In this part, we will introduce the concepts of synchronization, some hardware support for synchronization, and some synchronization primitives/objects. This part is crucial for you to implementing OS161 Assignment 2&3 correctly!
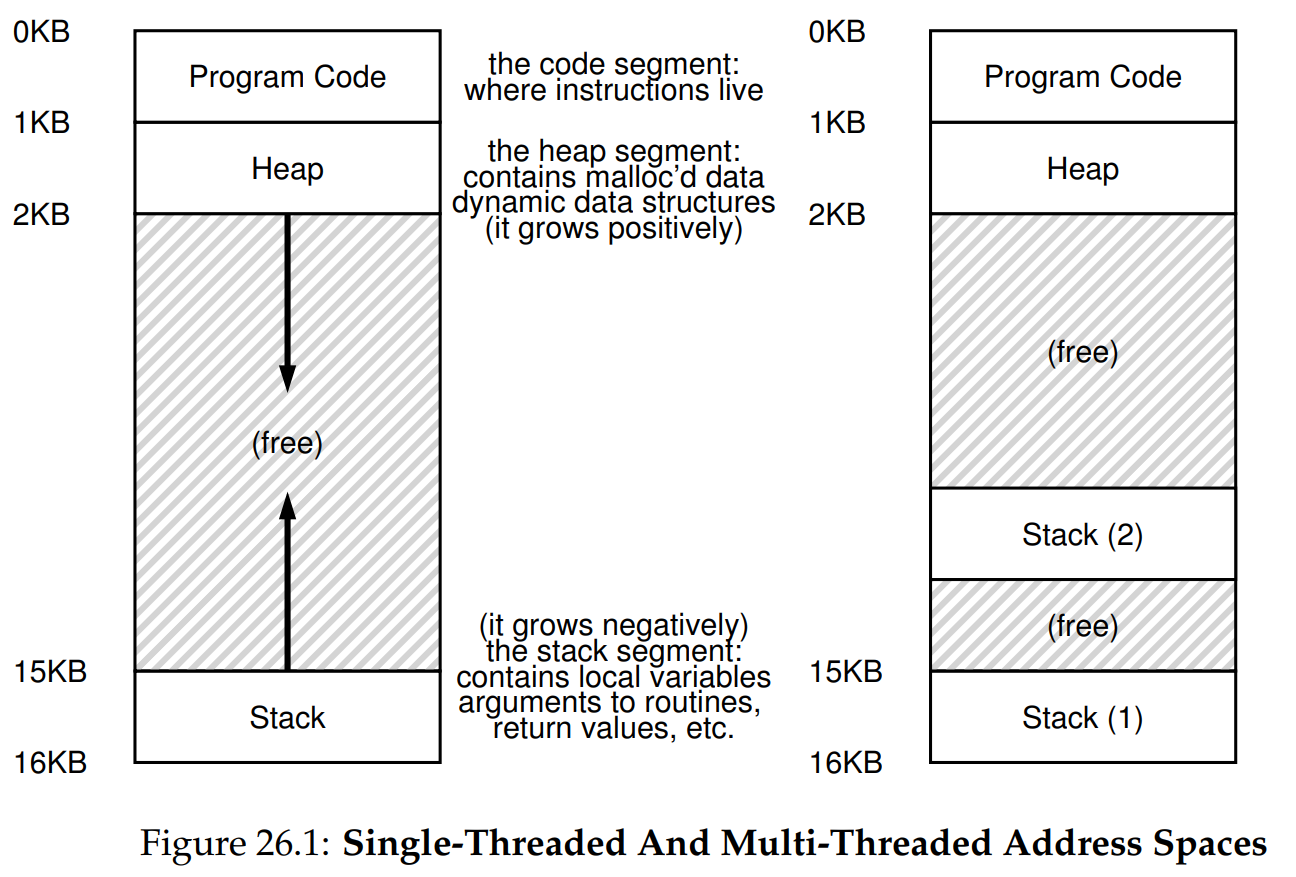
All threads within the same process share the same virtual address space and file descriptor table, but each thread has its own set of registers and stack.
Synchronization
Sometimes multiple threads need to access and operate on shared resources. Synchronization provides mutual exclusion between threads.
Why we do we need synchronization?
If two or more threads concurrently access an object, and at least one of the accesses is a write, a race condition can occur and synchronization is required.
Mutual Exclusion
mutex:
1 2 3 4 5 6 7 8 9
std::mutex mutex;
voidthreadfunc(unsigned* x) { for (int i = 0; i != 10000000; ++i) { mutex.lock(); *x += 1; mutex.unlock(); } }
spinlock:
spinlock.swap() is one atomic step stores the specified value to the atomic spinlock variable and returns the old value of the variable.
1 2 3 4 5 6 7 8 9 10 11
structmutex { std::atomic spinlock;
voidlock() { while (spinlock.swap(1) == 1) {} }
voidunlock() { spinlock.store(0); } };
Critical Section
The mutual exclusion policy is enforced in the code region between the lock() and unlock() invocations. We call this region the critical section.
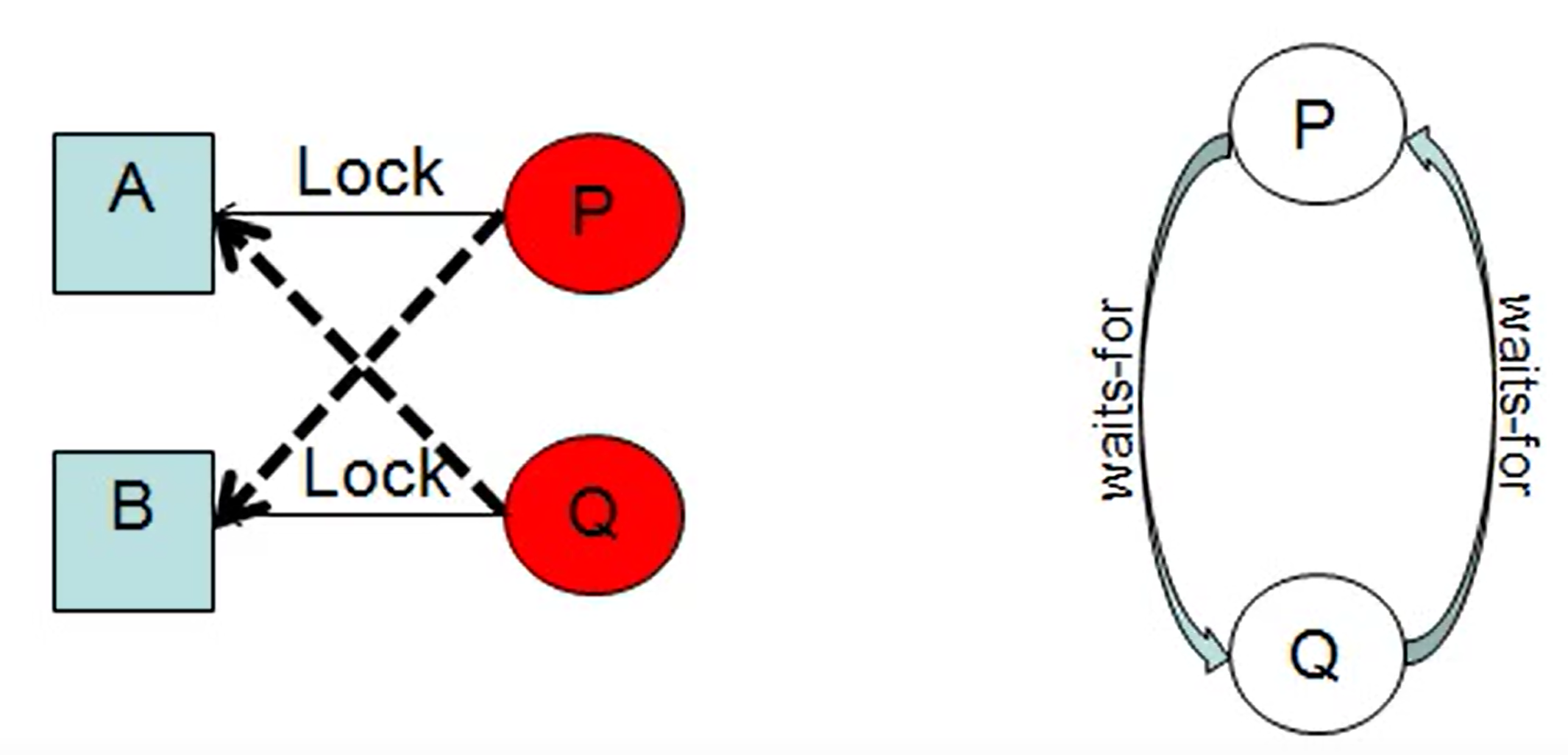
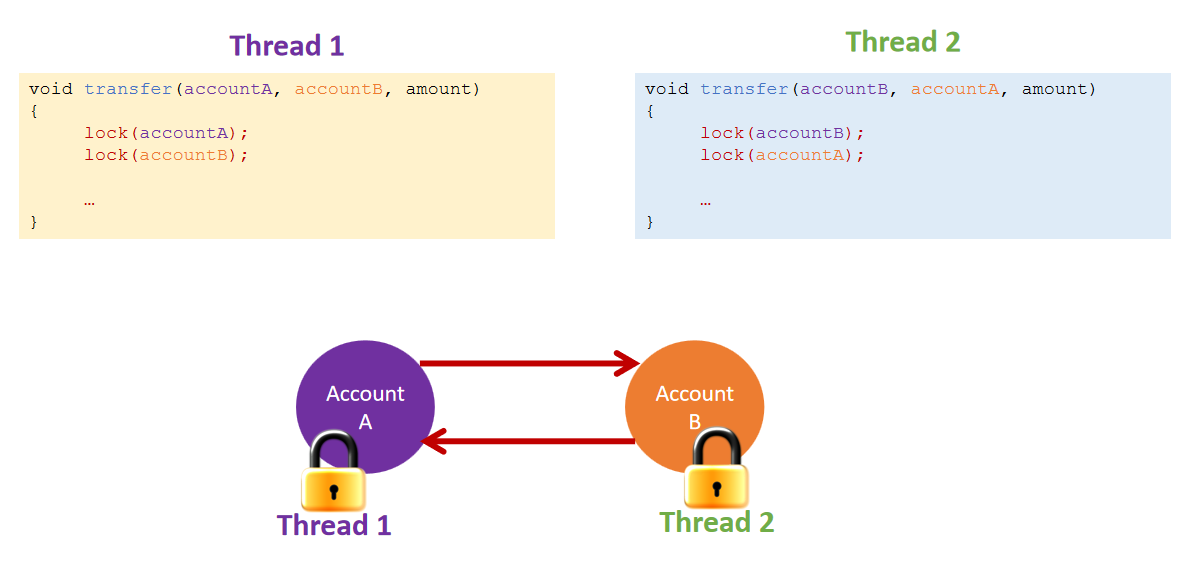
Deadlock
Hardware Support
Hardware Primitives
In this part, we will introduce some hardware primitives that use atomic instructions to achieve mutual exclusion. Atomic instructions are the hardware basis for implementing synchronization.
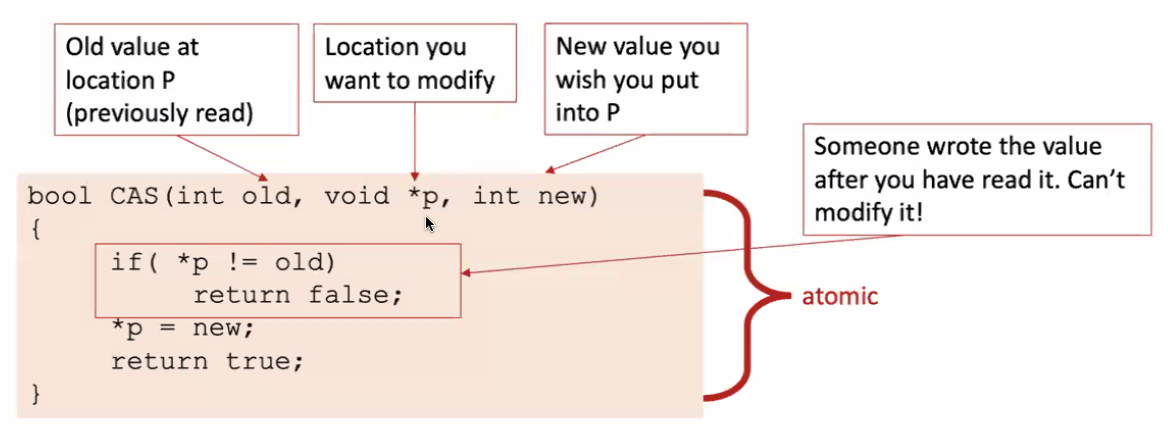
CAS(Compare and Swap)
old is the value we assume *p would be. If they are not the same, it means someone else sneak in and change the *p, so we need to abort and try again
Hardware implementation: Compare the contents of a memory location with a value; If they are the same, modify the memory location to a new value.
1 2 3
Set Compare Value Application Register to 0 cpmxchg loc, 1 if ZF == 1 //The compare was true and you have the lock!
example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
intwithdraw(account, amount) { bool success = false; while(!success) { balance = get_balance(account); new_balance = balance - amount; /* * If balance has been changed by another thread, * just try again. */ success = CAS(balance, &account->balance, new_balance); } return balance; }
typical use of CAS:
implement locks
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
bool lockObtained = false; int locked;
retry: /* Spin while the lock looks taken */ while(lock->locked) ;
/* Read the state of the lock */ locked = lock->locked; /* If it is locked, try again */ if(locked) goto retry;
/* Try to get the lock */ lockObtained = CAS(locked, &lock->locked, 1);
/* If we could not get the lock, try again */ if(! lockObtained) goto retry;
update shared counters
1 2 3 4 5 6
bool success = false;
while(!success) { int old_val = counter;
success = CAS(old_val, &counter, old_val + 1);
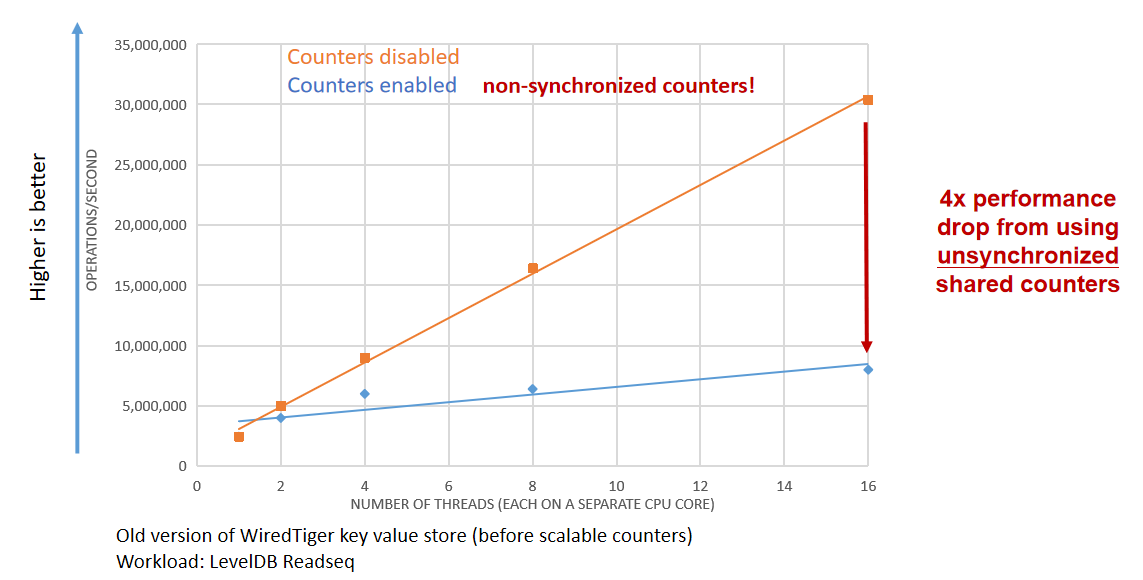
Why performance drop using non-synchronized counters?
coherency protocol (Hardware does synchronization anyway!):
Every core has its own private cache. If a copy of the same memory location happens to live in caches of other cores, the hardware will make sure that these copies have consistent values. So it will send messages to other caches to either invalidate the old copy or to forward the new value.
Writes to the shared counter cause invalidations in hardware caches. Invalidations clog the system bus and delay instructions. Hardware synchronization is very expensive!
Test-and-set(TAS)
TAS on Intel:
1 2 3
src = 1 xchg lock_var, src //exchange the value if (src == 0) //You got the lock!
We will talk more about TAS when we learn the implementation of spinlock.
LL/SC(load link & store conditional)
SC only succeeds if the location hasn't changed since the last LL.
LL/SC on MIPS:
1 2 3 4 5 6 7
//r1 contains address of the spinlock LL r2, (r1) //Load value referenced by r1 into r2 if r2 is 0 (unlocked) SC r3, (r1) //Store "locked" into location referenced by r1 //r3 contains 0 on failure if (r2 != 0 || r3 is 0) goto retry
Volatile keyword
A variable should be declared volatile whenever its value could change unexpectedly:
Memory-mapped peripheral registers
Global variables modified by an interrupt service routine
Global variables accessed by multiple tasks within a multi-threaded application
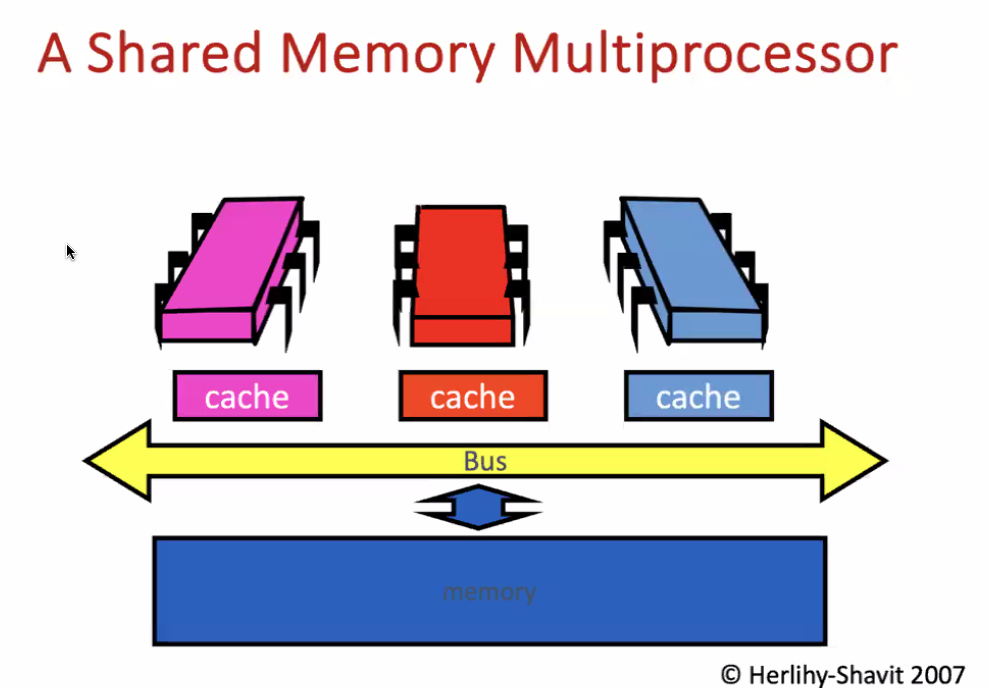
Cache
Multiprocessor
Each core has its own cache:
cache miss
Every core has its own private cache.
When a processor reads from an address in memory, it first checks whether that address and its contents are present in its cache. If so, then the processor has a cache hit. If not, then it has a cache miss.
cache miss: When a cache got the data, but was invalidated by another cache.
Exercise:
Solution:
Data Race
Why hardware optimization (cache) may cause problems?
Real machines and compilers sometimes result in non-sequentially-consistent executions:
The blue thread's write to done may be saved in its cache first.
In some architectures, the blue thread’s write to done may become visible to the red thread, running on another core, before the blue thread’s write to x.
Synchronization Variables avoid locking overhead, which is expensive.
e.g.
1 2 3 4 5
std::atomic<int> counter(0); // atomic counter
// Multiple threads can operate on counter safely counter++; // atomic operation counter += 5; // atomic operation
Synchronization variables are difficult to use for complex data structures, since there is no easy way to make multiple updates to a data structure in one atomic operation
Wait Channels
An abstraction that lets a thread wait on a certain event.
Includes a lock and a queue.
Synchronization Objects
Synchronization objects are types whose methods can be used to achieve synchronization and atomicity on normal (non-std::atomic-wrapped) objects.
Lock
A regular lock puts a thread to sleep and triggers context switch when someone else has already acquired the lock.
mutex:
1 2 3 4 5 6 7 8 9
std::mutex mutex;
voidthreadfunc(unsigned* x){ for (int i = 0; i != 10000000; ++i) { mutex.lock(); *x += 1; mutex.unlock(); } }
Lock-based Concurrent Data Structures
How to add to locks to data structures?
Concurrent Counters
Basic Counting
Simply add a lock for the counter structure.
Scalable Counting
Each CPU has its own local counter and there is a global counter.
Once a local counter reaches threshold S, it updates the global counter.
typedefstruct __counter_t { int global; // global counter pthread_mutex_t glock; // global lock int local[NUMCPUS]; // per-CPU local counter pthread_mutex_t llock[NUMCPUS]; // local locks int threshold; // threshold } counter_t;
// init: record threshold, init locks, init values // of all local counts and global count voidinit(counter_t *c, int threshold) { c->threshold = threshold; c->global = 0; pthread_mutex_init(&c->glock, NULL); int i; for (i = 0; i < NUMCPUS; i++) { c->local[i] = 0; pthread_mutex_init(&c->llock[i], NULL); } }
// update: usually, just grab local lock and update // local amount; once it has risen ’threshold’, // grab global lock and transfer local values to it voidupdate(counter_t *c, int threadID, int amt) { //which cpu is the thread on is determined by its thread ID int cpu = threadID % NUMCPUS; //acquire the local lock pthread_mutex_lock(&c->llock[cpu]); c->local[cpu] += amt; if (c->local[cpu] >= c->threshold) { // transfer to global (assumes amt>0) pthread_mutex_lock(&c->glock); c->global += c->local[cpu]; pthread_mutex_unlock(&c->glock); c->local[cpu] = 0; } pthread_mutex_unlock(&c->llock[cpu]); }s
// get: just return global amount (approximate) intget(counter_t *c) { pthread_mutex_lock(&c->glock); int val = c->global; pthread_mutex_unlock(&c->glock); return val; // only approximate! }
More concurrency(more locks) isn't necessarily faster!
Hash table has far better performance than simply a linked list!
Spinlock
A regular lock puts a thread to sleep and triggers context switch when someone else has already acquired the lock. While a spinlock avoids context switch by keeping the CPU busy testing if the lock becomes available continuously.
Why spinlock implementation in os161 does both disabling interrupts and spinning
Disabling interrupts when acquiring the spinlock prevents the CPU from switching to another thread which may tries to acquire the same spinlock, potentially causing a deadlock.
That is to say, when a CPU is holding the spinlock, we don't want it to switch to another thread. When the current thread releases the spinlock, we can re-enable interrupts.
Therefore, we can say spinlock is held by CPU.
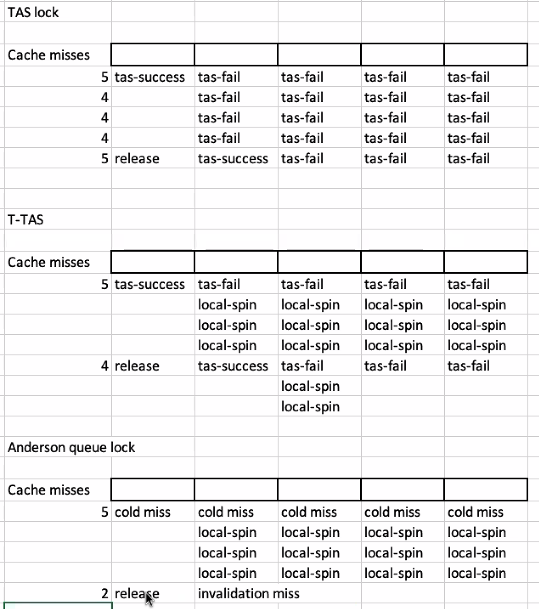
Test-and-Set locks in-depth
How can we improve the performance of spinlock?
TAS(test-and-set)
1 2 3 4 5 6 7 8 9
publicclassTASLockimplementsLock { AtomicBooleanstate=newAtomicBoolean(false); publicvoidlock() { while (state.getAndSet(true)) {} // spin while true } publicvoidunlock() { state.set(false); } }
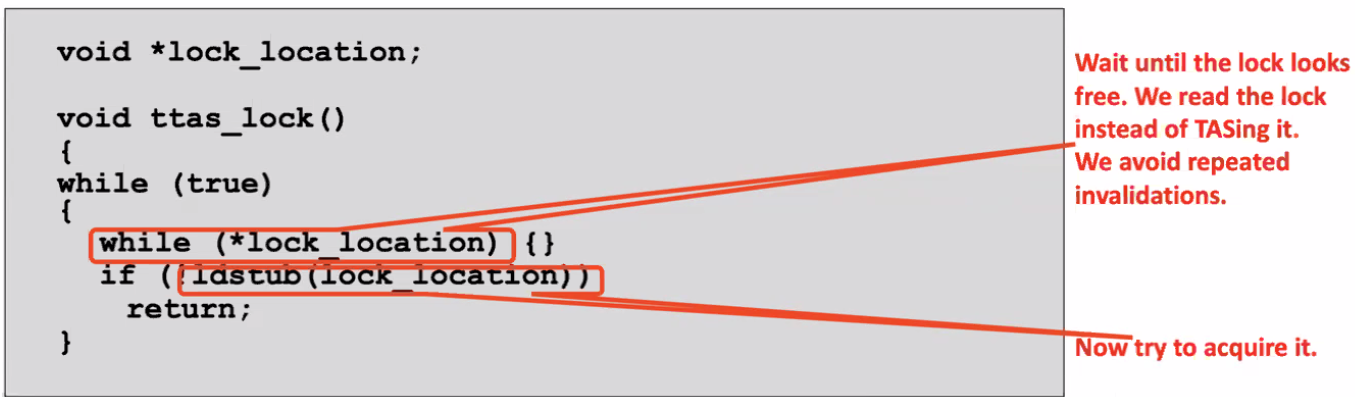
TTAS(test-test-and-set)
Can we further optimize spinning?
Yes, since test-and-set is expensive, we can test-and-test-and-set!
1 2 3 4 5 6 7 8
voidacquire(lock) { retry: while(lock->held) //test first ; //spin if(test_and_set(&lock->held)) //test and set goto retry; //lock not acquired }
When someone releases the lock, that core will send the invalidation message, and other threads will know the lock is freed and try to acquire it.
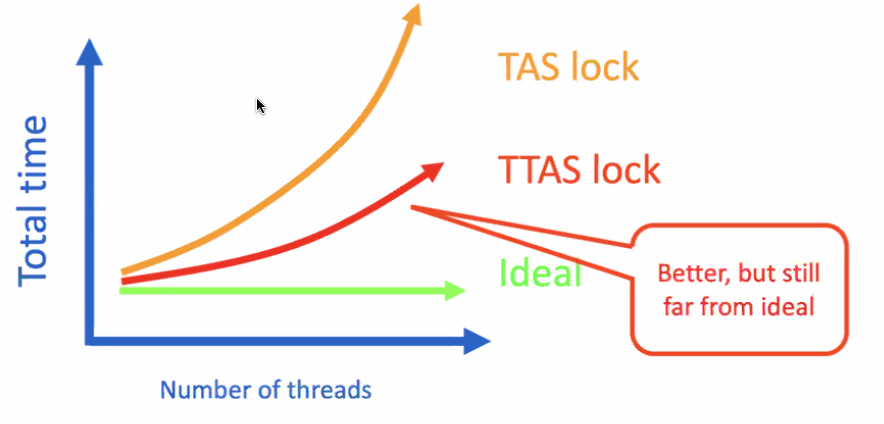
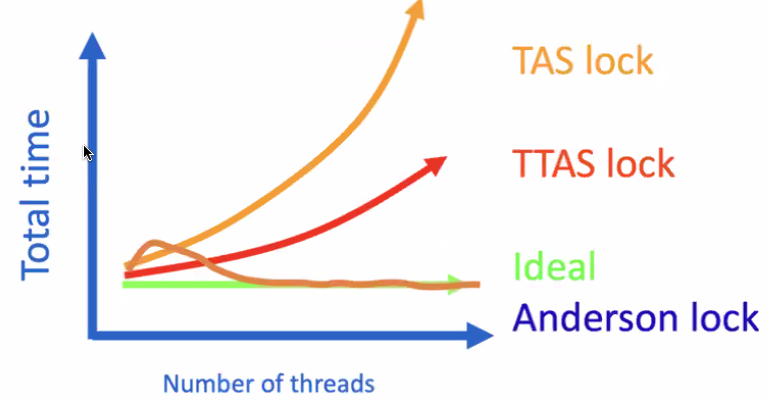
Performance:
Why still not ideal?
When a lock is released, everyone tries to acquire it. Everyone is trying to load the data from the cache, although only one thread can actually acquire the lock. i.e. invalidation message will be sent to multiple threads.
How can we avoid this waste?
A solution: TTAS Lock with Backoff
For a specific thread,
If I fail to get the lock there must be contention
So I should back off before trying again(no need to try again immediately)
Introduce a random “sleep” delay before trying to acquire the lock again
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
voidttas_lock(TTASLock *lock) { while (1) { // First test: wait until lock seems available (flag is clear) while (lock->flag) { // Lock is busy. Wait and retry. } // Second test: Try to set the flag if (!atomic_flag_test_and_set(&lock->flag)) { // Acquired the lock return; } else { // Contention occurred, // back off before trying again backoff(); } } }
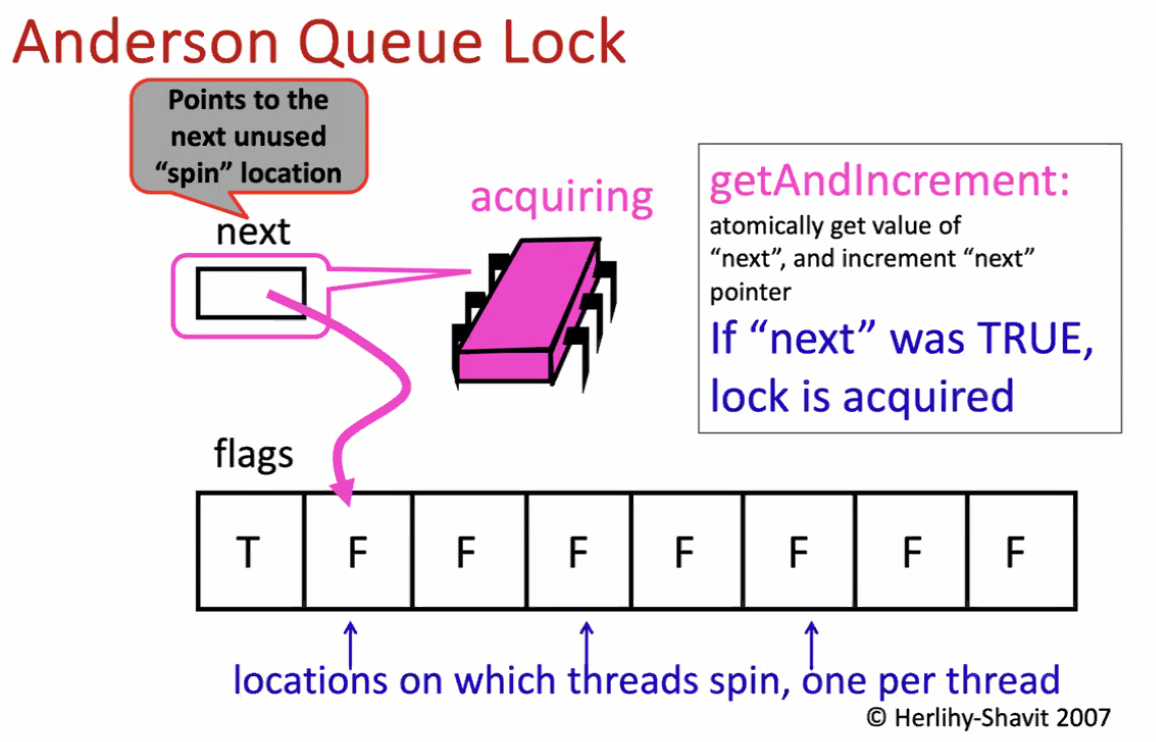
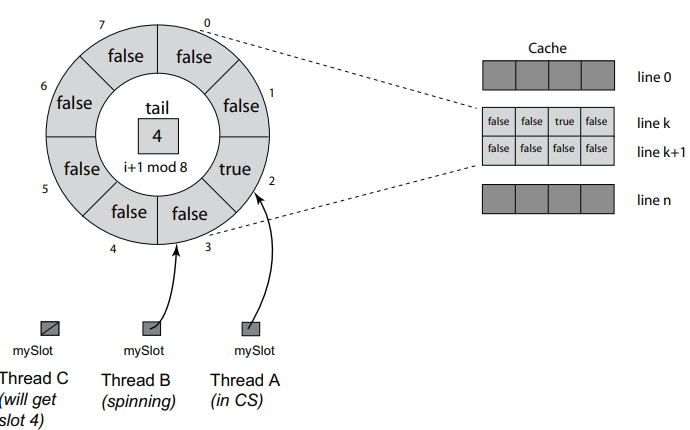
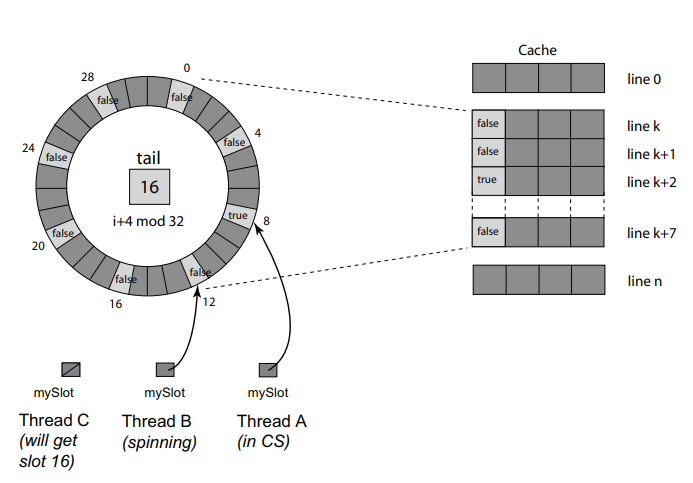
Anderson Queue Lock
Each thread spins on its own location.
We only need to send invalidation message to the next thread.
structsemaphore { char *name; volatileint count; volatileint tas; //the protection of count, meaning that if a thread holds the test-and-set, no other threads can modify the count. Obviously, holding the test-and-set operation should be atomic, namely (TAS(sem->tas) != 0) }
V(struct semaphore *sem) { int spl;
spl = splhigh(); while(TAS(sem->tas != 0)); //Only break when sem->tas = 0 and we set it to 1, meaning that the thread holds the test-and-set on the semaphore sem->count++; sem->tas = 0; //release the test-and-set thread_wakeup(sem); splx(spl); }
P(struct semaphore *sem) { int spl; spl = splhigh(); //make sure to disable interrupt when we use test-and-set while(1) { while(TAS(sem->tas) != 0); //Only break when sem->tas = 0 and we set it to 1, meaning that the thread holds the test-and-set on the semaphore if (sem->count > 0) break; sem->tas = 0; //release the test-and-set; thread_sleep(sem); } sem->count--; sem->tas = 0; splx(spl); return; }
Serious problem! Wake-up Loss!
==OS/161 Solution:==
How do we solve the problem of wake-up loss?
The wait channel should be locked when a thread wants to go to sleep.
The sleep operation should release the wait channel lock after go to sleep.
The wakeup operation should acquire the wait channel lock first. If the channel is locked, it means someone is trying to go to sleep, so the wakeup operation should block.
sem->sem_count++; KASSERT(sem->sem_count > 0); wchan_wakeone(sem->sem_wchan); //require the wait channel lock
spinlock_release(&sem->sem_lock); }
voidP(struct semaphore *sem) { KASSERT(sem != NULL); KASSERT(curthread->t_in_interrupt == false); //make sure current thread is not in an interrupt context spinlock_acquire(&sem->sem_lock); while(sem->sem_count == 0) { wchan_lock(sem->sem_wchan); //obtain the lock on the wait channel, preventing other threads(V operation) coming in and manipulating the queue(wake up someone) spinlock_release(&sem->sem_lock); //lock the wait channel before release the sem_lock, making sure nobody can sneak in and take the sem_lock to manipulate the wait channel before we go to sleep(for example, V can sneak in and wake up other threads since the wait channel has not been locked.) wchan_sleep(sem->sem_wchan); //go to sleep while also release the wait channel lock
A condition variable is always paired with one single lock
Three methods:
cv_wait: block until the condition becomes true(atomically release the lock and go to sleep waiting to be waken)
cv_broadcast: wake all threads waiting on this condition variable
cv_signal: wake a single thread waiting on this condition variable
These three methods support the Waiting and Signaling mechanism of CV.
Waiting and Signaling
pthread_cond_wait() blocks the calling thread until the specified condition is signaled. This routine should be called while mutex is locked, and it will automatically release the mutex while it waits.
After signal is received and thread is awakened, mutex will be automatically locked for use by the thread.
When the thread finishes, unlock the lock explicitly.
1 2 3 4 5 6 7
// lock the mutex ...
//when condition is reached, call signal() signal();
// unlock the mutex to allow a matching wait routine to complete
Hold the lock when calling wait! (wait will release the lock before going to sleep and reacquire the lock before returning!)
Always hold the lock while signaling!(not mandatory)
Mesa Semantics: Always use while loop to check the waited condition.
1 2 3 4 5 6 7 8
// lock the mutex ...
while (check the condition) { wait(); //wait on the condition variable } //wait will automatically and automically release the lock
// After being awakened, mutex will be automatically locked
void *producer(void *arg) { int i = 0; while (1) { pthread_mutex_lock(&mutex);
// Buffer is full, wait for consumer while (count == BUFFER_SIZE) { //wait on the condition variable cond_produce //automically release the mutex, and relock it before returning pthread_cond_wait(&cond_produce, &mutex); //After waking up, we need to check the condition again as mesa semantics makes no guarantee. }
// Produce an item buffer[count] = i; printf("Produced: %d\n", i); count++; i++;
// Signal consumer that an item is produced // atomic action pthread_cond_signal(&cond_consume); //After signal, remember to release the lock explicitly! pthread_mutex_unlock(&mutex);
sleep(1); // Simulate time to produce } returnNULL; }
void *consumer(void *arg) { while (1) { pthread_mutex_lock(&mutex);
// If buffer is empty, wait for producer while (count == 0) { //wait on the condition variable cond_consume, and automically release the mutex pthread_cond_wait(&cond_consume, &mutex); //When being awaken, mutex will be automatically locked. }
// Consume an item count--; int item = buffer[count]; printf("Consumed: %d\n", item);
// Signal producer that an item is consumed // atomic action pthread_cond_signal(&cond_produce); //After signal, remember to release the lock explicitly! pthread_mutex_unlock(&mutex);
sleep(1); // Simulate time to consume } returnNULL; }