OS161 Assignment 5
Assignment5
Implement
fork, execv, waitpid, getpid and _exit.
Questions to think about
- How to create a copy of an existing user process and make the new process return to user mode with a different return value than the original process. Code in
runprogram.cand in the function it calls and inproc_create_runprogramwill be very helpful in figuring that out.
fork system call is responsible for creating a copy of an existing user process and making the new(child) process return to user mode with a different return value than the original(parent) process.
To create a new user process, we first need to create a new kernel thread to provide to it. This newly-created kernel thread should change child's trapframe and return to user mode in a different manner than the parent.
- How to replace the address space of a process created via
forkwith a completely new address space and executable.
When we want to create a process with a completely new address space and executable. we need to call execv after fork. In execv, we need to create the new address space, switch to and activate it. With the new address space set up, we can load the new executable and define the user stack.
- How to copy in/out of the
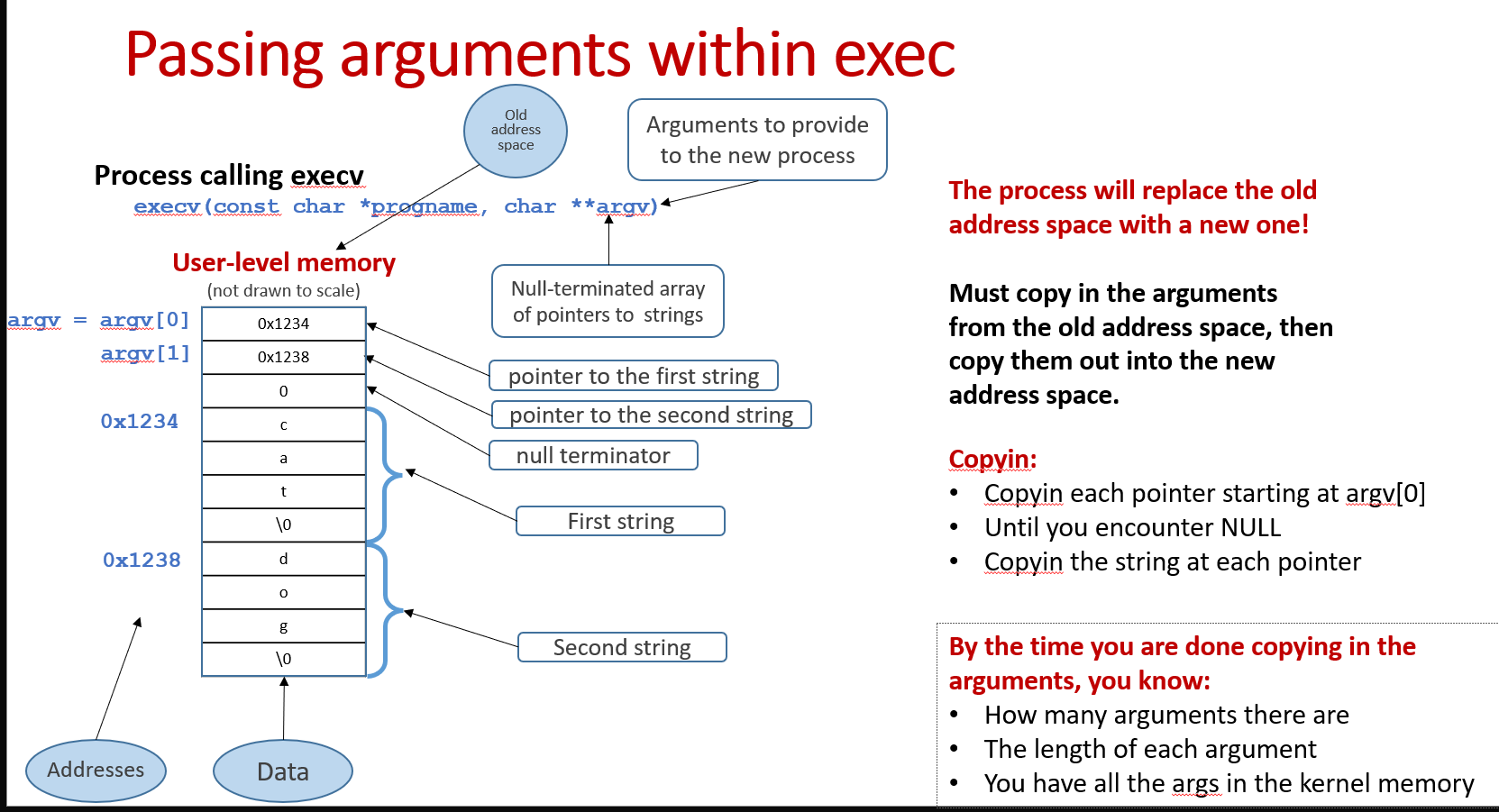
userspacethe argument vector for theexecvsystem call. This code requires lots of pointer arithmetic and handling various corner cases.
This is the most tricky part when we implement execv. We need to copy in/out not only the argument array, but also the pointers pointing to those arguments. First, we need to copy argument array and pointer array into the kernel from the old address space, then copy those out to the new address space.
- How to manage the process IDs, so you don't run out as processes are created and retired.
We need to implement the PID system that dynamically allocates and reclaims PID.
- How to synchronize the parent and child processes in
waitpid()and_exit().
To synchronize parent and child processes, we need to implement the process wait and exit mechanism. For now, just need to understand that parent processes call waitpid to wait for their child processes to exit. When child processes exit, they need to signal their parents.
It's important to note that a process will not necessarily be cleaned up right after it exits. It strongly depends on how you design your process wait and cleanup mechanism.
- How to manage the file table synchronization, given that starting from this assignment two or more processes might concurrently access the same file object (processes created via fork share the file objects).
In the last assignment, we already take this synchronization problem into account. As long as we hold the file handle lock right after we get the file handle, we are fine.
System calls to implement
Make sure to read the system calls man page carefully to understand every detail of these system calls:
1 | |
Main task: Implement pid allocation and reclamation
1 | |
sys_fork is responsible for:
- Copy address space(
as_copyindumbvm)
The forked process should have the exact same address space as the original process.

- Copy the file table
When a process is forked, file descriptor entries of the new process point to the same file handles as in the parent process.
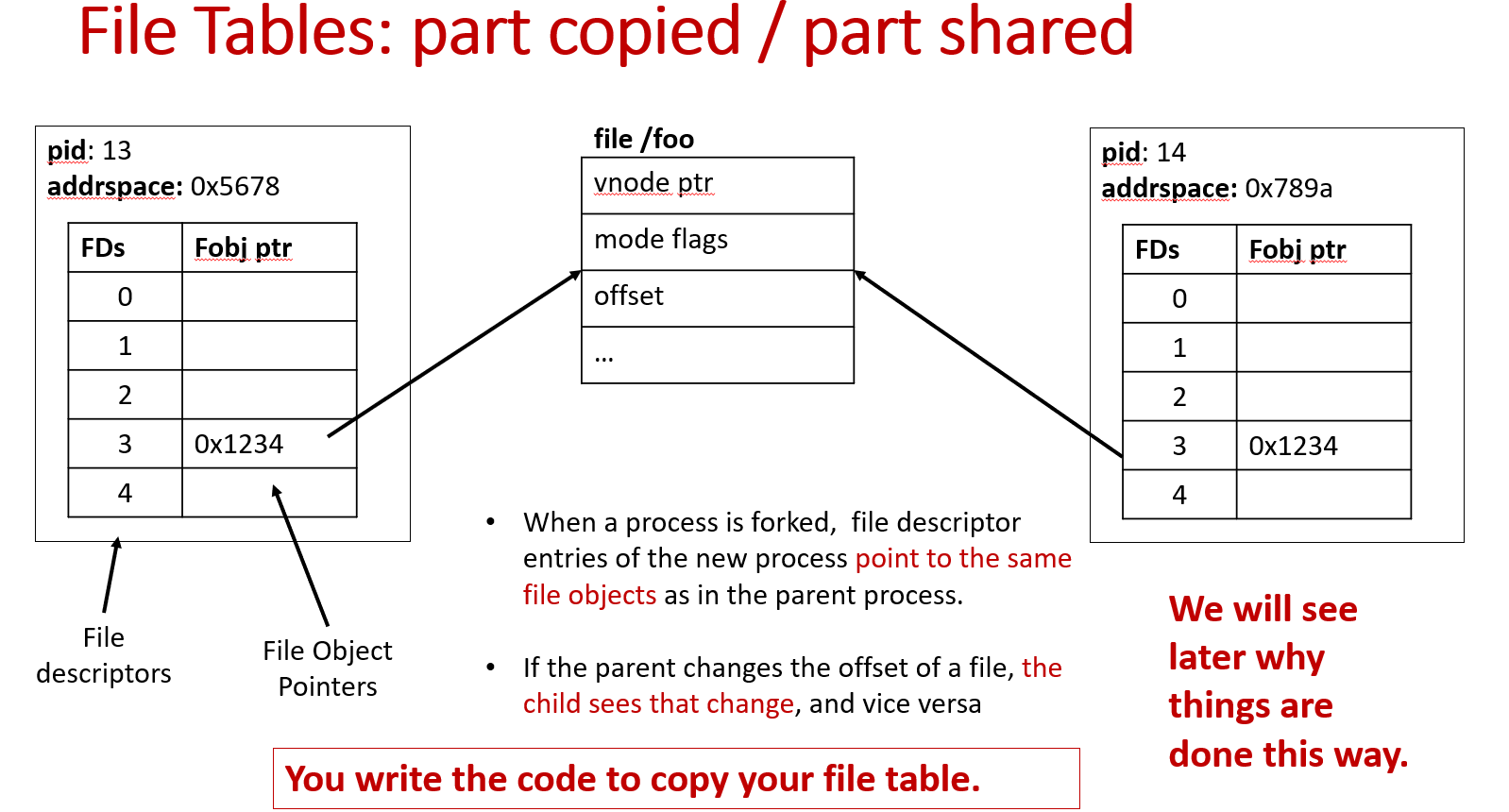
What kind of race conditions do you have to worry about?
Two processes simultaneously modifying the values of the offset.
Can you hold a spinlock while doing I/O?
Spinlocks turn off interrupts; I/O completion is signaled via an interrupt. If you turn off interrupts and then go do I/O, YOU WILL NEVER GET NOTIFIED!
Hold a regular lock? That will work. But do we have to hold the lock?
-- Not really. We can set up the uio struct with the right offset, release the lock, do the I/O, then acquire it again and update the offset if I/O was successful. Can’t update the offset prior to I/O completion – what if it fails?
- Copy architectural state(Copy and tweak
trapframe)
In the implementation of A5, you will have to make sure the right value is returned to the right process!
How will you need to modify the child's
trapframeto make sure that the child correctly returns to user mode?
Set the correct return value (0), signal no error, and advance to next instruction in the trapframe.
When do you need to copy the parent's
trapframe? Remember that as soon as the parent is returned from the system call, itstrapframewill be destroyed or modified!
Copy the parent's trapframe to child_tf before creating the kernel thread for the child process.
- Copy kernel thread(
thread_fork)
When you fork a new process, you fork a new kernel thread to provide to the child process.
To fork that thread, you need to provide it a function to run. You’ll need to write that function.
As mentioned above, thread_fork is used to fork a new kernel thread for the newly-forked process. enter_forked_process is provided to the newly-created thread.
You need to implement the enter_forked_process to modify the child process's trapframe and return to user mode:
- Return to user mode
- Both the parent and child return to user mode
The parent just returns from exception(mips_trap).
The child returns via the mips_usermode function.
How does a thread enter user mode for the first time?
mips_usermode in trap.c. This function shouldn't used by threads returning from traps - they should just return from mips_trap.
1 | |
It must replace the existing address space with a brand new one for the new executable (created by calling as_create in the current dumbvm system) and then run it.
While this is similar to starting a process straight out of the kernel (as runprogram() does), it's not quite that simple. Remember that this call is coming out of userspace, into the kernel, and then returning back to userspace. You must manage the memory that travels across these boundaries very carefully.
(Also, notice that runprogram() doesn't take an argument vector -- but this must of course be handled correctly in execv())
As you are replacing an old address space with a new one, you must not leak memory used by the old address space.
Carefully read the man page for execv() to understand the trickery in passing the potentially very large argument vector to/from userspace.
1 | |
sys_execv is responsible for:
• Replace the old address space with a new one
• Copy the arguments into the new address space
• Return to user mode
The mechanics of exec():

To think before starting exec():
Where are the arguments located when the exec system call in invoked? In whose address space? How do you know their address?
How do we get them into the kernel? How do you figure out their total size?
Where do the arguments need to end up before we return to the user mode? Whose address space? Stack or heap?
How do we get them there? How do we organize them there.
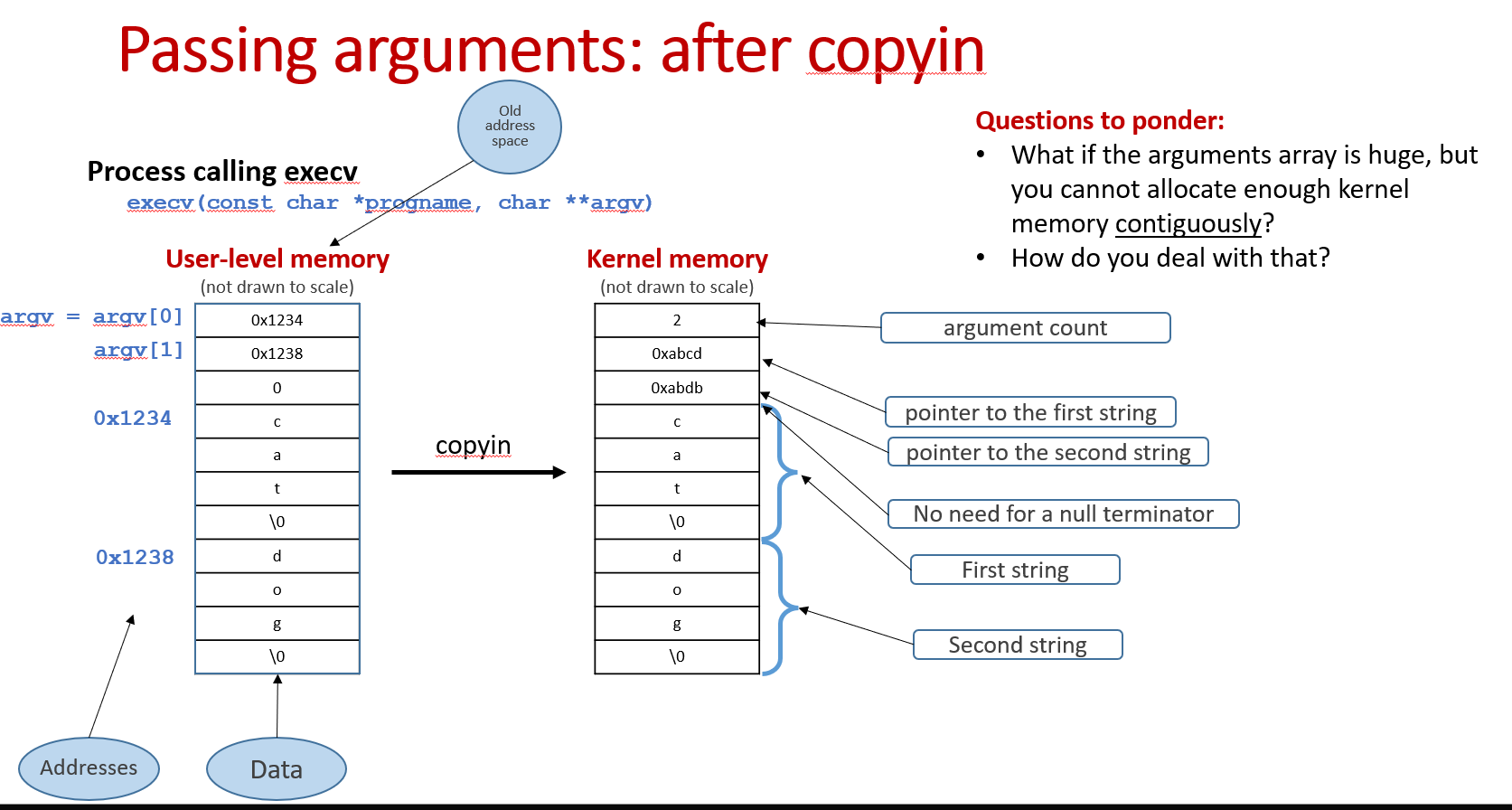
What if the arguments array is huge and you cannot allocate enough kernel memory contiguously?
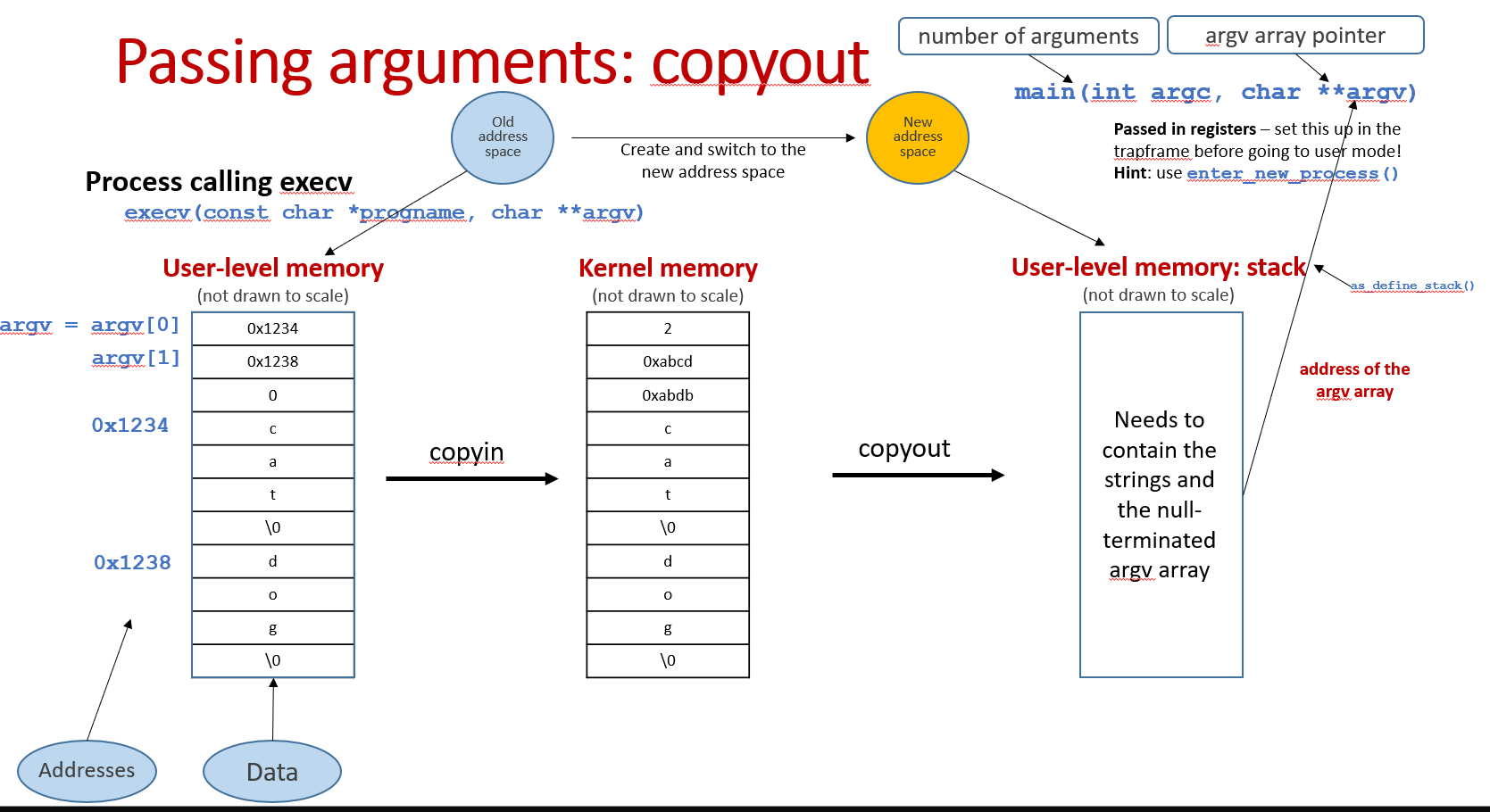
Passing arguments(copyin and copyout):
It's important to emphasize that we need to pass not only the arguments, but also the pointers to those arguments.
1 | |
Require a fair bit of design.
If a parent process exits before one or more of its children, it can no longer be expected collect their exit status. There are several ways to handle this case in practice, of which the traditional Unix method is only one. This is something you should design.
1 | |
Closely connected to the implementation of waitpid().
Most of the time, the code for _exit() will be simple and the code for waitpid() relatively complicated.
Error handling
If there are conditions that can happen that are not listed in the man page, return the most appropriate error code from kern/include/kern/errno.h.
Note that if you add an error code to src/kern/include/kern/errno.h, you need to add a corresponding error message to the file src/kern/include/kern/errmsg.h.
1 | |
Feel free to write kill_curthread() in as simple a manner as possible.
kill_curthread is similar to _exit, except that in kill_curthread, we need to signal the parent process that current process is dead. We only need to change the p_exitcode.
Plan your work
Implement fork first.
You will be able to test it using /testbin/forktest (set no wait to 1 in forktest.c if you would like to run it before waitpid is implemented)
You may first implement fork() with a very simple pid assignment scheme, and improve on it later as you are designing the rest of the system calls.
Test your code
- Testing using the shell
In user /bin/sh you will find a simple shell that will allow you to test your new system call interfaces.
You can exit the shell by typing "exit".
Before you run the shell, you need to put some synchronization code into common_prog()(in menu.c:114) to make sure that the menu thread is not trying to run concurrently with your shell and does not compete with it for the console input/output.
- Error handling
Use the devious /testbin/badcall (which you should now be able to invoke from a shell). At this point your system should not crash no matter what the user program does.
Even /testbin/forkbomb should not crash your kernel.
- Memory leaks
Your execv should properly dispose of the old address space (and any other old unneeded state) and returned the memory back to the system.
If a system call fails in the middle of execution (e.g., because of a bad pointer coming from user space) you must free up the resources allocated up to that point.
You can debug memory leaks by changing #undef LABELS to #define labels in vm/kmalloc.c and then invoking khdump from the kernel menu to examine the heap.
1 | |
You see that this command outputs a bunch of virtual addresses that were allocated via kmalloc and the corresponding addresses of code locations, where those items were allocated. To find out what these code locations are, you can use os161-addr2line (the OS/161 version of this standard Unix tool). For example, using an address from the example above:
1 | |
- How we will mark your code
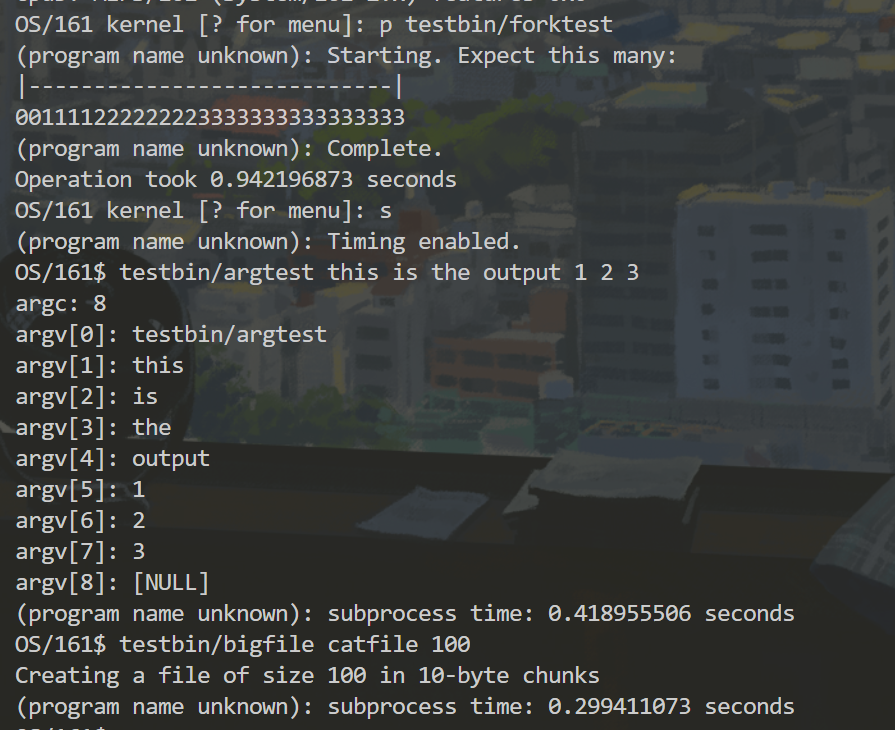
We will run a subset of the following tests on your kernel (all from /testbin)
1 | |
Forktest and argtest are the simplest test programs, so first make sure that your kernel runs those. Badcall and bigexec are the most challenging.
My Solution
I have revealed enough tips(secrets) above, more than enough for you to implement this assignment correctly! Please do not look at my solution below until you have finished coding! Otherwise, you will lose the joy of coding!
Now, I will dive deep down into my design and implementation. SPOIL (CODE) ALERT!
This assignment has 4 major parts:
- PID system
- Process creation(
fork) - Process wait and exit mechanism
- Program replacement(
execv)
PID system
First of all, we need to design our PID system that dynamically allocates and reclaims PID so that PID won't be used up as processes are created and destroyed.
Although the assignment handout suggest that we first implement a simple PID scheme before implementing fork and improve on it later when we try to implement more system calls, personally I prefer implementing the complete PID system before moving on.
My PID system design is rather simple. I maintain a global pid_table, with entries pid_entry. The index of the pid_table entry can be translated to pid. Since the index starts at 0 and the pid starts at PID_MIN(2), so index = pid - PID_MIN. I also use a next_pid variable to keep track of the next PID to try for allocation. Whenever we want to allocate a new PID, start trying from next_pid.
How do we know whether a pid is available? The pid_entry structure has a proc field. We simply examines whether pid_entry->proc == NULL. We free a pid by setting pid_entry->proc = NULL
I set kernel process's pid to PID_KERNEL(1) just for convenience sake, and user processes' pid begin at 2(PID_MIN).
1 | |
proc_remove_pid is called only during process cleanup to free the pid. Therefore, in my implementation, pid freeing is always called in company with process destruction. It is important to emphasize that pid should not be freed until the process is destroyed (not exits!).
pid_bootstrap needs to be called during initial boot sequence(early initialization) to indicate that all PIDs are available to use.
Lastly, don't forget to call pid_allocate in proc_create_fork and proc_create_runprogram.
The complete code of pid.h and pid.c:
1 | |
1 | |
Process creation(fork)
Once we have our PID system ready, we can implement our fork logic: creating a new process, which is the exact same copy of the original process. Review the sys_fork's responsibility above and understand what it should do.
Now let's break it down:
- Create a copy of the parent's
trapframeto provide to the newly-created kernel thread for use.
1 | |
- Create the child's
procstructurechild_proc
Remember that we need to create a new kernel thread to provide to the child process. Therefore, we first need to create the child's proc structure.
That's proc_create_fork's responsibility! In this function, we need to make the exact same copy of the parent process: copy the file table and allocate a new PID.
1 | |
You may be confused with the p_parent and p_children fields in the code above. Don't worry, I will explain why we need those fields in proc structure when I explain my process wait and exit mechanism.
In sys_fork, we call proc_create_fork to get the child proc:
1 | |
What's the difference between
proc_create_forkandproc_create_runprogram?
proc_create_fork is called by sys_fork. In proc_create_fork, we create a new process that is the copy of the current process. Therefore, we need to copy the file table and add the new process to the current process's children array. proc_create_runprogram is called by the kernel to create a new process for use by runprogram. It will have no address space and will inherit the current process's (the kernel menu's) current directory.
- Copy address space
Notice that in proc_create_fork, I didn't copy the parent's address space. I choose to do this in sys_fork after we get a child proc.
1 | |
- Create a new kernel thread
Remember that we need to create a new kernel thread to provide to the child process so that the child and the parent can return to user mode in their own way.
thread_fork is used to create a new thread to provide to the forked process. It needs to have an entrypoint where the new thread starts executing. Remember that the new thread needs to tweak trapframe to make sure the child has a different return value and return to user mode in a different manner than the parent. This function is performed by enter_forked_process.
1 | |
There we go! We find the entrypoint function for the new thread. Now it's time to implement enter_forked_process:
- Copy the child's
trapframeto our kernel stack from the heap. - Tweak the child's
trapframe - Activate child process's address space
- Enter user mode
1 | |
Have you thought about why we need the trouble to first copy parent's
trapframeonto the heap and then copy it to the kernel stack from the heap?
Because parent's trapframe is on its stack and will be destroyed as soon as it returns from trap. In the mean time, our newly-created kernel thread run concurrently and may lose the trapframe if the parent returns from trap too early. That's why we need to save a copy of the trapframe on the heap before the parent returns.
- Parent returns from trap
While the child returns via the mips_usermode function in its own kernel thread. The parent just returns from trap(mips_trap) with the return value of its child's PID.
1 | |
The complete code of sys_fork:
1 | |
Process wait and exit mechanism
This assignment gives us the freedom to design the process wait and exit mechanism. The assignment handout says:
Most of the time, the code for
_exit()will be simple and the code forwaitpid()relatively complicated.
However, my design requires a more complex _exit than waitpid. Maybe it is not the best design, but it is a working design!
Now let's break down my design:
The crux of the problem:
- When should the process be cleaned up?
- How to implement the mechanism for the parent process to wait for its child to exit?
- How to kill a process when it encounters an error.
- Process cleanup mechanism
The main problem is that when a process exits, it should not be cleaned up right away. Instead, it should become zombie until its parent process call waitpid to collect its exit code.
Therefore, my first thought is to clean up the child process as soon as its parent collects its exit code.
However, that bring us a new problem:
What if the parent process never calls
waitpidbefore it exits? Or the parent exits before its child exits? How to prevent itszombiechild from hanging forever?
My solution to this problem is to delay the child process's cleanup until the parent process exits. That is to say, when a process exits, it should traverse all of its children, clean up zombie children( exit code already be collected) and make running children(haven't yet exited) become orphans. Those orphan processes would be cleaned up right away as soon as they exits(skip the process of becoming zombies).
After handling its children, the process should check if itself is orphaned. If so, just clean itself up(in thread_exit. If not, signal its parent and becomes zombie.
1 | |
Now this explains why I maintain a p_parent and p_children field in proc structure.
The flow chart below shows the normal life of a process:
1 | |
The complete code of sys__exit:
1 | |
- Process wait mechanism
waitpid is called by the parent process to wait for its child process to exit. When the child process exits, it signals its parent. My design is to let the parent process wait on its child's condition variable. When the child exits, it wakes up the parent.
1 | |
1 | |
Special case: recall that in my process cleanup mechanism, we clean up zombie children when the parent process exits. But if current process is the kernel process, it does not exit. Therefore, we need to clean up its child right after it collects its child's exit code in waitpid.
As in fact, the kernel does need to wait for its child to exit in OS/161 and we need to implement that logic:
In OS/161, the kernel thread, (or menu thread), after it gets command arguments from the command line, it goes into common_prog. In common_prog, it creates a new thread to provide to the new program. We need to make it wait for the subprogram to finish(exit) before allowing it to return to menu.
1 | |
The complete code of sys_waitpid:
1 | |
- Kill a process
When a user process hits a fatal fault, we need to kill it. But instead of crashing the entire kernel, we need to signal parent of its death and clean it up neatly.
This is very much like normal _exit, except that we need to set exit code to signal death.
1 | |
The complete code of kill_curthread:
1 | |
Program replacement(execv)
We often needs to replace the currently executing program, (probably in a newly-forked process) with a newly-loaded program image(with completely new address space and executable).
That's the job of execv! This is also the most tricky system call we need to implement in the entire OS/161. Review the sys_execv's responsibility above and understand what it should do.
I break it down into 4 parts:
Copyinthe arguments from the old address space- Load the new program image
Copyoutthe arguments into the new address space- Clean the old address space and return
Copyin and Copyout arguments are the most tricky parts, you can really mess up with those pointers! It is important to emphasize it again that we need to pass both the arguments(strings) and the pointers pointing to those arguments(strings).

Copyinarguments from user space
It's important to emphasize that we need to pass not only the arguments, but also the pointers to those arguments.
First of all, I've defined two variables. kargbuf stores arguments(strings) in contiguous space(each individual string is stored in 4-bytes aligned address) and kargs stores the pointers array, pointing to individual strings in kargbuf.
1 | |
Next, we need to know the number of arguments(strings) and the total bytes needed for strings, so that we can reserve space on the kernel heap to incept them.
- Number of arguments(strings)
1 | |
After we know the number of arguments(strings) and reserve the space for kargs, we copy the array of argument pointers from user space to kargs:
1 | |
Note that now the karg array store the pointers pointing to user address space. After we copy the arguments(strings) into the kernel, we need to make those pointers pointing to the arguments inside the kernel.
- Total bytes for arguments(strings)
1 | |
After we know the total bytes needed for arguments(strings) and reserve space for kargbuf, we copy the arguments(strings) into kargbuf and make pointers in kargs pointing to the new locations(in kernel) of the arguments.
1 | |
- Load the new program image
- Create and switch to the new address space
1 | |
- Open and load the new executable
1 | |
- Define a new stack region
1 | |
Copyoutarguments to user stack
How to copy the arguments to the new address space?
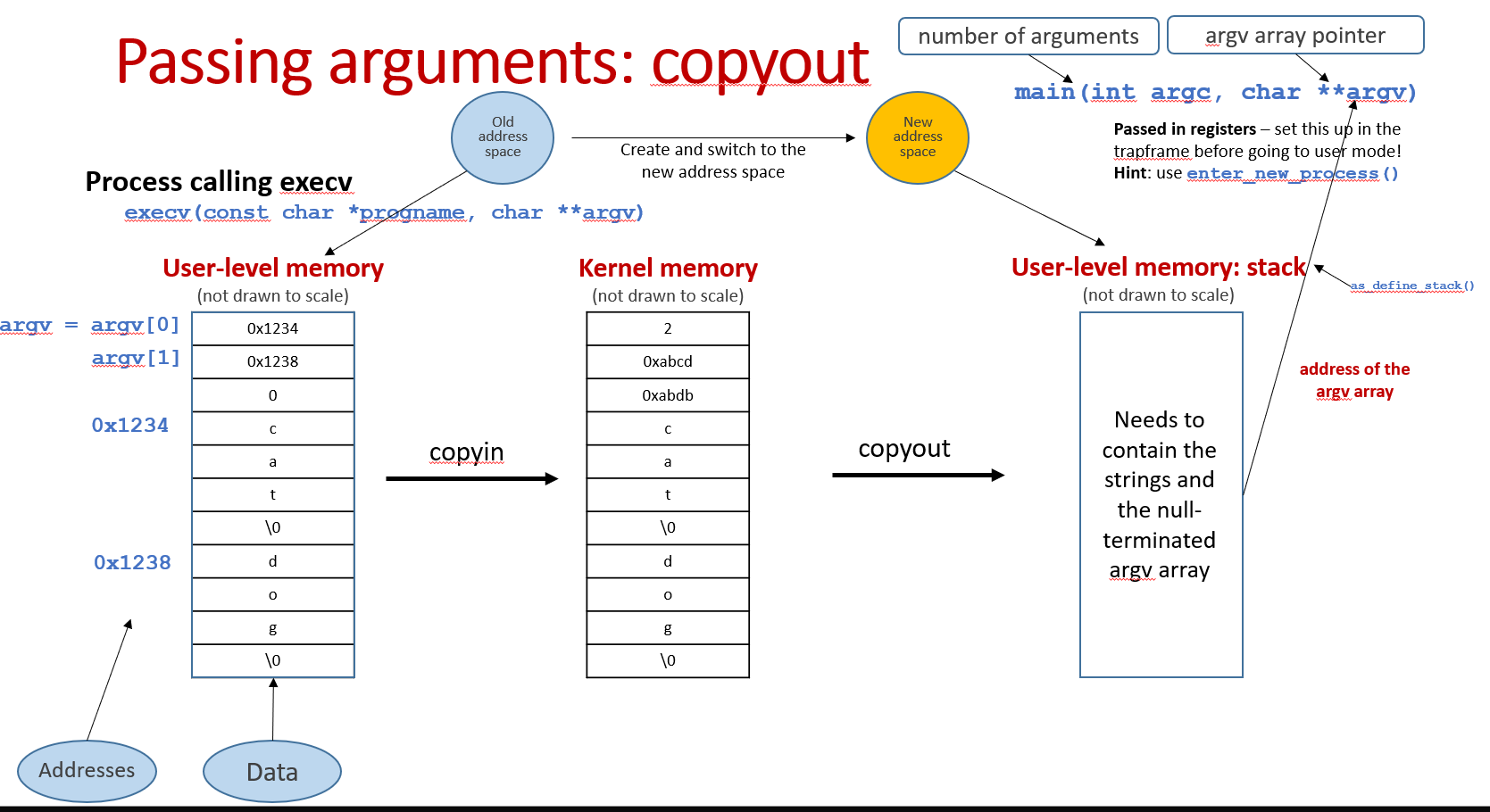
We first obtain the initial stackptr via as_define_stack.
Next we calculate where the strings should begin:
1 | |
Then copy the strings starting at stackptr(strings_start) and save the new user space address of the strings in kargs.
1 | |
Why do we need to save the strings' user space address?
After we copy the strings to user space address, we also need to copy the pointers to those strings.
We first calculate where the pointers should begin. Note that the pointers should store below the strings, as the stack grows in the direction of low address.
1 | |
Then we copy the pointers (to the strings) starting at stackptr(This is also the final stackptr we need to pass to enter_new_process in order to enter user mode):
1 | |
This is the overview of user stack before we enter user mode:

- Clean the old address space and return to user mode
1 | |
Finish!
Those are the files I have modified/created. Do not get here unless you are stuck in coding!
1 | |
We have passed all tests in Assignment5!
1 | |
We have finished Assignment5!😊