of the art of creating an I/O scheduler.
Four schedulers in Linux
- NOOP
All incoming I/O requests for all processes running on the system, regardless of the I/O request (e.g., read, write, lseek, etc.), go into a simple first in, first out (FIFO) queue. The scheduler also does request merging to reduce seek time and improve throughput.
NOOP scheduler does not make any attempts to reduce seek time. Therefore, storage devices that have very little seek time benefit from a NOOP I/O scheduler.
- Anticipatory
It anticipates subsequent block requests and implements request merging, a one-way elevator, and read and write request batching.
After the scheduler services an I/O request, it pauses slightly to see if the next request is for the subsequent block.
A web server can achieve better performance while database run can suffer from a slowdown with anticipatory I/O scheduling.
- Deadline
Maintain two deadline queues in addition to the sorted queues for reads and writes.
Sorted queues are sorted according to their sector numbers(the elevator approach).
Queues for reads are prioritized. If the first request in the deadline queue is expired, execute it immediately; otherwise, the scheduler serves a batch of requests from the sorted queue.
Useful for real-time applications as it keeps latency low, and for database systems that have TCQ-aware disks (the hardware makes I/O scheduling decisions).
- CFQ
Default Linux kernel scheduler
CFQ synchronously puts requests from processes into a number of per-process queues then allocates time slices for each of the queues to access the disk.
Flash-based SSDs
Flash Basics
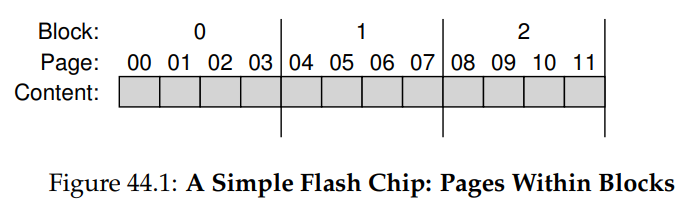
Whenever we want to write to a page, we need to erase the whole block first.
Primary concern of flash chips: wear out!
What is wear out?
When a flash block is erased and programmed, it slowly accrues a little bit of extra charge. Over time, as that extra charge builds up, it becomes increasingly difficult to differentiate between a 0 and a 1. At the point where it becomes impossible, the block becomes unusable.
From Raw Flash to Flash-Based SSDs
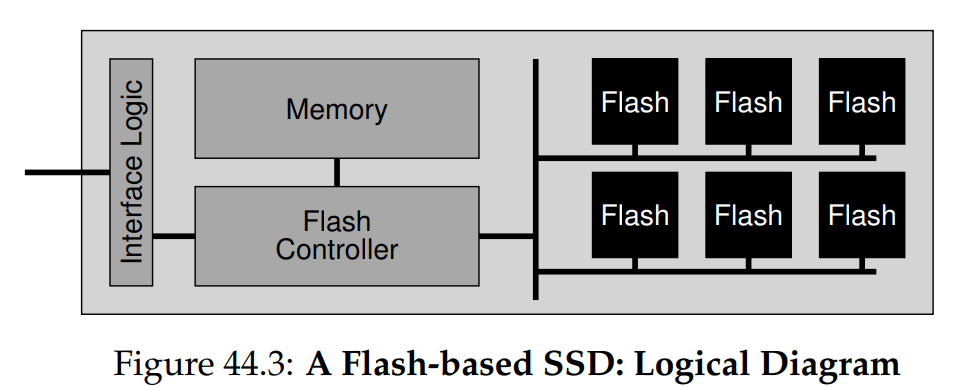
FTL(flash translation layer): FTL turns clients' read and write requests into internal flash operations(low-level read, erase, and program).
FTL Organization: A Log-Structured FTL
How to translate logical block(issued by the client) into physical page(on the actual SSD device)?
FTL maintains a in-memory mapping table.
What happens when the client(file system) writes a page to the SSD?
When the client writes to the SSD, The SSD picks the next free page and programs the page with the block's contents, and records the logical-to-physical mapping in its mapping table.
Three major problems with log-structured FTL
- Cost of Garbage Collection
What happens when we overwrite a page?
Old pages have garbage(old-version data) in them. We need Garbage Collection!
Garbage Collection: Find a block that contains one or more garbage pages, read in the live (non-garbage) pages from that block, write out those live pages to the log, and (finally) reclaim the entire block for use in writing
- Large size of the mapping table
What if we have a very large mapping table?
-
Hybrid Mapping(log-based + block-based mapping): Maintain a log table(a pointer per page) and a data table(a pointer per block)
-
Page Mapping Plus Caching: Caching hot pieces of the FTL
- Wear Leveling
How to balance the erase/program loads among physical blocks of the flash chip so that all blocks wear out roughly at the same time?
The FTL occasionally migrate data from blocks that are mostly read(seldom overwritten) in order to ensure said blocks receive their share of the erase/program load.
File System Implementation
Introduction to file systems
vnode is the internal structure that describes the file.
The key part of defining a file system is to design the data structure that maps from an abstract notion of a file to a collection of disk blocks.
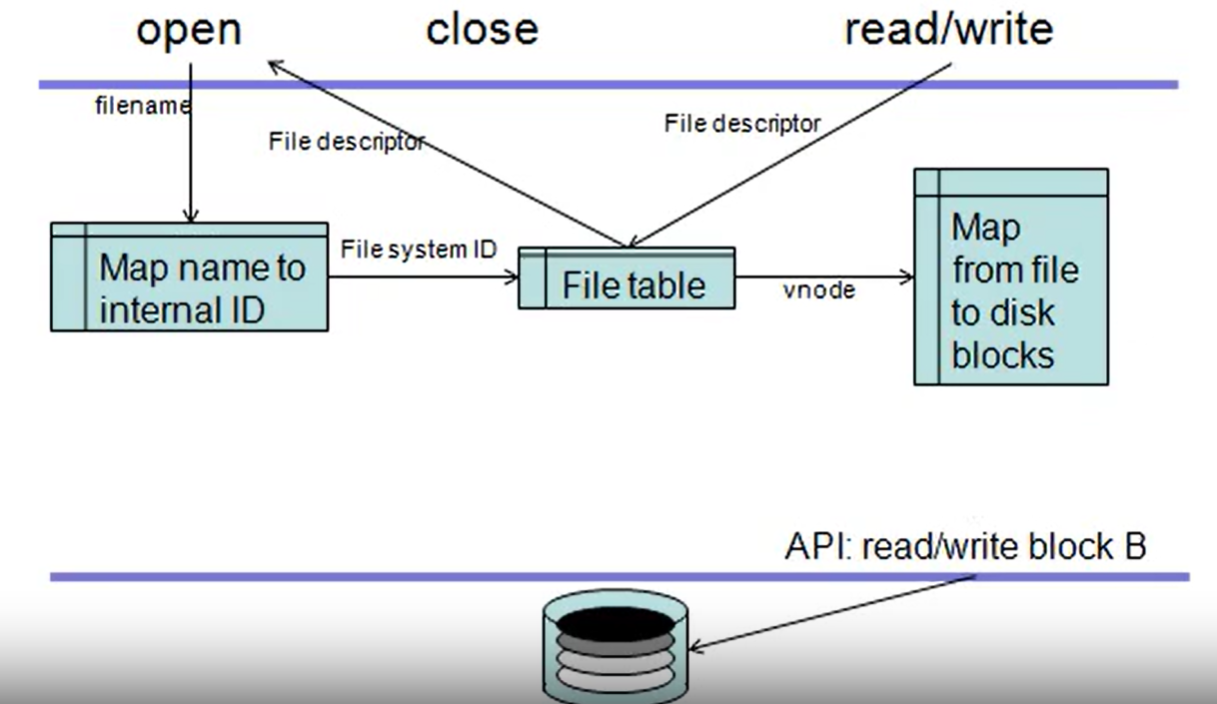
File structure:
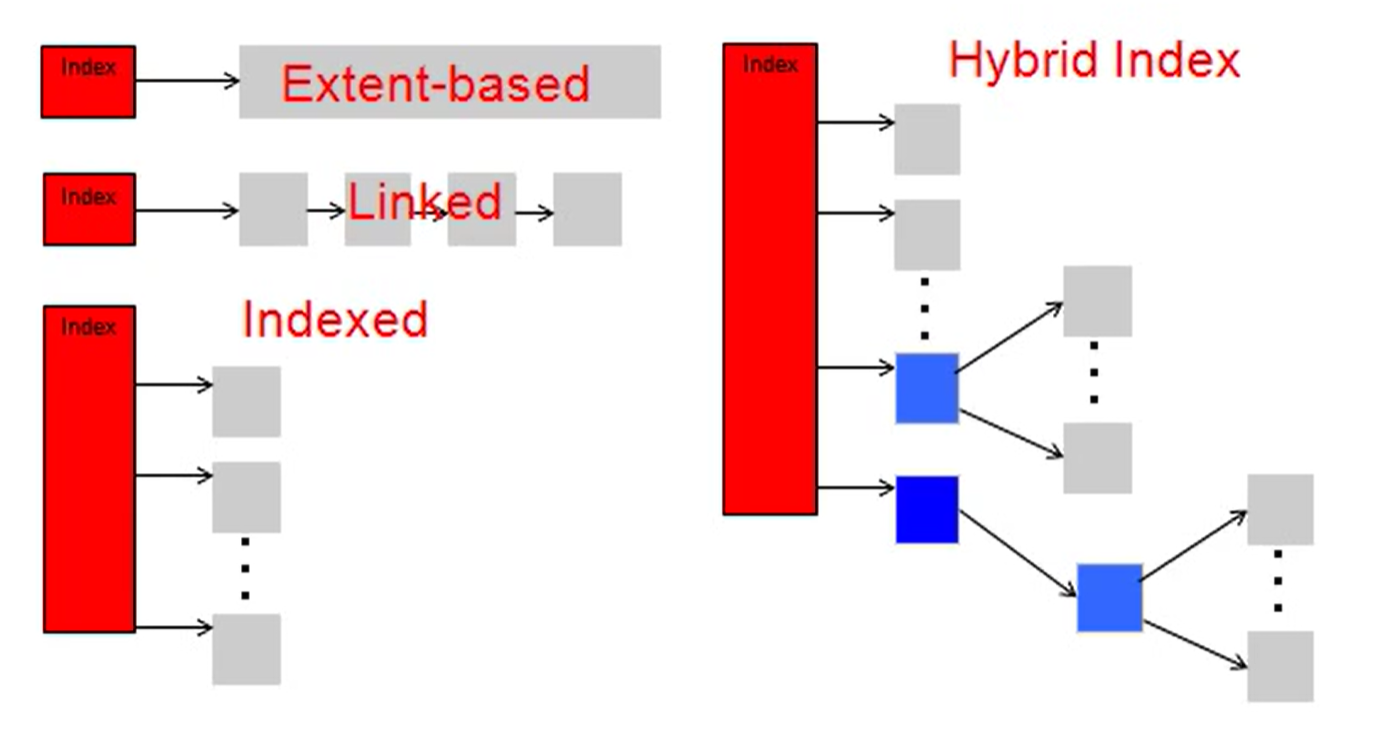
Inode Structure
The Multi-Level Index File System:
The inode contains some direct pointers pointing to data blocks, and also contains some indirect pointers pointing to indirect blocks, in which the pointers point to data blocks.
Directory

Directory is just a special type of file that stores name→inode-number mappings. Thus, a directory has an inode, somewhere in the inode table.
Root directory has a designated inode number(2).
Locality and The Fast File System
Data structures of the old file system(really simple!):

However, the old file system has pretty bad performance, so the crux of our problem:
How can we organize on-disk data to improve performance?
FFS: Disk Awareness
FFS divides the disk into a number of cylinder groups.
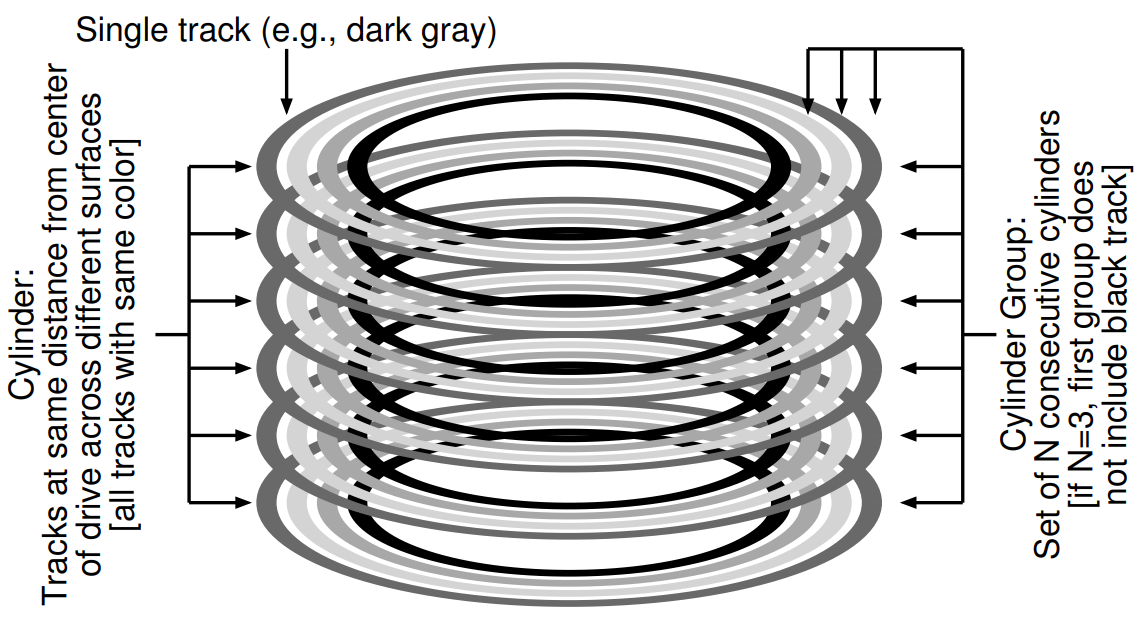
However, modern drives do not export their geometry information to the file system. Disks only export a logical address space of blocks. Therefore, modern file systems instead organize the drive into block groups.
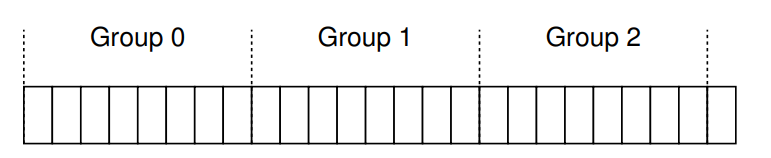
Accessing files within the same group won't result in long seeks across the disk.
FFS includes all the structures you might expect a file system to have within each group.

FFS Policies
Assumptions we make?
File Locality: We assume that files within the same directory accessed together more often.
How to place directories?
Find the cylinder group with
- a low number of allocated directories (to balance directories across groups)
- a high number of free
inodes(to subsequently be able to allocate a bunch of files)
How to place files?
- Allocate the data blocks of a file in the same group as its
inode. - Place all files that are in the same directory in the cylinder group of the directory they are in.
What is the large-file exception? Why we should place large files differently?
A large file would entirely fill the block group, which prevents subsequent “related” files from being placed within this block group, hurting file-access locality.
So our policy is: After some number of blocks are allocated into the first block group(the number of direct pointers available within an inode), FFS places the next “large” chunk of the file(those pointed to by the first indirect block) in another block group, and so on…

Crash Consistency: FSCK and Journaling
The crux of our problem:
The system may crash or lose power at any time during disk operations, and thus the on-disk state may only partially get updated. How do we ensure the file system keeps the on-disk image in a reasonable state?
Solution #1: The File System Checker
Let inconsistencies happen and then fix them later (when rebooting).
By consistency, we mean that the file system metadata is internally consistent.
fsck is a UNIX tool for finding such inconsistencies and repairing them:
-
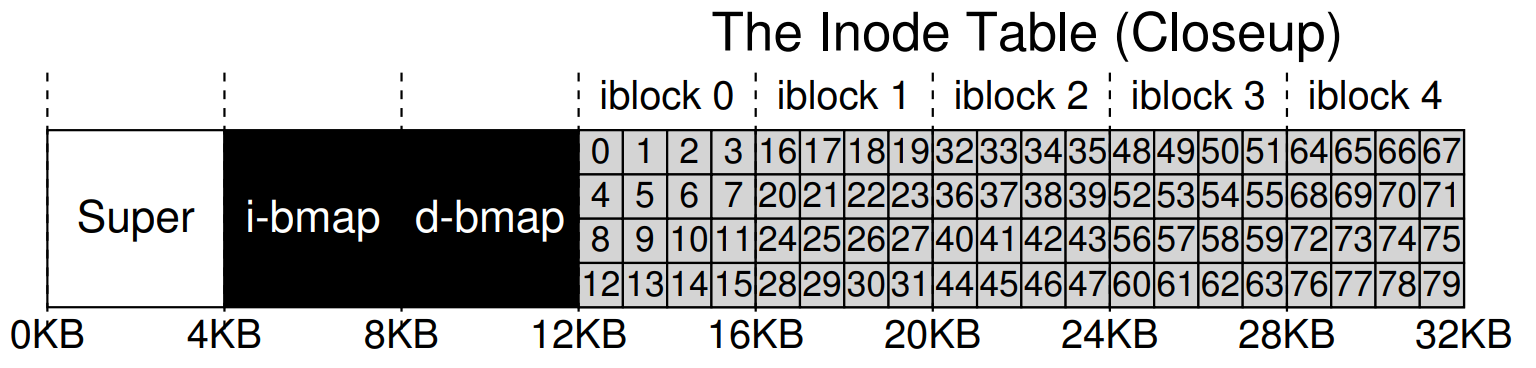
Superblock: Check if the superblock looks suspicious and use an alternate copy of the superblock if it finds a suspect superblock.
Recall that each block group has a copy of the superblock.
-
Free blocks: Produce a correct version of the allocation bitmaps by scanning the
inodes, indirect blocks, double indirect blocks, …, to resolve any inconsistency between bitmaps andinodes.For now, we trust the information with the
inodes. -
Inodestate: Check eachinode, clear the suspectedinodeand update theinodebitmap correspondingly.The information within the
inodescan be corrupted. -
Inodelinks: Verify the link count of each allocatedinode.Recall that the link count indicates the number of different directories that contain a reference (i.e., a link) to this particular file.
Aside: What's the difference between hard link and symbolic link?
Symbolic Link: A symbolic link is a special type of file(like regular files and directories), which stores the path name(string) of the target file. It has its own
inode:symlink's inode.Hard Link: Different directory's entries point to the same
inodeand are calculated by link count. Deleting the file will decrease the link count by 1.1
2
3
4
5
6Symbolic Link:
dir entry -> symlink's inode -> (存储路径字符串: "/path/to/target")
Hard Link:
dir entry 1 ──┐
dir entry 2 ──┴─> target's inode -> (实际数据) -
Duplicates: Check for duplicated pointers, i.e., cases where two different
inodesrefer to the same block. -
Bad blocks: Check for bad block pointers and remove the pointers from the
inodeor indirect block. -
Directory checks: Check on the contents of each directory.
fsck requires scanning the entire disk, so the problem of fsck is obvious:
As disks grew bigger, the performance became prohibitive.
Solution #2: Journaling (or Write-Ahead Logging)
Basic idea: When updating the disk, before overwriting the structures in place, first write down a little note to a structure(somewhere else on the disk, in a well-known location) that we organize as a "log", describing what you are about to do.
Linux ext3: a popular journaling file system
An ext2 file system (without journaling):

An ext3 file system adds a new key structure: journal

Data journaling

What if
TxEis successfully written to the log while Db(user data) is not?
If we write theses five blocks all at once, if the system crash before Db is completely written to disk while TxE has been successfully written to disk. The system will assume that journal write is successful, despite it is not, causing problems.
How to avoid this problem?
The file system issues the transactional write in two steps:
-
Write all blocks except the
TxEblock at once to the journal.
-
When those writes complete, the file system issues the write of the
TxEblock, thus leaving the journal in this final, safe state:
TxE should be a single 512-byte block to make the write of TxE atomic(the disk guarantees that any 512-byte write will either happen completely or not at all).
Some file systems(e.g. Linux ext3) perform batching log updates by buffering multiple updates into a global transaction in memory, reducing write traffic to disk.
What if the log becomes full?
We make the log a circular log by freeing the space occupied by checkpointed transactions.
Mark the oldest and newest non-checkpointed transactions in the log in a journal superblock:

Our final data journaling protocol:
-
Journal write: Write the contents of the transaction (including
TxB, metadata, and data) to the log; wait for these writes to complete. -
Journal commit: Write the transaction commit block (containing
TxE) to the log; wait for write to complete.The transaction is now committed.
-
Checkpoint: Write the contents of the update (metadata and data) to their final on-disk locations.
-
Free: Some time later, mark the transaction free in the journal by updating the journal superblock.
However, we are writing each data block to the disk twice, which is a heavy cost to pay considering system crash is rare. How to improve our protocol?
Metadata Journaling
User data is not written to the log. Instead, they are written to disk first.

Our protocol:
-
Data write: Write data to final location; wait for completion (the wait is optional).
-
Journal metadata write: Write the begin block and metadata to the log; wait for writes to complete.
Step 3 should wait for step 1&2 to complete! Step 1 and Step 2 and run concurrently.
-
Journal commit: Write the transaction commit block (containing
TxE) to the log; wait for the write to complete.The transaction (including data) is now committed.
-
Checkpoint metadata: Write the contents of the metadata update to their final locations within the file system.
-
Free: Later, mark the transaction free in journal superblock.
The rule is: Write the pointed-to object before the object that points to it!
Linux ext3 gives you the option of choosing either data, ordered, or unordered modes (in unordered mode, data can be written at any time).
Log-structured File Systems
Write to disk sequentially
The crux of the problem:
How to write to disk sequentially?
Before writing to the disk, LFS keeps track of updates in memory.; when it has received a sufficient number of updates, it writes them to disk all at once.
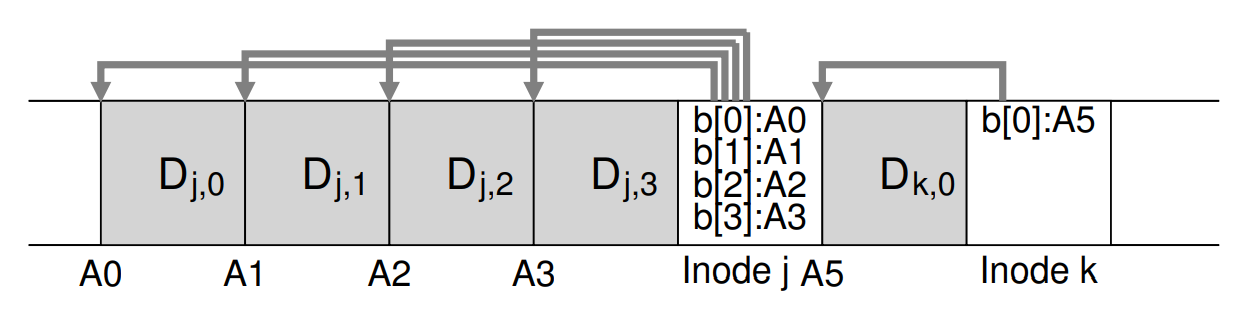
An example in which LFS buffers two sets of updates into a small segment:
Find Inodes
How to find
inodesin LFS?
Recall in FFS we split up the inode table into chunks and places a group of inodes within each cylinder group. So we need to know the address and size of each inode chunk before calculating the address of an inode.
Finding inodes in old Unix file system or FFS is simple because all inodes are placed in a fixed area on disk. You can simply calculate an inode's location given its inode number. However, in LFS, inodes are all across the disk and we never overwrite any inode so the latest version of an inode keeps moving.
LFS introduces the inode map (imap). The imap is a structure that takes an inode number as input and produces the disk address of the most recent version of the inode.
Note that the inode map in LFS is a virtualization of inode numbers.
LFS places chunks of the inode map right next to where it is writing all of the other new information to avoid frequent disk seeks:
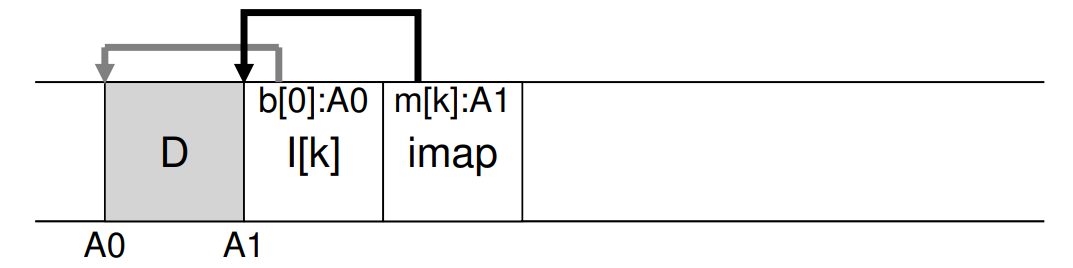
Now the question is:
How do we find the
inodemap, considering now that pieces of it are also now spread across the disk?
LFS has a fixed place on disk, known as the checkpoint region (CR), containing pointers to the latest pieces of the inode map.
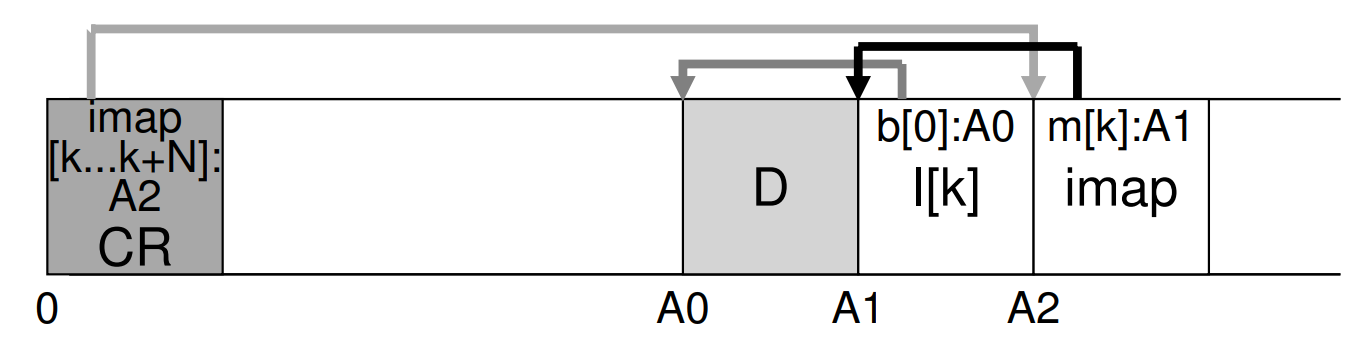
The entire imap is usually cached in memory, so the extra work LFS does during a read is to look up the inode’s address in the imap.
The imap also solves the recursive update problem. While an inode keeps moving across the disk, its inode number remains unchanged. Only the imap structure is updated while the directory holds the same name-to-inode-number mapping.
Garbage Collection
How to collect garbage in LFS?
Note that LFS always writes the latest version of a file to new locations on disk, leaving old versions of file structures(garbage) scattered throughout the disk.
LFS periodically find these old dead versions of file data, inodes, and other structures, and clean them.
The LFS cleaner works on a segment-by-segment basis so that subsequent writing can find large contiguous chunks of space. Specifically, we expect the cleaner to read in M existing segments, compact their contents into N new segments (where N < M), and then write the N segments to disk in new locations.
So our problem now is:
- How can LFS tell which blocks within a segment are live, and which are dead?
- How often should the cleaner run, and which segments should it pick to clean?
LFS stores a little extra information(for each data block D, its inode number and its offset) that describes each block in a structure at the head of the segment, known as the segment summary block.
Determine whether a block is live or dead:
1 | |